 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Effective Actions in Robotics
Apr 03, 2024



Learning actions that are relevant to decision-making and can be executed effectively is a key problem in autonomous robotics. Current state-of-the-art action representations in robotics lack proper effect-driven learning of the robot's actions. Although successful in solving manipulation tasks, deep learning methods also lack this ability, in addition to their high cost in terms of memory or training data. In this paper, we propose an unsupervised algorithm to discretize a continuous motion space and generate "action prototypes", each producing different effects in the environment. After an exploration phase, the algorithm automatically builds a representation of the effects and groups motions into action prototypes, where motions more likely to produce an effect are represented more than those that lead to negligible changes. We evaluate our method on a simulated stair-climbing reinforcement learning task, and the preliminary results show that our effect driven discretization outperforms uniformly and randomly sampled discretizations in convergence speed and maximum reward.
Action Noise in Off-Policy Deep Reinforcement Learning: Impact on Exploration and Performance
Jun 08, 2022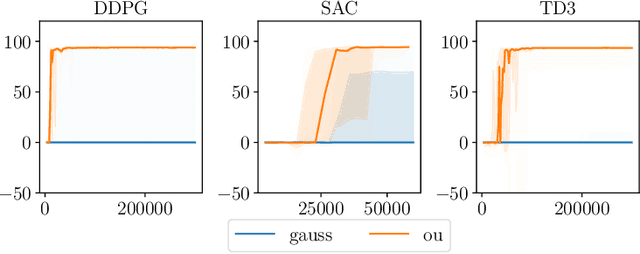
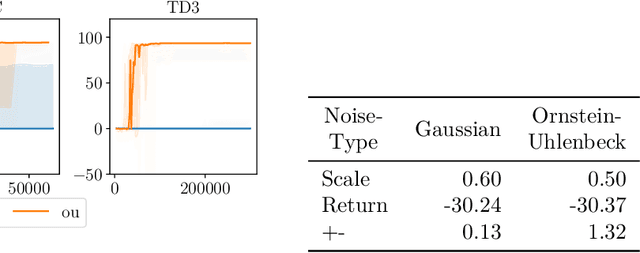
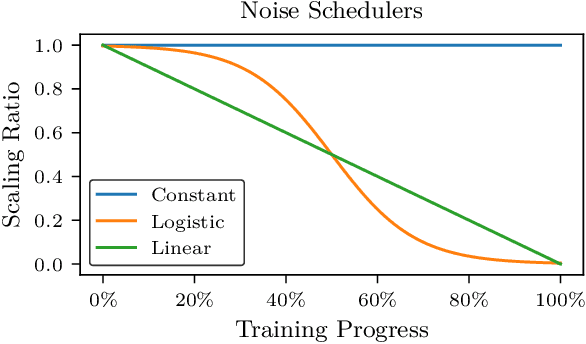
Many deep reinforcement learning algorithms rely on simple forms of exploration, such as the additive action-noise often used in continuous control domains. Typically, the scaling factor of this action noise is chosen as a hyper-parameter and kept constant during training. In this paper, we analyze how the learned policy is impacted by the noise type, scale, and reducing of the scaling factor over time. We consider the two most prominent types of action-noise: Gaussian and Ornstein-Uhlenbeck noise, and perform a vast experimental campaign by systematically varying the noise type and scale parameter, and by measuring variables of interest like the expected return of the policy and the state space coverage during exploration. For the latter, we propose a novel state-space coverage measure $\operatorname{X}_{\mathcal{U}\text{rel}}$ that is more robust to boundary artifacts than previously proposed measures. Larger noise scales generally increase state space coverage. However, we found that increasing the space coverage using a larger noise scale is often not beneficial. On the contrary, reducing the noise-scale over the training process reduces the variance and generally improves the learning performance. We conclude that the best noise-type and scale are environment dependent, and based on our observations, derive heuristic rules for guiding the choice of the action noise as a starting point for further optimization.
How do Offline Measures for Exploration in Reinforcement Learning behave?
