 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorality is Contextual: Learning Interpretable Moral Contexts from Human Data with Probabilistic Clustering and Large Language Models
Dec 24, 2025Moral actions are judged not only by their outcomes but by the context in which they occur. We present COMETH (Contextual Organization of Moral Evaluation from Textual Human inputs), a framework that integrates a probabilistic context learner with LLM-based semantic abstraction and human moral evaluations to model how context shapes the acceptability of ambiguous actions. We curate an empirically grounded dataset of 300 scenarios across six core actions (violating Do not kill, Do not deceive, and Do not break the law) and collect ternary judgments (Blame/Neutral/Support) from N=101 participants. A preprocessing pipeline standardizes actions via an LLM filter and MiniLM embeddings with K-means, producing robust, reproducible core-action clusters. COMETH then learns action-specific moral contexts by clustering scenarios online from human judgment distributions using principled divergence criteria. To generalize and explain predictions, a Generalization module extracts concise, non-evaluative binary contextual features and learns feature weights in a transparent likelihood-based model. Empirically, COMETH roughly doubles alignment with majority human judgments relative to end-to-end LLM prompting (approx. 60% vs. approx. 30% on average), while revealing which contextual features drive its predictions. The contributions are: (i) an empirically grounded moral-context dataset, (ii) a reproducible pipeline combining human judgments with model-based context learning and LLM semantics, and (iii) an interpretable alternative to end-to-end LLMs for context-sensitive moral prediction and explanation.
Semantic Deception: When Reasoning Models Can't Compute an Addition
Dec 23, 2025Large language models (LLMs) are increasingly used in situations where human values are at stake, such as decision-making tasks that involve reasoning when performed by humans. We investigate the so-called reasoning capabilities of LLMs over novel symbolic representations by introducing an experimental framework that tests their ability to process and manipulate unfamiliar symbols. We introduce semantic deceptions: situations in which symbols carry misleading semantic associations due to their form, such as being embedded in specific contexts, designed to probe whether LLMs can maintain symbolic abstraction or whether they default to exploiting learned semantic associations. We redefine standard digits and mathematical operators using novel symbols, and task LLMs with solving simple calculations expressed in this altered notation. The objective is: (1) to assess LLMs' capacity for abstraction and manipulation of arbitrary symbol systems; (2) to evaluate their ability to resist misleading semantic cues that conflict with the task's symbolic logic. Through experiments with four LLMs we show that semantic cues can significantly deteriorate reasoning models' performance on very simple tasks. They reveal limitations in current LLMs' ability for symbolic manipulations and highlight a tendency to over-rely on surface-level semantics, suggesting that chain-of-thoughts may amplify reliance on statistical correlations. Even in situations where LLMs seem to correctly follow instructions, semantic cues still impact basic capabilities. These limitations raise ethical and societal concerns, undermining the widespread and pernicious tendency to attribute reasoning abilities to LLMs and suggesting how LLMs might fail, in particular in decision-making contexts where robust symbolic reasoning is essential and should not be compromised by residual semantic associations inherited from the model's training.
Strong and weak alignment of large language models with human values
Aug 05, 2024Minimizing negative impacts of Artificial Intelligent (AI) systems on human societies without human supervision requires them to be able to align with human values. However, most current work only addresses this issue from a technical point of view, e.g., improving current methods relying on reinforcement learning from human feedback, neglecting what it means and is required for alignment to occur. Here, we propose to distinguish strong and weak value alignment. Strong alignment requires cognitive abilities (either human-like or different from humans) such as understanding and reasoning about agents' intentions and their ability to causally produce desired effects. We argue that this is required for AI systems like large language models (LLMs) to be able to recognize situations presenting a risk that human values may be flouted. To illustrate this distinction, we present a series of prompts showing ChatGPT's, Gemini's and Copilot's failures to recognize some of these situations. We moreover analyze word embeddings to show that the nearest neighbors of some human values in LLMs differ from humans' semantic representations. We then propose a new thought experiment that we call "the Chinese room with a word transition dictionary", in extension of John Searle's famous proposal. We finally mention current promising research directions towards a weak alignment, which could produce statistically satisfying answers in a number of common situations, however so far without ensuring any truth value.
