 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANLS* -- A Universal Document Processing Metric for Generative Large Language Models
Feb 06, 2024



Traditionally, discriminative models have been the predominant choice for tasks like document classification and information extraction. These models make predictions that fall into a limited number of predefined classes, facilitating a binary true or false evaluation and enabling the direct calculation of metrics such as the F1 score. However, recent advancements in generative large language models (GLLMs) have prompted a shift in the field due to their enhanced zero-shot capabilities, which eliminate the need for a downstream dataset and computationally expensive fine-tuning. However, evaluating GLLMs presents a challenge as the binary true or false evaluation used for discriminative models is not applicable to the predictions made by GLLMs. This paper introduces a new metric for generative models called ANLS* for evaluating a wide variety of tasks, including information extraction and classification tasks. The ANLS* metric extends existing ANLS metrics as a drop-in-replacement and is still compatible with previously reported ANLS scores. An evaluation of 7 different datasets and 3 different GLLMs using the ANLS* metric is also provided, demonstrating the importance of the proposed metric. We also benchmark a novel approach to generate prompts for documents, called SFT, against other prompting techniques such as LATIN. In 15 out of 21 cases, SFT outperforms other techniques and improves the state-of-the-art, sometimes by as much as $15$ percentage points. Sources are available at https://github.com/deepopinion/anls_star_metric
Affordance detection with Dynamic-Tree Capsule Networks
Nov 09, 2022



Affordance detection from visual input is a fundamental step in autonomous robotic manipulation. Existing solutions to the problem of affordance detection rely on convolutional neural networks. However, these networks do not consider the spatial arrangement of the input data and miss parts-to-whole relationships. Therefore, they fall short when confronted with novel, previously unseen object instances or new viewpoints. One solution to overcome such limitations can be to resort to capsule networks. In this paper, we introduce the first affordance detection network based on dynamic tree-structured capsules for sparse 3D point clouds. We show that our capsule-based network outperforms current state-of-the-art models on viewpoint invariance and parts-segmentation of new object instances through a novel dataset we only used for evaluation and it is publicly available from github.com/gipfelen/DTCG-Net. In the experimental evaluation we will show that our algorithm is superior to current affordance detection methods when faced with grasping previously unseen objects thanks to our Capsule Network enforcing a parts-to-whole representation.