Oct 29, 2020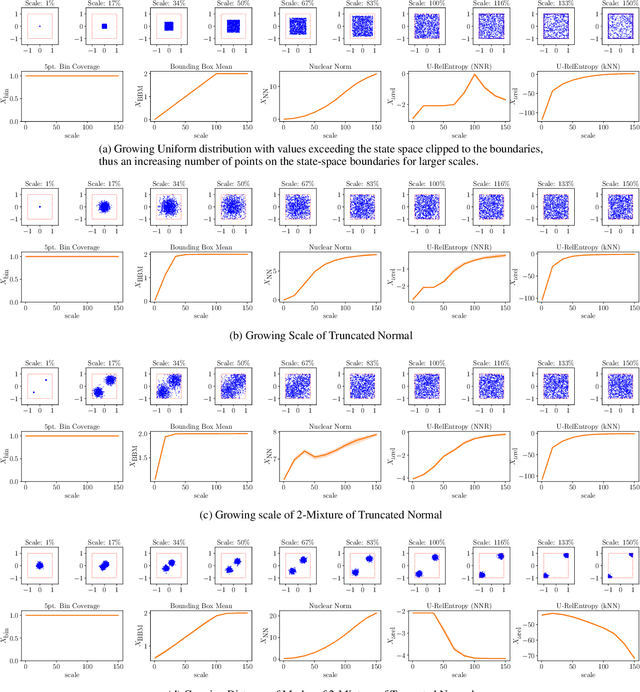
Sufficient exploration is paramount for the success of a reinforcement learning agent. Yet, exploration is rarely assessed in an algorithm-independent way. We compare the behavior of three data-based, offline exploration metrics described in the literature on intuitive simple distributions and highlight problems to be aware of when using them. We propose a fourth metric,uniform relative entropy, and implement it using either a k-nearest-neighbor or a nearest-neighbor-ratio estimator, highlighting that the implementation choices have a profound impact on these measures.
Improving the Exploration of Deep Reinforcement Learning in Continuous Domains using Planning for Policy Search
Oct 24, 2020
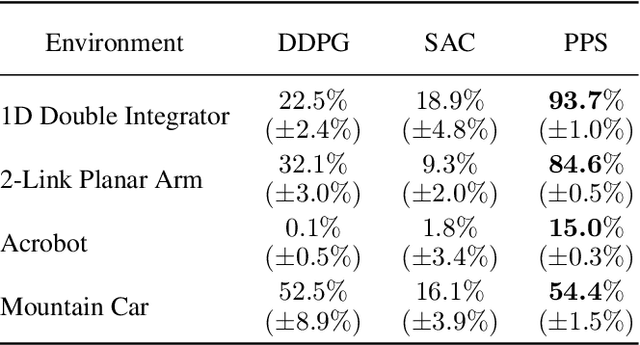
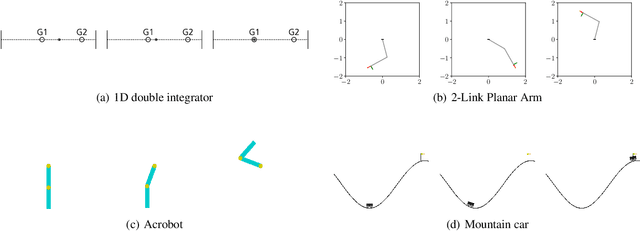

Local policy search is performed by most Deep Reinforcement Learning (D-RL) methods, which increases the risk of getting trapped in a local minimum. Furthermore, the availability of a simulation model is not fully exploited in D-RL even in simulation-based training, which potentially decreases efficiency. To better exploit simulation models in policy search, we propose to integrate a kinodynamic planner in the exploration strategy and to learn a control policy in an offline fashion from the generated environment interactions. We call the resulting model-based reinforcement learning method PPS (Planning for Policy Search). We compare PPS with state-of-the-art D-RL methods in typical RL settings including underactuated systems. The comparison shows that PPS, guided by the kinodynamic planner, collects data from a wider region of the state space. This generates training data that helps PPS discover better policies.
