 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Be Trusted for Evaluating RAG Systems? A Survey of Methods and Datasets
Apr 28, 2025Retrieval-Augmented Generation (RAG) has advanced significantly in recent years. The complexity of RAG systems, which involve multiple components-such as indexing, retrieval, and generation-along with numerous other parameters, poses substantial challenges for systematic evaluation and quality enhancement. Previous research highlights that evaluating RAG systems is essential for documenting advancements, comparing configurations, and identifying effective approaches for domain-specific applications. This study systematically reviews 63 academic articles to provide a comprehensive overview of state-of-the-art RAG evaluation methodologies, focusing on four key areas: datasets, retrievers, indexing and databases, and the generator component. We observe the feasibility of an automated evaluation approach for each component of a RAG system, leveraging an LLM capable of both generating evaluation datasets and conducting evaluations. In addition, we found that further practical research is essential to provide companies with clear guidance on the do's and don'ts of implementing and evaluating RAG systems. By synthesizing evaluation approaches for key RAG components and emphasizing the creation and adaptation of domain-specific datasets for benchmarking, we contribute to the advancement of systematic evaluation methods and the improvement of evaluation rigor for RAG systems. Furthermore, by examining the interplay between automated approaches leveraging LLMs and human judgment, we contribute to the ongoing discourse on balancing automation and human input, clarifying their respective contributions, limitations, and challenges in achieving robust and reliable evaluations.
Vision Transformers for Weakly-Supervised Microorganism Enumeration
Dec 03, 2024Microorganism enumeration is an essential task in many applications, such as assessing contamination levels or ensuring health standards when evaluating surface cleanliness. However, it's traditionally performed by human-supervised methods that often require manual counting, making it tedious and time-consuming. Previous research suggests automating this task using computer vision and machine learning methods, primarily through instance segmentation or density estimation techniques. This study conducts a comparative analysis of vision transformers (ViTs) for weakly-supervised counting in microorganism enumeration, contrasting them with traditional architectures such as ResNet and investigating ViT-based models such as TransCrowd. We trained different versions of ViTs as the architectural backbone for feature extraction using four microbiology datasets to determine potential new approaches for total microorganism enumeration in images. Results indicate that while ResNets perform better overall, ViTs performance demonstrates competent results across all datasets, opening up promising lines of research in microorganism enumeration. This comparative study contributes to the field of microbial image analysis by presenting innovative approaches to the recurring challenge of microorganism enumeration and by highlighting the capabilities of ViTs in the task of regression counting.
A Survey Study on the State of the Art of Programming Exercise Generation using Large Language Models
May 30, 2024This paper analyzes Large Language Models (LLMs) with regard to their programming exercise generation capabilities. Through a survey study, we defined the state of the art, extracted their strengths and weaknesses and finally proposed an evaluation matrix, helping researchers and educators to decide which LLM is the best fitting for the programming exercise generation use case. We also found that multiple LLMs are capable of producing useful programming exercises. Nevertheless, there exist challenges like the ease with which LLMs might solve exercises generated by LLMs. This paper contributes to the ongoing discourse on the integration of LLMs in education.
AI-Tutoring in Software Engineering Education
Apr 05, 2024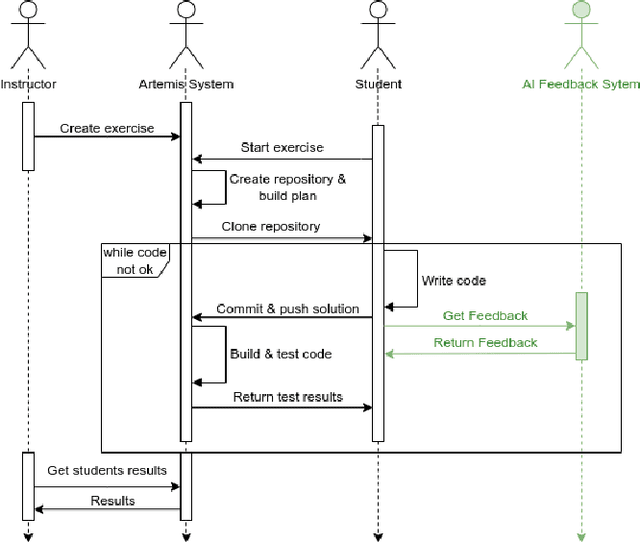

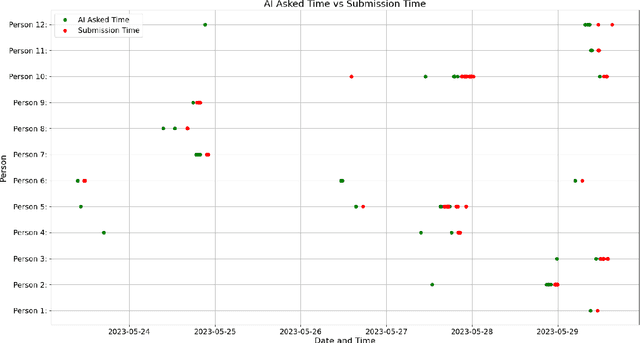
With the rapid advancement of artificial intelligence (AI) in various domains, the education sector is set for transformation. The potential of AI-driven tools in enhancing the learning experience, especially in programming, is immense. However, the scientific evaluation of Large Language Models (LLMs) used in Automated Programming Assessment Systems (APASs) as an AI-Tutor remains largely unexplored. Therefore, there is a need to understand how students interact with such AI-Tutors and to analyze their experiences. In this paper, we conducted an exploratory case study by integrating the GPT-3.5-Turbo model as an AI-Tutor within the APAS Artemis. Through a combination of empirical data collection and an exploratory survey, we identified different user types based on their interaction patterns with the AI-Tutor. Additionally, the findings highlight advantages, such as timely feedback and scalability. However, challenges like generic responses and students' concerns about a learning progress inhibition when using the AI-Tutor were also evident. This research adds to the discourse on AI's role in education.