 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparsity: Challenging Common Sparsity Assumptions for Learning World Models in Robotic Reinforcement Learning Benchmarks
Nov 14, 2025
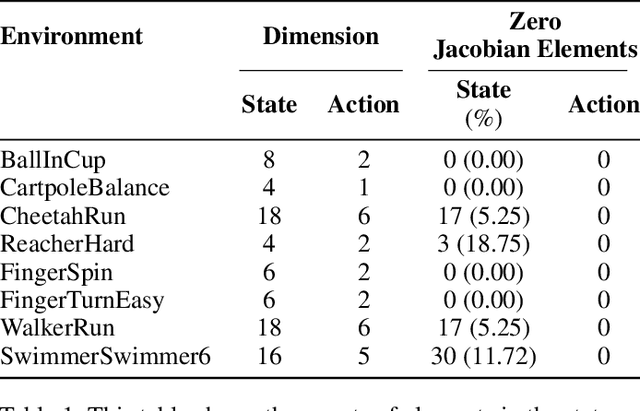
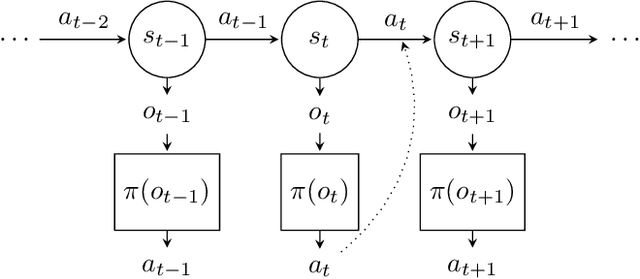

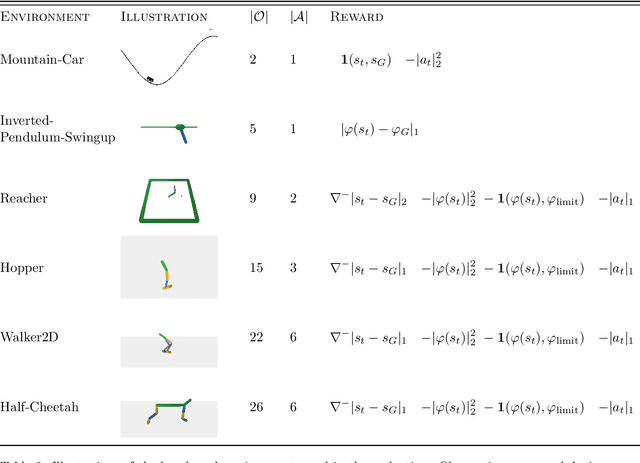
The use of learned dynamics models, also known as world models, can improve the sample efficiency of reinforcement learning. Recent work suggests that the underlying causal graphs of such dynamics models are sparsely connected, with each of the future state variables depending only on a small subset of the current state variables, and that learning may therefore benefit from sparsity priors. Similarly, temporal sparsity, i.e. sparsely and abruptly changing local dynamics, has also been proposed as a useful inductive bias. In this work, we critically examine these assumptions by analyzing ground-truth dynamics from a set of robotic reinforcement learning environments in the MuJoCo Playground benchmark suite, aiming to determine whether the proposed notions of state and temporal sparsity actually tend to hold in typical reinforcement learning tasks. We study (i) whether the causal graphs of environment dynamics are sparse, (ii) whether such sparsity is state-dependent, and (iii) whether local system dynamics change sparsely. Our results indicate that global sparsity is rare, but instead the tasks show local, state-dependent sparsity in their dynamics and this sparsity exhibits distinct structures, appearing in temporally localized clusters (e.g., during contact events) and affecting specific subsets of state dimensions. These findings challenge common sparsity prior assumptions in dynamics learning, emphasizing the need for grounded inductive biases that reflect the state-dependent sparsity structure of real-world dynamics.