Coping with the variability in humans reward during simulated human-robot interactions through the coordination of multiple learning strategies
May 06, 2020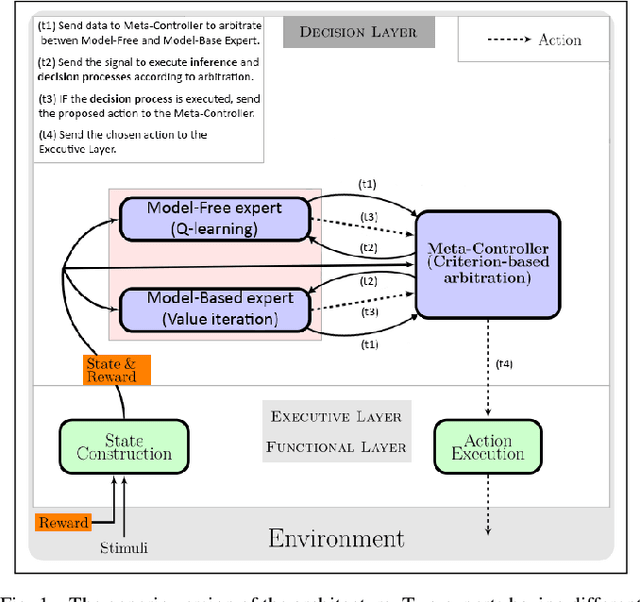
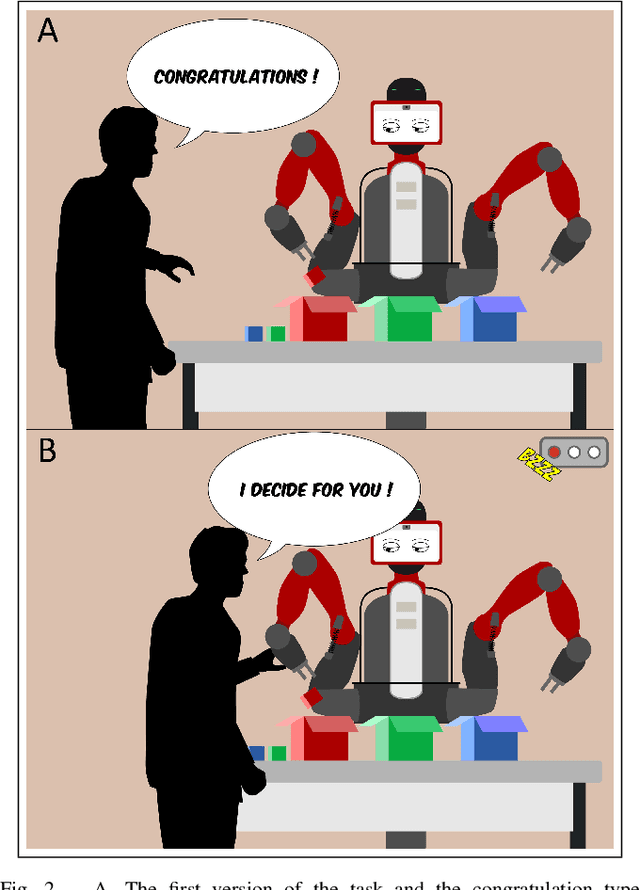
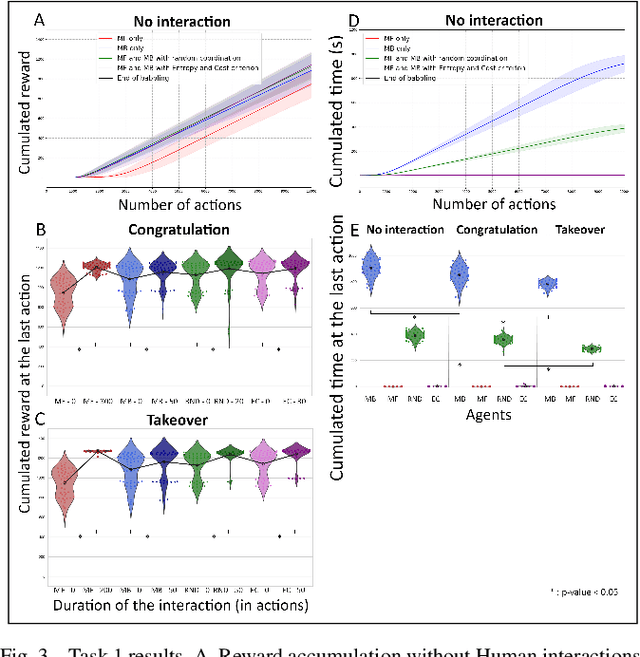
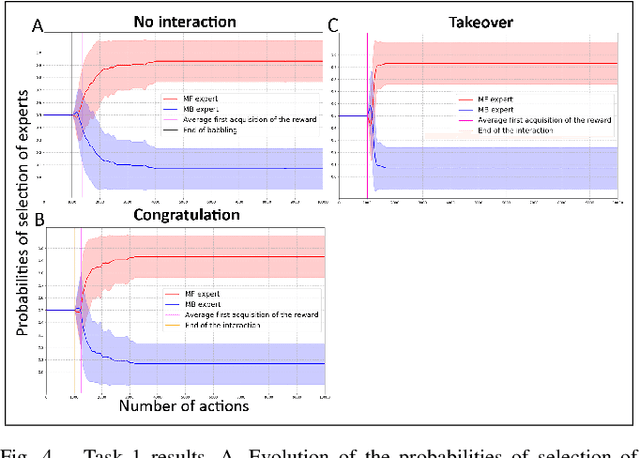
An important current challenge in Human-Robot Interaction (HRI) is to enable robots to learn on-the-fly from human feedback. However, humans show a great variability in the way they reward robots. We propose to address this issue by enabling the robot to combine different learning strategies, namely model-based (MB) and model-free (MF) reinforcement learning. We simulate two HRI scenarios: a simple task where the human congratulates the robot for putting the right cubes in the right boxes, and a more complicated version of this task where cubes have to be placed in a specific order. We show that our existing MB-MF coordination algorithm previously tested in robot navigation works well here without retuning parameters. It leads