 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Layer Pruning: Decreasing Inference Time of Transformer Models
May 31, 2021



Fine-tuning transformer models after unsupervised pre-training reaches a very high performance on many different NLP tasks. Unfortunately, transformers suffer from long inference times which greatly increases costs in production and is a limiting factor for the deployment into embedded devices. One possible solution is to use knowledge distillation, which solves this problem by transferring information from large teacher models to smaller student models, but as it needs an additional expensive pre-training phase, this solution is computationally expensive and can be financially prohibitive for smaller academic research groups. Another solution is to use layer-wise pruning methods, which reach high compression rates for transformer models and avoids the computational load of the pre-training distillation stage. The price to pay is that the performance of layer-wise pruning algorithms is not on par with state-of-the-art knowledge distillation methods. In this paper, greedy layer pruning (GLP) is introduced to (1) outperform current state-of-the-art for layer-wise pruning (2) close the performance gap when compared to knowledge distillation, while (3) using only a modest budget. More precisely, with the methodology presented it is possible to prune and evaluate competitive models on the whole GLUE benchmark with a budget of just $\$300$. Our source code is available on https://github.com/deepopinion/greedy-layer-pruning.
Training Deep Capsule Networks with Residual Connections
Apr 15, 2021

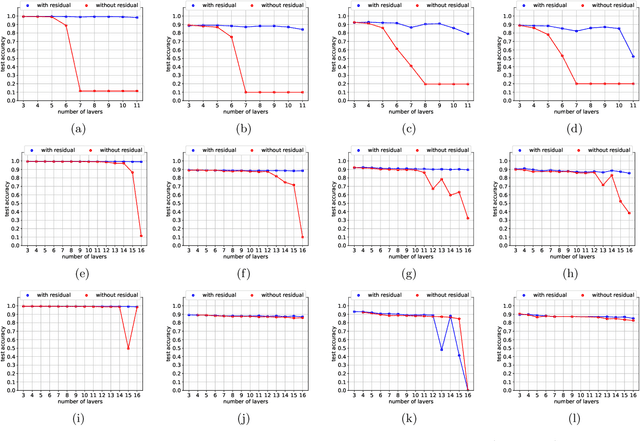
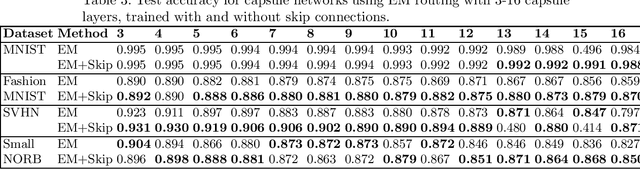
Capsule networks are a type of neural network that have recently gained increased popularity. They consist of groups of neurons, called capsules, which encode properties of objects or object parts. The connections between capsules encrypt part-whole relationships between objects through routing algorithms which route the output of capsules from lower level layers to upper level layers. Capsule networks can reach state-of-the-art results on many challenging computer vision tasks, such as MNIST, Fashion-MNIST, and Small-NORB. However, most capsule network implementations use two to three capsule layers, which limits their applicability as expressivity grows exponentially with depth. One approach to overcome such limitations would be to train deeper network architectures, as it has been done for convolutional neural networks with much increased success. In this paper, we propose a methodology to train deeper capsule networks using residual connections, which is evaluated on four datasets and three different routing algorithms. Our experimental results show that in fact, performance increases when training deeper capsule networks. The source code is available on https://github.com/moejoe95/res-capsnet.
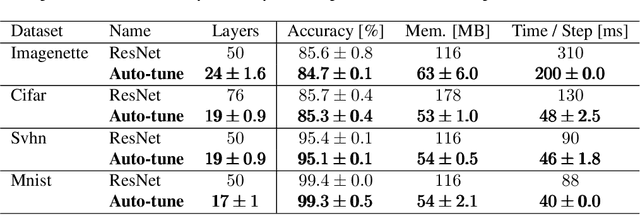
Auto-tuning of Deep Neural Networks by Conflicting Layer Removal
Mar 07, 2021
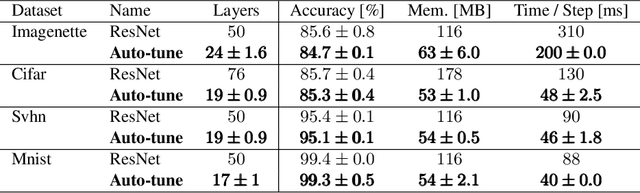


Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel methodology to identify layers that decrease the test accuracy of trained models. Conflicting layers are detected as early as the beginning of training. In the worst-case scenario, we prove that such a layer could lead to a network that cannot be trained at all. A theoretical analysis is provided on what is the origin of those layers that result in a lower overall network performance, which is complemented by our extensive empirical evaluation. More precisely, we identified those layers that worsen the performance because they would produce what we name conflicting training bundles. We will show that around 60% of the layers of trained residual networks can be completely removed from the architecture with no significant increase in the test-error. We will further present a novel neural-architecture-search (NAS) algorithm that identifies conflicting layers at the beginning of the training. Architectures found by our auto-tuning algorithm achieve competitive accuracy values when compared against more complex state-of-the-art architectures, while drastically reducing memory consumption and inference time for different computer vision tasks. The source code is available on https://github.com/peerdavid/conflicting-bundles
Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks
Nov 05, 2020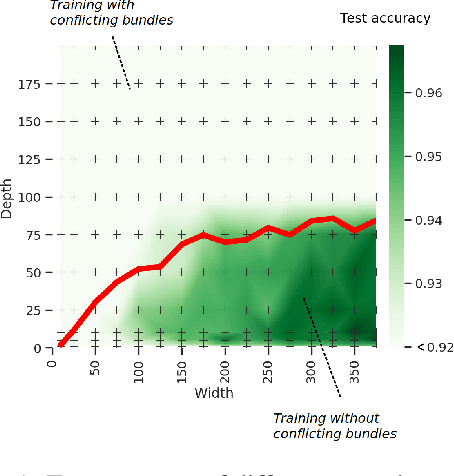


Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel theory and metric to identify layers that decrease the test accuracy of the trained models, this identification is done as early as at the beginning of training. In the worst-case, such a layer could lead to a network that can not be trained at all. More precisely, we identified those layers that worsen the performance because they produce conflicting training bundles as we show in our novel theoretical analysis, complemented by our extensive empirical studies. Based on these findings, a novel algorithm is introduced to remove performance decreasing layers automatically. Architectures found by this algorithm achieve a competitive accuracy when compared against the state-of-the-art architectures. While keeping such high accuracy, our approach drastically reduces memory consumption and inference time for different computer vision tasks.
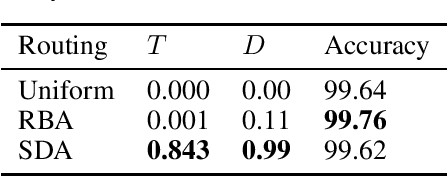
Limitations of routing-by-agreement based capsule networks
May 21, 2019



Classical neural networks add a bias term to the sum of all weighted inputs. For capsule networks, the routing-by-agreement algorithm, which is commonly used to route vectors from lower level capsules to upper level capsules, calculates activations without a bias term. In this paper we show that such a term is also necessary for routing-by-agreement. We will proof that for every input there exists a symmetric input that cannot be distinguished correctly by capsules without a bias term. We show that this limitation impacts the training of deeper capsule networks negatively and that adding a bias term allows for the training of deeper capsule networks. An alternative to a bias is also presented in this paper. This novel method does not introduce additional parameters and is directly encoded in the activation vector of capsules.
Training Deep Capsule Networks
Dec 23, 2018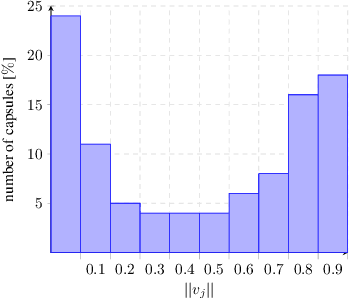