Improving the Trainability of Deep Neural Networks through Layerwise Batch-Entropy Regularization
Aug 01, 2022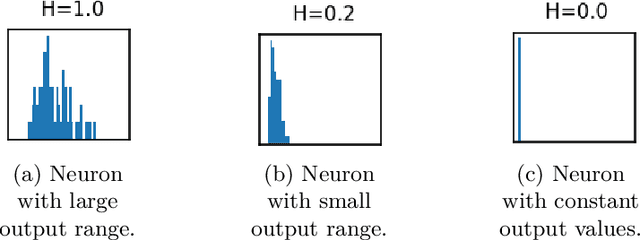
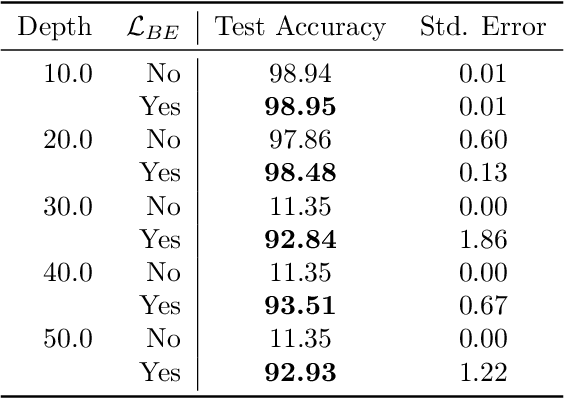
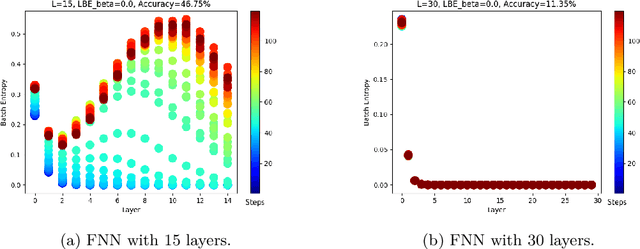
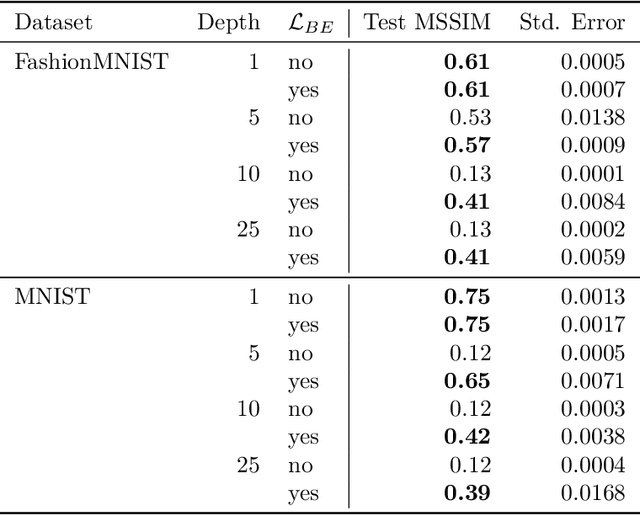
Training deep neural networks is a very demanding task, especially challenging is how to adapt architectures to improve the performance of trained models. We can find that sometimes, shallow networks generalize better than deep networks, and the addition of more layers results in higher training and test errors. The deep residual learning framework addresses this degradation problem by adding skip connections to several neural network layers. It would at first seem counter-intuitive that such skip connections are needed to train deep networks successfully as the expressivity of a network would grow exponentially with depth. In this paper, we first analyze the flow of information through neural networks. We introduce and evaluate the batch-entropy which quantifies the flow of information through each layer of a neural network. We prove empirically and theoretically that a positive batch-entropy is required for gradient descent-based training approaches to optimize a given loss function successfully. Based on those insights, we introduce batch-entropy regularization to enable gradient descent-based training algorithms to optimize the flow of information through each hidden layer individually. With batch-entropy regularization, gradient descent optimizers can transform untrainable networks into trainable networks. We show empirically that we can therefore train a "vanilla" fully connected network and convolutional neural network -- no skip connections, batch normalization, dropout, or any other architectural tweak -- with 500 layers by simply adding the batch-entropy regularization term to the loss function. The effect of batch-entropy regularization is not only evaluated on vanilla neural networks, but also on residual networks, autoencoders, and also transformer models over a wide range of computer vision as well as natural language processing tasks.
Momentum Capsule Networks
Jan 26, 2022
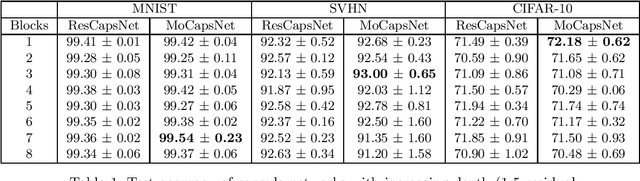
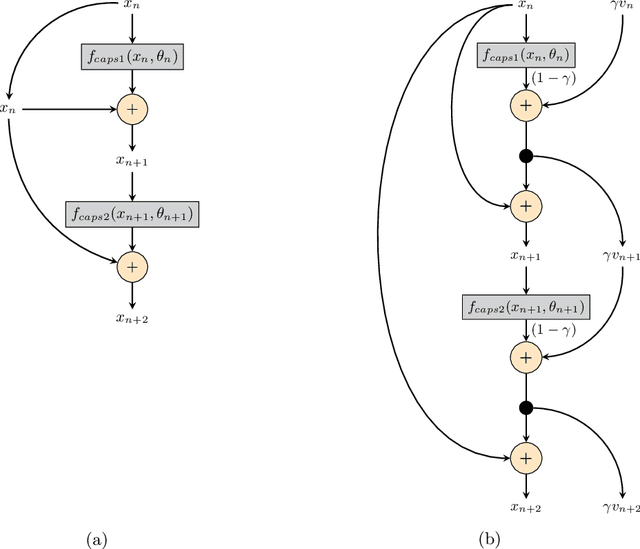
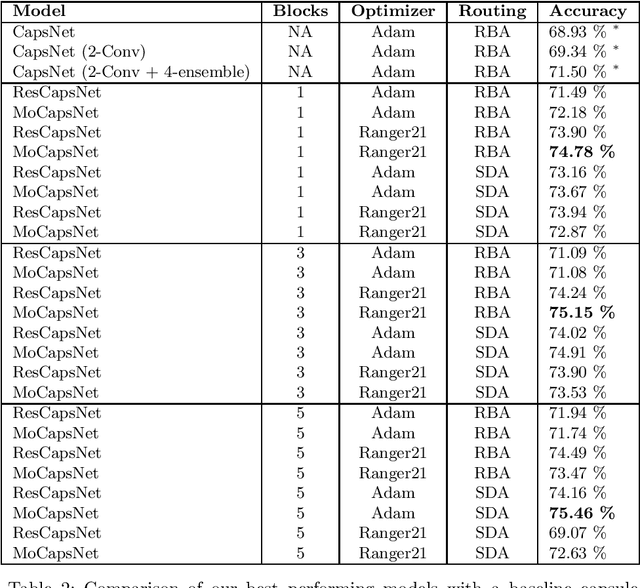
