 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Layer Pruning: Decreasing Inference Time of Transformer Models
May 31, 2021



Fine-tuning transformer models after unsupervised pre-training reaches a very high performance on many different NLP tasks. Unfortunately, transformers suffer from long inference times which greatly increases costs in production and is a limiting factor for the deployment into embedded devices. One possible solution is to use knowledge distillation, which solves this problem by transferring information from large teacher models to smaller student models, but as it needs an additional expensive pre-training phase, this solution is computationally expensive and can be financially prohibitive for smaller academic research groups. Another solution is to use layer-wise pruning methods, which reach high compression rates for transformer models and avoids the computational load of the pre-training distillation stage. The price to pay is that the performance of layer-wise pruning algorithms is not on par with state-of-the-art knowledge distillation methods. In this paper, greedy layer pruning (GLP) is introduced to (1) outperform current state-of-the-art for layer-wise pruning (2) close the performance gap when compared to knowledge distillation, while (3) using only a modest budget. More precisely, with the methodology presented it is possible to prune and evaluate competitive models on the whole GLUE benchmark with a budget of just $\$300$. Our source code is available on https://github.com/deepopinion/greedy-layer-pruning.
Adapt or Get Left Behind: Domain Adaptation through BERT Language Model Finetuning for Aspect-Target Sentiment Classification
Aug 30, 2019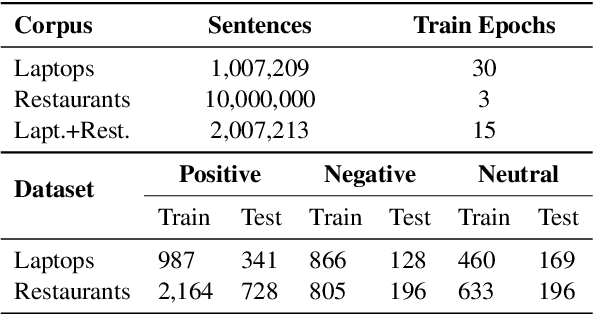
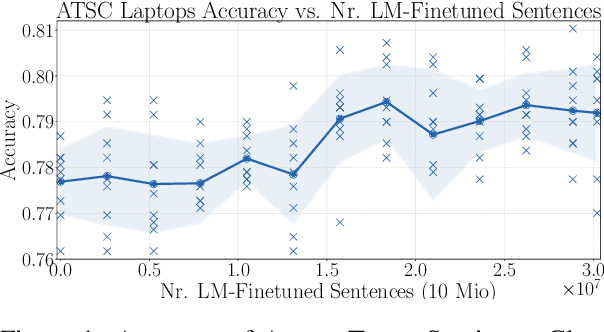
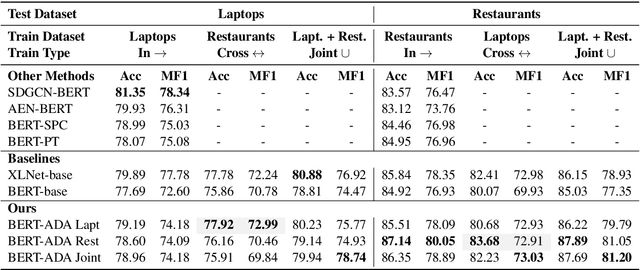
Aspect-Target Sentiment Classification (ATSC) is a subtask of Aspect-Based Sentiment Analysis (ABSA), which has many applications e.g. in e-commerce, where data and insights from reviews can be leveraged to create value for businesses and customers. Recently, deep transfer-learning methods have been applied successfully to a myriad of Natural Language Processing (NLP) tasks, including ATSC. Building on top of the prominent the BERT language model, we approach ATSC by using a two-step procedure: Self-supervised domain-specific BERT language model finetuning, followed by supervised task-specific finetuning. Our findings on how to best exploit domain-specific language model finetuning enables us to produce new state-of-the-art performance on the SemEval 2014 Task 4 restaurants dataset. In addition, to explore the real-world robustness of our models, we perform cross-domain evaluation. We show that a cross-domain adapted BERT language model performs significantly better compared to strong baseline models like vanilla BERT-base and XLNet-base.