Automated Driving Without Ethics: Meaning, Design and Real-World Implementation
Aug 09, 2023

The ethics of automated vehicles (AV) has received a great amount of attention in recent years, specifically in regard to their decisional policies in accident situations in which human harm is a likely consequence. After a discussion about the pertinence and cogency of the term 'artificial moral agent' to describe AVs that would accomplish these sorts of decisions, and starting from the assumption that human harm is unavoidable in some situations, a strategy for AV decision making is proposed using only pre-defined parameters to characterize the risk of possible accidents and also integrating the Ethical Valence Theory, which paints AV decision-making as a type of claim mitigation, into multiple possible decision rules to determine the most suitable action given the specific environment and decision context. The goal of this approach is not to define how moral theory requires vehicles to behave, but rather to provide a computational approach that is flexible enough to accommodate a number of human 'moral positions' concerning what morality demands and what road users may expect, offering an evaluation tool for the social acceptability of an automated vehicle's decision making.
Greybox XAI: a Neural-Symbolic learning framework to produce interpretable predictions for image classification
Sep 26, 2022



Although Deep Neural Networks (DNNs) have great generalization and prediction capabilities, their functioning does not allow a detailed explanation of their behavior. Opaque deep learning models are increasingly used to make important predictions in critical environments, and the danger is that they make and use predictions that cannot be justified or legitimized. Several eXplainable Artificial Intelligence (XAI) methods that separate explanations from machine learning models have emerged, but have shortcomings in faithfulness to the model actual functioning and robustness. As a result, there is a widespread agreement on the importance of endowing Deep Learning models with explanatory capabilities so that they can themselves provide an answer to why a particular prediction was made. First, we address the problem of the lack of universal criteria for XAI by formalizing what an explanation is. We also introduced a set of axioms and definitions to clarify XAI from a