Capsule networks are a class of neural networks that achieved promising results on many computer vision tasks. However, baseline capsule networks have failed to reach state-of-the-art results on more complex datasets due to the high computation and memory requirements. We tackle this problem by proposing a new network architecture, called Momentum Capsule Network (MoCapsNet). MoCapsNets are inspired by Momentum ResNets, a type of network that applies reversible residual building blocks. Reversible networks allow for recalculating activations of the forward pass in the backpropagation algorithm, so those memory requirements can be drastically reduced. In this paper, we provide a framework on how invertible residual building blocks can be applied to capsule networks. We will show that MoCapsNet beats the accuracy of baseline capsule networks on MNIST, SVHN and CIFAR-10 while using considerably less memory. The source code is available on https://github.com/moejoe95/MoCapsNet.
Greedy Layer Pruning: Decreasing Inference Time of Transformer Models
May 31, 2021



Fine-tuning transformer models after unsupervised pre-training reaches a very high performance on many different NLP tasks. Unfortunately, transformers suffer from long inference times which greatly increases costs in production and is a limiting factor for the deployment into embedded devices. One possible solution is to use knowledge distillation, which solves this problem by transferring information from large teacher models to smaller student models, but as it needs an additional expensive pre-training phase, this solution is computationally expensive and can be financially prohibitive for smaller academic research groups. Another solution is to use layer-wise pruning methods, which reach high compression rates for transformer models and avoids the computational load of the pre-training distillation stage. The price to pay is that the performance of layer-wise pruning algorithms is not on par with state-of-the-art knowledge distillation methods. In this paper, greedy layer pruning (GLP) is introduced to (1) outperform current state-of-the-art for layer-wise pruning (2) close the performance gap when compared to knowledge distillation, while (3) using only a modest budget. More precisely, with the methodology presented it is possible to prune and evaluate competitive models on the whole GLUE benchmark with a budget of just $\$300$. Our source code is available on https://github.com/deepopinion/greedy-layer-pruning.
Training Deep Capsule Networks with Residual Connections
Apr 15, 2021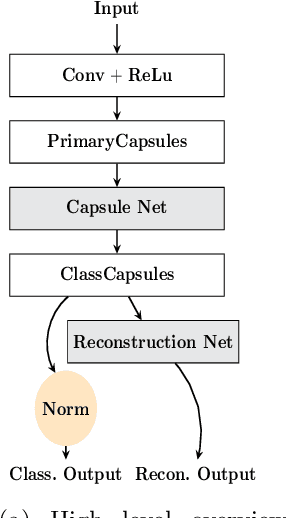

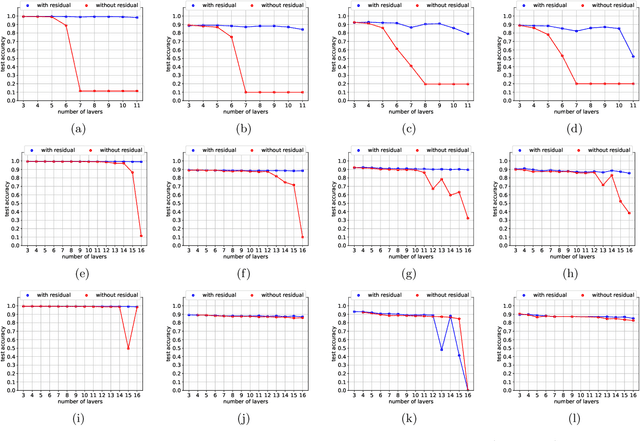
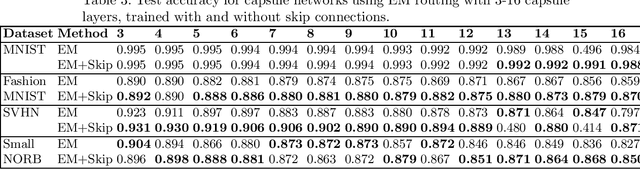