to the maximal performance while producing the same minimal computational cost as MF alone. Moreover, the algorithm gives a robust performance no matter the variability of the simulated human feedback, while each strategy alone is impacted by this variability. Overall, the results suggest a promising way to promote robot learning flexibility when facing variable human feedback.
How to reduce computation time while sparing performance during robot navigation? A neuro-inspired architecture for autonomous shifting between model-based and model-free learning
Apr 30, 2020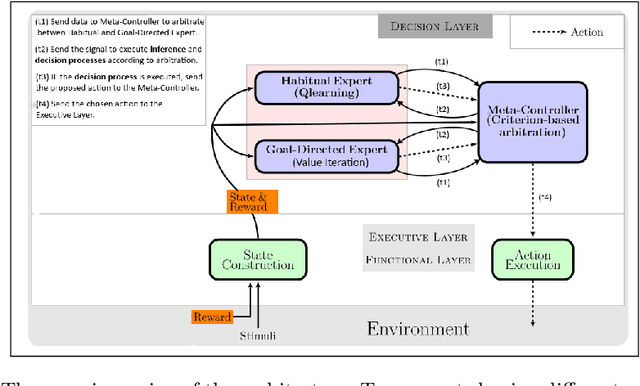
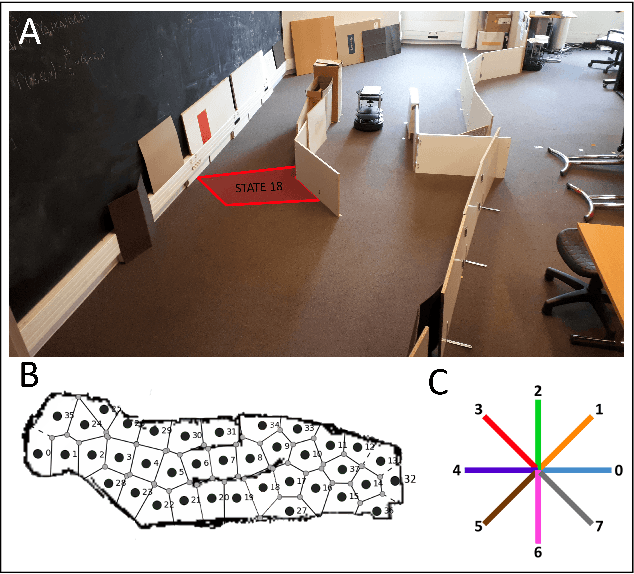
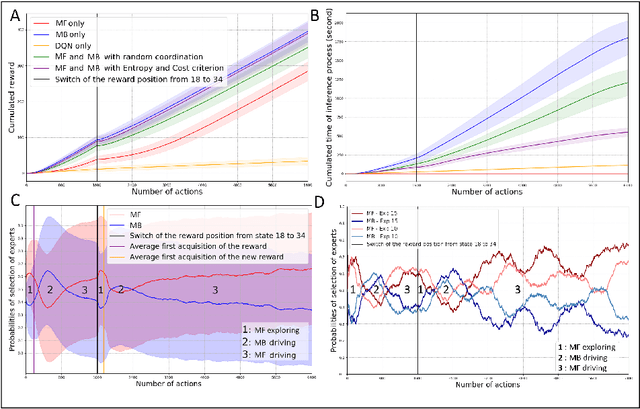
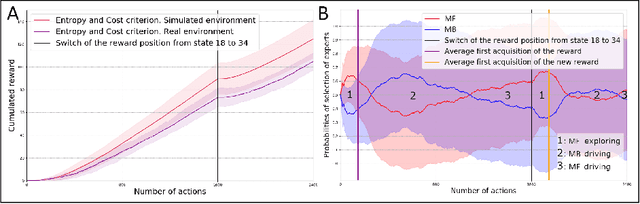
Taking inspiration from how the brain coordinates multiple learning systems is an appealing strategy to endow robots with more flexibility. One of the expected advantages would be for robots to autonomously switch to the least costly system when its performance is satisfying. However, to our knowledge no study on a real