The capsules of Capsule Networks are collections of neurons that represent an object or part of an object in a parse tree. The output vector of a capsule encodes the so called instantiation parameters of this object (e.g. position, size, or orientation). The routing-by-agreement algorithm routes output vectors from lower level capsules to upper level capsules. This iterative algorithm selects the most appropriate parent capsule so that the active capsules in the network represent nodes in a parse tree. This parse tree represents the hierarchical composition of objects out of smaller and smaller components. In this paper, we will show experimentally that the routing-by-agreement algorithm does not ensure the emergence of a parse tree in the network. To ensure that all active capsules form a parse tree, we introduce a new routing algorithm called dynamic deep routing. We show that this routing algorithm allows the training of deeper capsule networks and is also more robust to white box adversarial attacks than the original routing algorithm.
Guided Labeling using Convolutional Neural Networks
Dec 06, 2017



Over the last couple of years, deep learning and especially convolutional neural networks have become one of the work horses of computer vision. One limiting factor for the applicability of supervised deep learning to more areas is the need for large, manually labeled datasets. In this paper we propose an easy to implement method we call guided labeling, which automatically determines which samples from an unlabeled dataset should be labeled. We show that using this procedure, the amount of samples that need to be labeled is reduced considerably in comparison to labeling images arbitrarily.
Evaluation of Deep Learning on an Abstract Image Classification Dataset
Aug 25, 2017
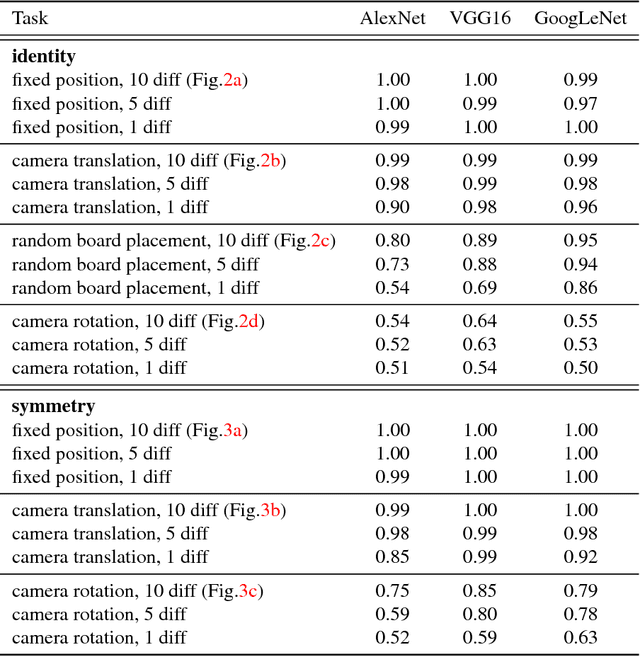


Convolutional Neural Networks have become state of the art methods for image classification over the last couple of years. By now they perform better than human subjects on many of the image classification datasets. Most of these datasets are based on the notion of concrete classes (i.e. images are classified by the type of object in the image). In this paper we present a novel image classification dataset, using abstract classes, which should be easy to solve for humans, but variations of it are challenging for CNNs. The classification performance of popular CNN architectures is evaluated on this dataset and variations of the dataset that might be interesting for further research are identified.
Learning Abstract Classes using Deep Learning
Jun 17, 2016
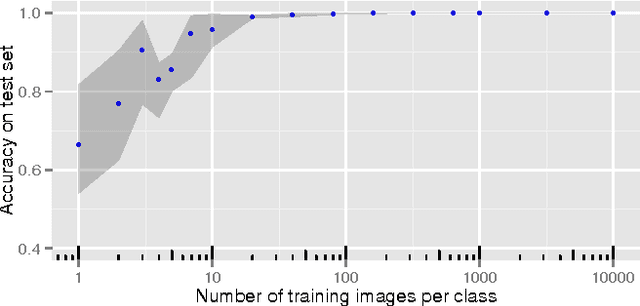


Humans are generally good at learning abstract concepts about objects and scenes (e.g.\ spatial orientation, relative sizes, etc.). Over the last years convolutional neural networks have achieved almost human performance in recognizing concrete classes (i.e.\ specific object categories). This paper tests the performance of a current CNN (GoogLeNet) on the task of differentiating between abstract classes which are trivially differentiable for humans. We trained and tested the CNN on the two abstract classes of horizontal and vertical orientation and determined how well the network is able to transfer the learned classes to other, previously unseen objects.