Capsule networks are a type of neural network that have recently gained increased popularity. They consist of groups of neurons, called capsules, which encode properties of objects or object parts. The connections between capsules encrypt part-whole relationships between objects through routing algorithms which route the output of capsules from lower level layers to upper level layers. Capsule networks can reach state-of-the-art results on many challenging computer vision tasks, such as MNIST, Fashion-MNIST, and Small-NORB. However, most capsule network implementations use two to three capsule layers, which limits their applicability as expressivity grows exponentially with depth. One approach to overcome such limitations would be to train deeper network architectures, as it has been done for convolutional neural networks with much increased success. In this paper, we propose a methodology to train deeper capsule networks using residual connections, which is evaluated on four datasets and three different routing algorithms. Our experimental results show that in fact, performance increases when training deeper capsule networks. The source code is available on https://github.com/moejoe95/res-capsnet.
Auto-tuning of Deep Neural Networks by Conflicting Layer Removal
Mar 07, 2021
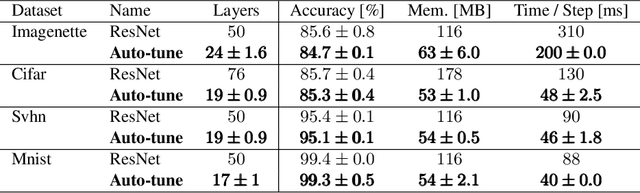


Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel methodology to identify layers that decrease the test accuracy of trained models. Conflicting layers are detected as early as the beginning of training. In the worst-case scenario, we prove that such a layer could lead to a network that cannot be trained at all. A theoretical analysis is provided on what is the origin of those layers that result in a lower overall network performance, which is complemented by our extensive empirical evaluation. More precisely, we identified those layers that worsen the performance because they would produce what we name conflicting training bundles. We will show that around 60% of the layers of trained residual networks can be completely removed from the architecture with no significant increase in the test-error. We will further present a novel neural-architecture-search (NAS) algorithm that identifies conflicting layers at the beginning of the training. Architectures found by our auto-tuning algorithm achieve competitive accuracy values when compared against more complex state-of-the-art architectures, while drastically reducing memory consumption and inference time for different computer vision tasks. The source code is available on https://github.com/peerdavid/conflicting-bundles
Arguments for the Unsuitability of Convolutional Neural Networks for Non--Local Tasks
Feb 23, 2021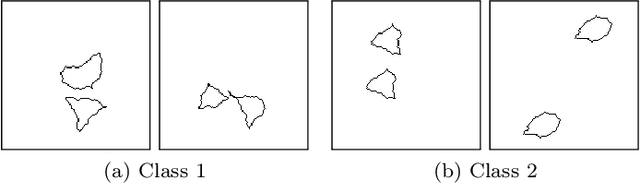
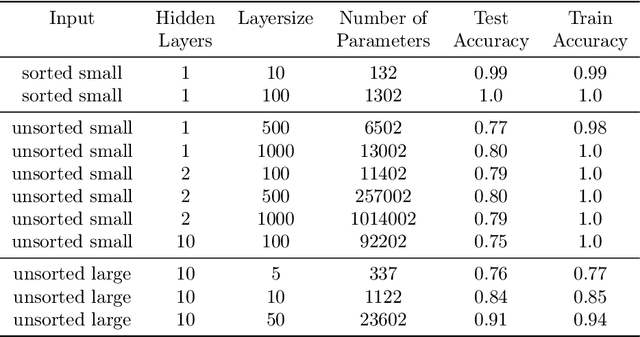
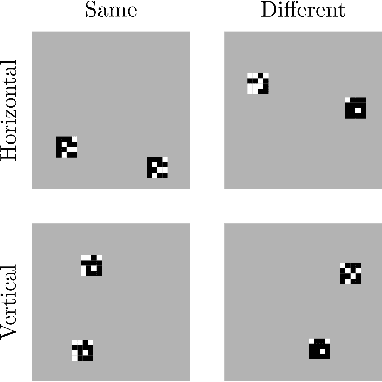
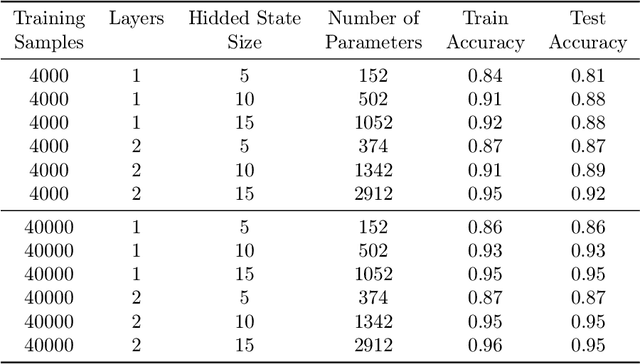