mathematical perspective. Finally, we present the Greybox XAI, a framework that composes a DNN and a transparent model thanks to the use of a symbolic Knowledge Base (KB). We extract a KB from the dataset and use it to train a transparent model (i.e., a logistic regression). An encoder-decoder architecture is trained on RGB images to produce an output similar to the KB used by the transparent model. Once the two models are trained independently, they are used compositionally to form an explainable predictive model. We show how this new architecture is accurate and explainable in several datasets.
A Practical Tutorial on Explainable AI Techniques
Nov 13, 2021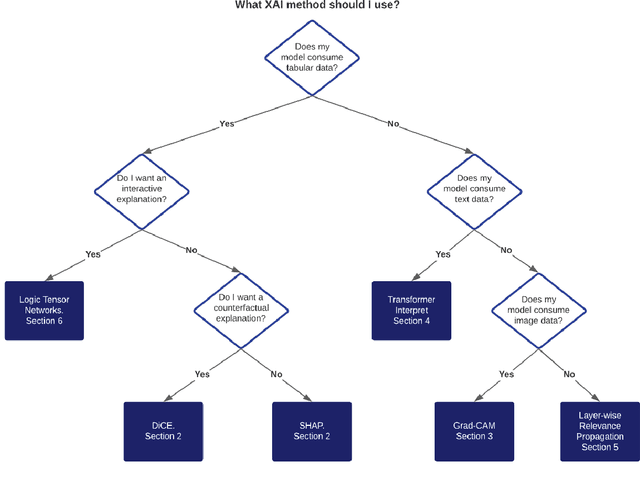
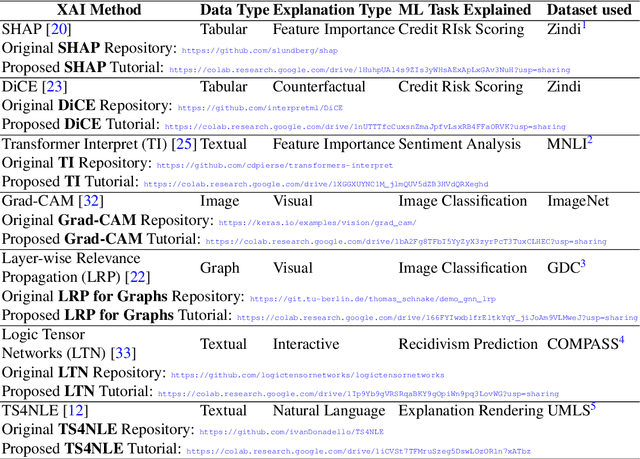
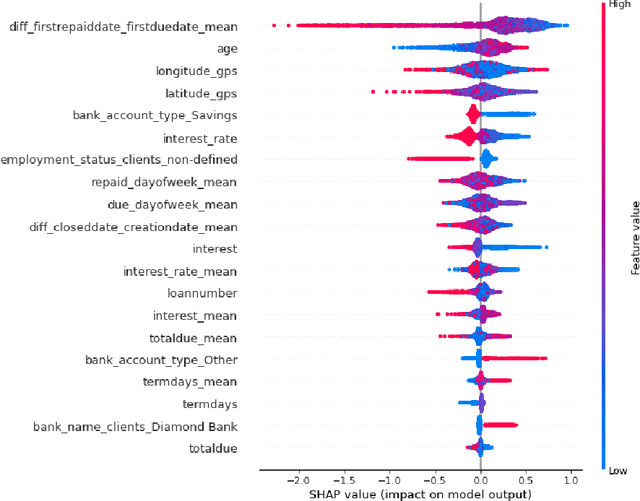
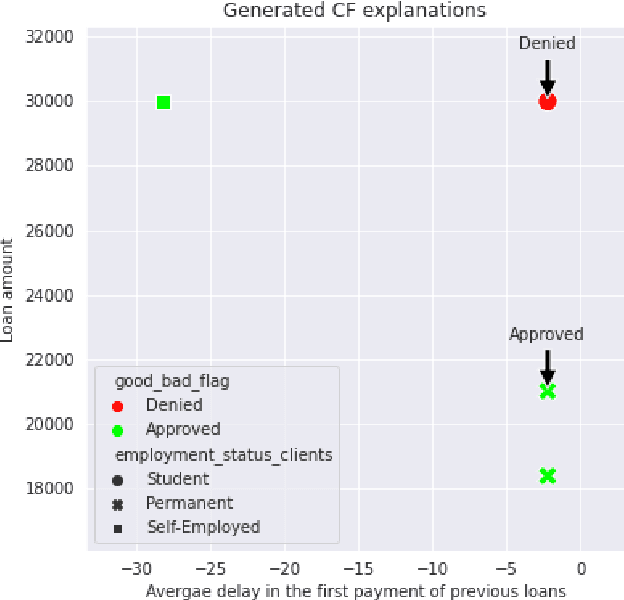
Last years have been characterized by an upsurge of opaque automatic decision support systems, such as Deep Neural Networks (DNNs). Although they have great generalization and prediction skills, their functioning does not allow obtaining detailed explanations of their behaviour. As opaque machine learning models are increasingly being employed to make important predictions in critical environments, the danger is to create and use decisions that are not justifiable or legitimate. Therefore, there is a general agreement on the importance of endowing machine learning models with explainability. The reason is that EXplainable Artificial Intelligence (XAI) techniques can serve to verify and certify model outputs and enhance them with desirable notions such as trustworthiness, accountability, transparency and fairness. This tutorial is meant to be the go-to handbook for any audience with a computer science background aiming at getting intuitive insights of machine learning models, accompanied with straight, fast, and intuitive explanations out of the box. We believe that these methods provide a valuable contribution for applying XAI techniques in their particular day-to-day models, datasets and use-cases. Figure \ref{fig:Flowchart} acts as a flowchart/map for the reader and should help him to find the ideal method to use according to his type of data. The reader will find a description of the proposed method as well as an example of use and a Python notebook that he can easily modify as he pleases in order to apply it to his own case of application.