robot has yet shown that the measured computational cost is reduced while performance is maintained with such brain-inspired algorithms. We present navigation experiments involving paths of different lengths to the goal, dead-end, and non-stationarity (i.e., change in goal location and apparition of obstacles). We present a novel arbitration mechanism between learning systems that explicitly measures performance and cost. We find that the robot can adapt to environment changes by switching between learning systems so as to maintain a high performance. Moreover, when the task is stable, the robot also autonomously shifts to the least costly system, which leads to a drastic reduction in computation cost while keeping a high performance. Overall, these results illustrates the interest of using multiple learning systems.
Action Representations in Robotics: A Taxonomy and Systematic Classification
Sep 12, 2018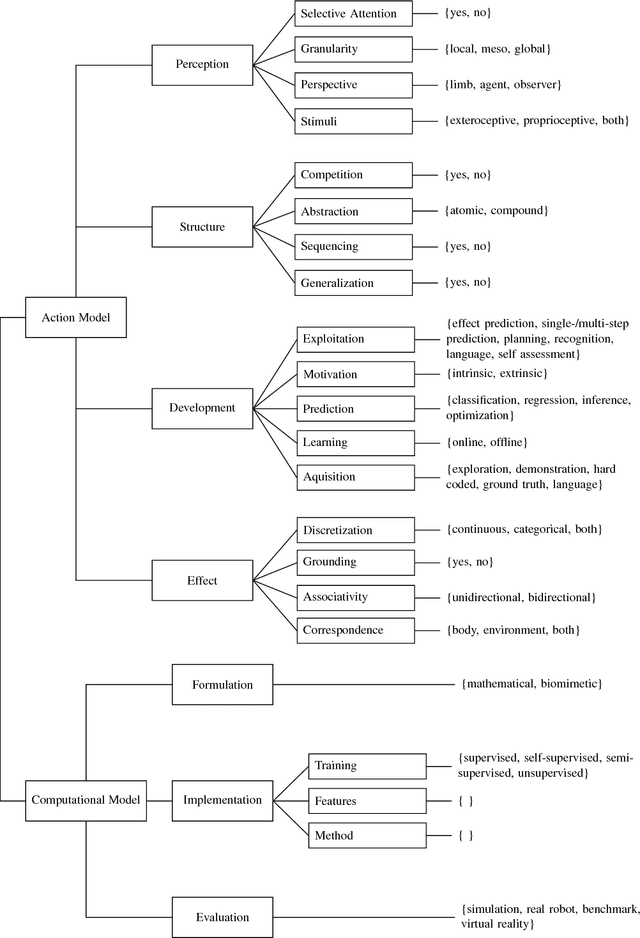
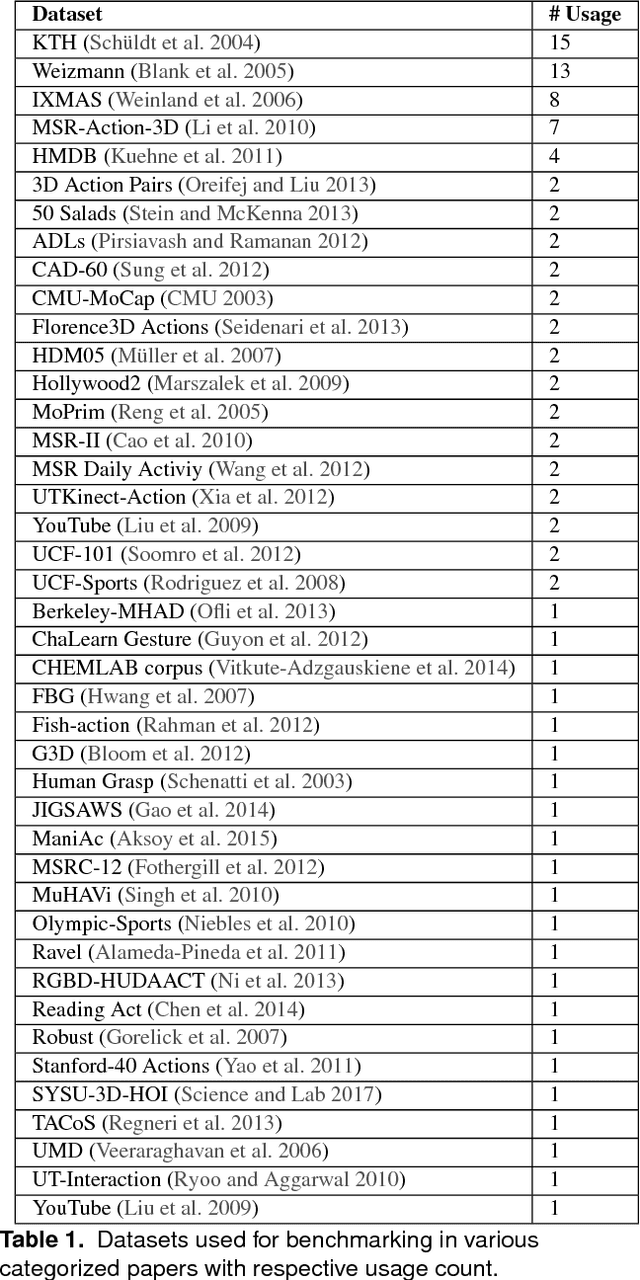
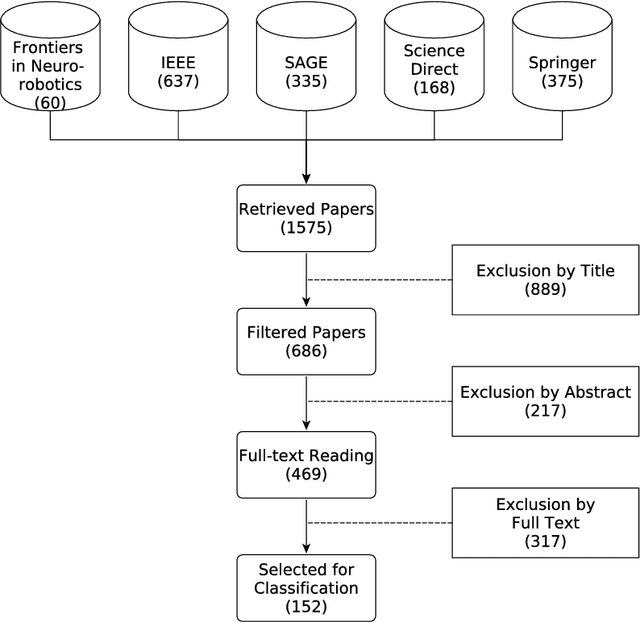
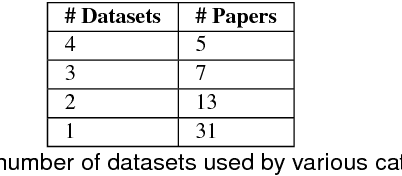
Understanding and defining the meaning of "action" is substantial for robotics research. This becomes utterly evident when aiming at equipping autonomous robots with robust manipulation skills for action execution. Unfortunately, to this day we still lack both a clear understanding of the concept of an action and a set of established criteria that ultimately characterize an action. In this survey we thus first review existing ideas and theories on the notion and meaning of action. Subsequently we discuss the role of action in robotics and attempt to give a seminal definition of action in accordance with its use in robotics research. Given this definition we then introduce a taxonomy for categorizing action representations in robotics along various dimensions. Finally, we provide a systematic literature survey on action representations in robotics where we categorize relevant literature along our taxonomy. After discussing the current state of the art we conclude with an outlook towards promising research directions.