Convolutional neural networks have established themselves over the past years as the state of the art method for image classification, and for many datasets, they even surpass humans in categorizing images. Unfortunately, the same architectures perform much worse when they have to compare parts of an image to each other to correctly classify this image. Until now, no well-formed theoretical argument has been presented to explain this deficiency. In this paper, we will argue that convolutional layers are of little use for such problems, since comparison tasks are global by nature, but convolutional layers are local by design. We will use this insight to reformulate a comparison task into a sorting task and use findings on sorting networks to propose a lower bound for the number of parameters a neural network needs to solve comparison tasks in a generalizable way. We will use this lower bound to argue that attention, as well as iterative/recurrent processing, is needed to prevent a combinatorial explosion.
Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks
Nov 05, 2020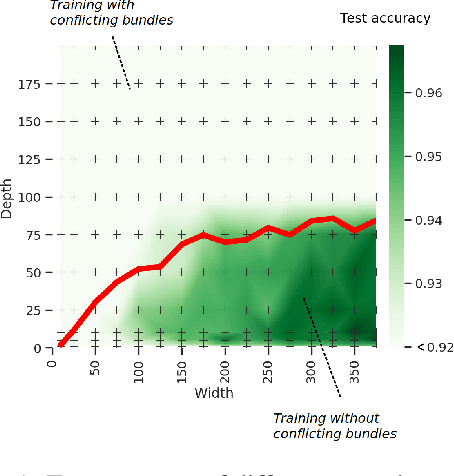
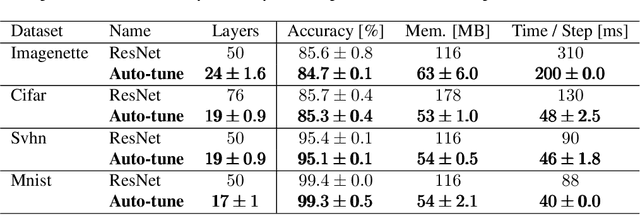


Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel theory and metric to identify layers that decrease the test accuracy of the trained models, this identification is done as early as at the beginning of training. In the worst-case, such a layer could lead to a network that can not be trained at all. More precisely, we identified those layers that worsen the performance because they produce conflicting training bundles as we show in our novel theoretical analysis, complemented by our extensive empirical studies. Based on these findings, a novel algorithm is introduced to remove performance decreasing layers automatically. Architectures found by this algorithm achieve a competitive accuracy when compared against the state-of-the-art architectures. While keeping such high accuracy, our approach drastically reduces memory consumption and inference time for different computer vision tasks.
Limitations of routing-by-agreement based capsule networks
May 21, 2019



Classical neural networks add a bias term to the sum of all weighted inputs. For capsule networks, the routing-by-agreement algorithm, which is commonly used to route vectors from lower level capsules to upper level capsules, calculates activations without a bias term. In this paper we show that such a term is also necessary for routing-by-agreement. We will proof that for every input there exists a symmetric input that cannot be distinguished correctly by capsules without a bias term. We show that this limitation impacts the training of deeper capsule networks negatively and that adding a bias term allows for the training of deeper capsule networks. An alternative to a bias is also presented in this paper. This novel method does not introduce additional parameters and is directly encoded in the activation vector of capsules.