Unsupervised Learning of Effective Actions in Robotics
Apr 03, 2024



Learning actions that are relevant to decision-making and can be executed effectively is a key problem in autonomous robotics. Current state-of-the-art action representations in robotics lack proper effect-driven learning of the robot's actions. Although successful in solving manipulation tasks, deep learning methods also lack this ability, in addition to their high cost in terms of memory or training data. In this paper, we propose an unsupervised algorithm to discretize a continuous motion space and generate "action prototypes", each producing different effects in the environment. After an exploration phase, the algorithm automatically builds a representation of the effects and groups motions into action prototypes, where motions more likely to produce an effect are represented more than those that lead to negligible changes. We evaluate our method on a simulated stair-climbing reinforcement learning task, and the preliminary results show that our effect driven discretization outperforms uniformly and randomly sampled discretizations in convergence speed and maximum reward.
Colored Noise in PPO: Improved Exploration and Performance Through Correlated Action Sampling
Dec 18, 2023
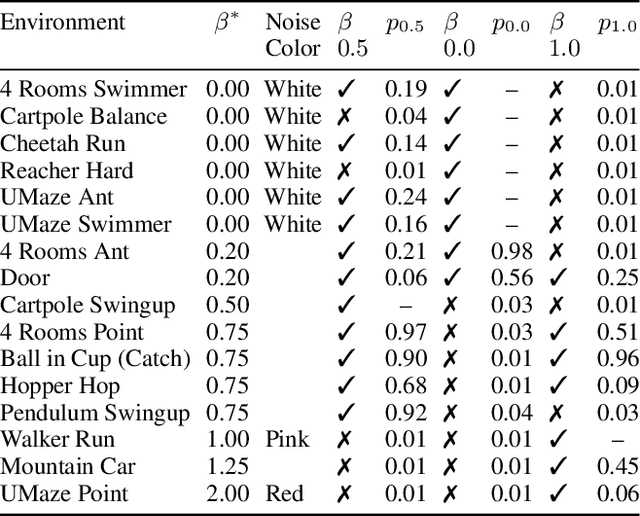


Proximal Policy Optimization (PPO), a popular on-policy deep reinforcement learning method, employs a stochastic policy for exploration. In this paper, we propose a colored noise-based stochastic policy variant of PPO. Previous research highlighted the importance of temporal correlation in action noise for effective exploration in off-policy reinforcement learning. Building on this, we investigate whether correlated noise can also enhance exploration in on-policy methods like PPO. We discovered that correlated noise for action selection improves learning performance and outperforms the currently popular uncorrelated white noise approach in on-policy methods. Unlike off-policy learning, where pink noise was found to be highly effective, we found that a colored noise, intermediate between white and pink, performed best for on-policy learning in PPO. We examined the impact of varying the amount of data collected for each update by modifying the number of parallel simulation environments for data collection and observed that with a larger number of parallel environments, more strongly correlated noise is beneficial. Due to the significant impact and ease of implementation, we recommend switching to correlated noise as the default noise source in PPO.
Scalable and Efficient Continual Learning from Demonstration via Hypernetwork-generated Stable Dynamics Model
Nov 06, 2023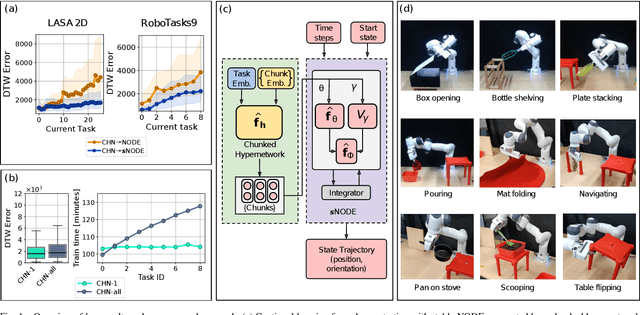
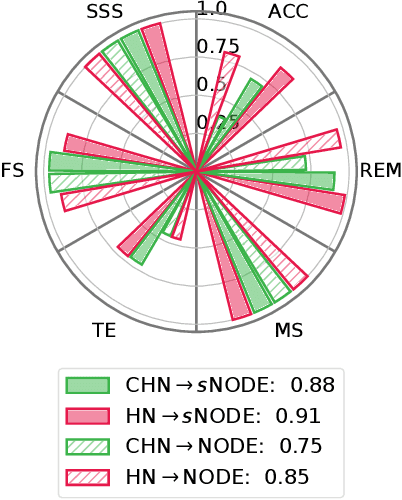
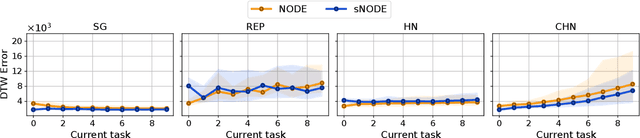
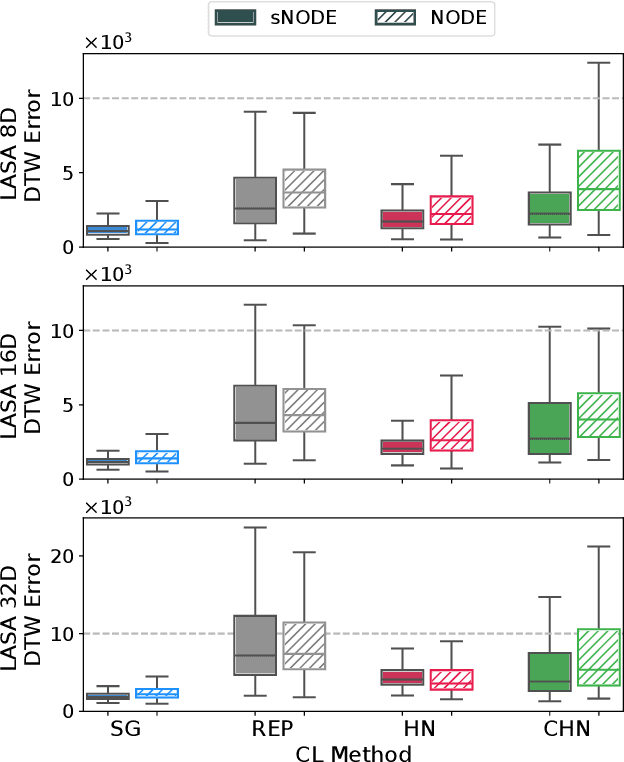
Learning from demonstration (LfD) provides an efficient way to train robots. The learned motions should be convergent and stable, but to be truly effective in the real world, LfD-capable robots should also be able to remember multiple motion skills. Multi-skill retention is a capability missing from existing stable-LfD approaches. On the other hand, recent work on continual-LfD has shown that hypernetwork-generated neural ordinary differential equation solvers, can learn multiple LfD tasks sequentially, but this approach lacks stability guarantees. We propose an approach for stable continual-LfD in which a hypernetwork generates two networks: a trajectory learning dynamics model, and a trajectory stabilizing Lyapunov function. The introduction of stability not only generates stable trajectories but also greatly improves continual learning performance, especially in the size-efficient chunked hypernetworks. With our approach, we can continually train a single model to predict the position and orientation trajectories of the robot's end-effector simultaneously for multiple real world tasks without retraining on past demonstrations. We also propose stochastic regularization with a single randomly sampled regularization term in hypernetworks, which reduces the cumulative training time cost for $N$ tasks from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$ without any loss in performance in real-world tasks. We empirically evaluate our approach on the popular LASA dataset, on high-dimensional extensions of LASA (including up to 32 dimensions) to assess scalability, and on a novel extended robotic task dataset (RoboTasks9) to assess real-world performance. In trajectory error metrics, stability metrics and continual learning metrics our approach performs favorably, compared to other baselines. Code and datasets will be shared after submission.
Action Noise in Off-Policy Deep Reinforcement Learning: Impact on Exploration and Performance
Jun 08, 2022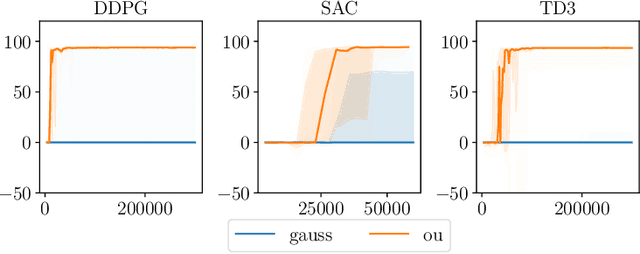
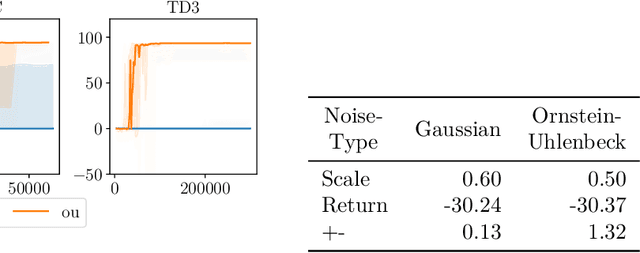
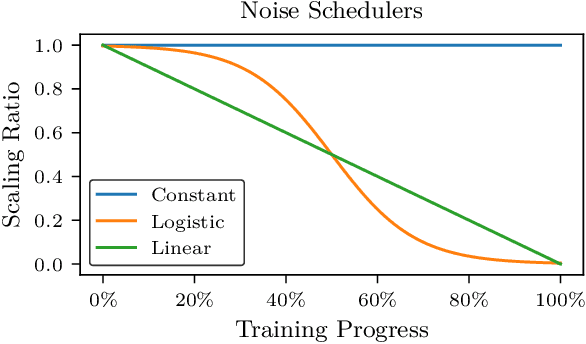
Many deep reinforcement learning algorithms rely on simple forms of exploration, such as the additive action-noise often used in continuous control domains. Typically, the scaling factor of this action noise is chosen as a hyper-parameter and kept constant during training. In this paper, we analyze how the learned policy is impacted by the noise type, scale, and reducing of the scaling factor over time. We consider the two most prominent types of action-noise: Gaussian and Ornstein-Uhlenbeck noise, and perform a vast experimental campaign by systematically varying the noise type and scale parameter, and by measuring variables of interest like the expected return of the policy and the state space coverage during exploration. For the latter, we propose a novel state-space coverage measure $\operatorname{X}_{\mathcal{U}\text{rel}}$ that is more robust to boundary artifacts than previously proposed measures. Larger noise scales generally increase state space coverage. However, we found that increasing the space coverage using a larger noise scale is often not beneficial. On the contrary, reducing the noise-scale over the training process reduces the variance and generally improves the learning performance. We conclude that the best noise-type and scale are environment dependent, and based on our observations, derive heuristic rules for guiding the choice of the action noise as a starting point for further optimization.
Continual Learning from Demonstration of Robotic Skills
Feb 15, 2022
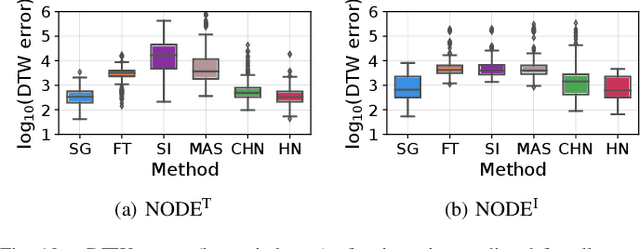

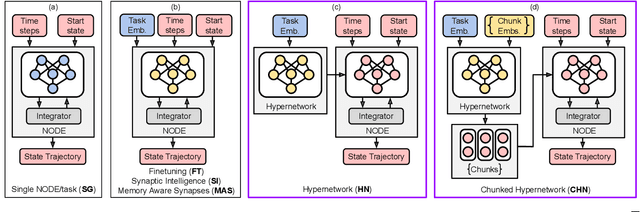
Methods for teaching motion skills to robots focus on training for a single skill at a time. Robots capable of learning from demonstration can considerably benefit from the added ability to learn new movements without forgetting past knowledge. To this end, we propose an approach for continual learning from demonstration using hypernetworks and neural ordinary differential equation solvers. We empirically demonstrate the effectiveness of our approach in remembering long sequences of trajectory learning tasks without the need to store any data from past demonstrations. Our results show that hypernetworks outperform other state-of-the-art regularization-based continual learning approaches for learning from demonstration. In our experiments, we use the popular LASA trajectory benchmark, and a new dataset of kinesthetic demonstrations that we introduce in this paper called the HelloWorld dataset. We evaluate our approach using both trajectory error metrics and continual learning metrics, and we propose two new continual learning metrics. Our code, along with the newly collected dataset, is available at https://github.com/sayantanauddy/clfd.