Questioning causality on sex, gender and COVID-19, and identifying bias in large-scale data-driven analyses: the Bias Priority Recommendations and Bias Catalog for Pandemics
Apr 29, 2021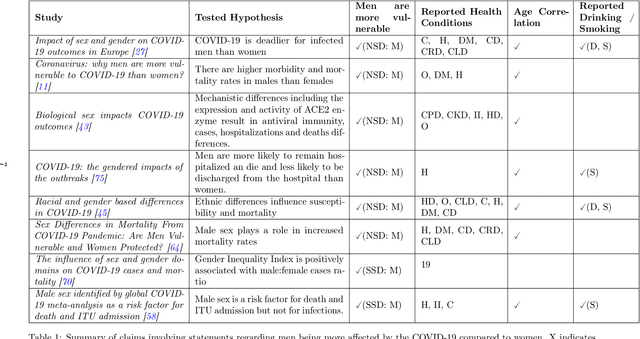
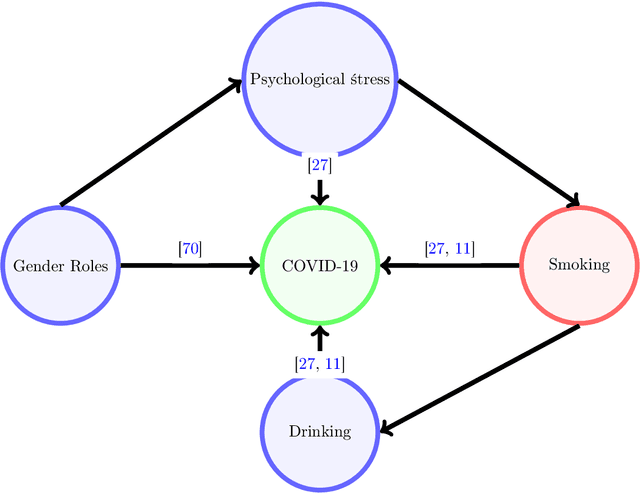

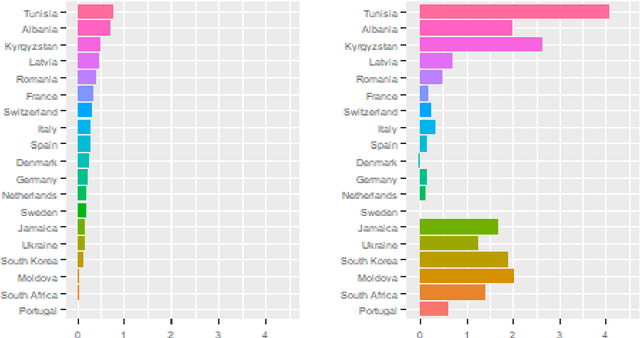
The COVID-19 pandemic has spurred a large amount of observational studies reporting linkages between the risk of developing severe COVID-19 or dying from it, and sex and gender. By reviewing a large body of related literature and conducting a fine grained analysis based on sex-disaggregated data of 61 countries spanning 5 continents, we discover several confounding factors that could possibly explain the supposed male vulnerability to COVID-19. We thus highlight the challenge of making causal claims based on available data, given the lack of statistical significance and potential existence of biases. Informed by our findings on potential variables acting as confounders, we contribute a broad overview on the issues bias, explainability and fairness entail in data-driven analyses. Thus, we outline a set of discriminatory policy consequences that could, based on such results, lead to unintended discrimination. To raise awareness on the dimensionality of such foreseen impacts, we have compiled an encyclopedia-like reference guide, the Bias Catalog for Pandemics (BCP), to provide definitions and emphasize realistic examples of bias in general, and within the COVID-19 pandemic context. These are categorized within a division of bias families and a 2-level priority scale, together with preventive steps. In addition, we facilitate the Bias Priority Recommendations on how to best use and apply this catalog, and provide guidelines in order to address real world research questions. The objective is to anticipate and avoid disparate impact and discrimination, by considering causality, explainability, bias and techniques to mitigate the latter. With these, we hope to 1) contribute to designing and conducting fair and equitable data-driven studies and research; and 2) interpret and draw meaningful and actionable conclusions from these.
Coping with the variability in humans reward during simulated human-robot interactions through the coordination of multiple learning strategies
May 06, 2020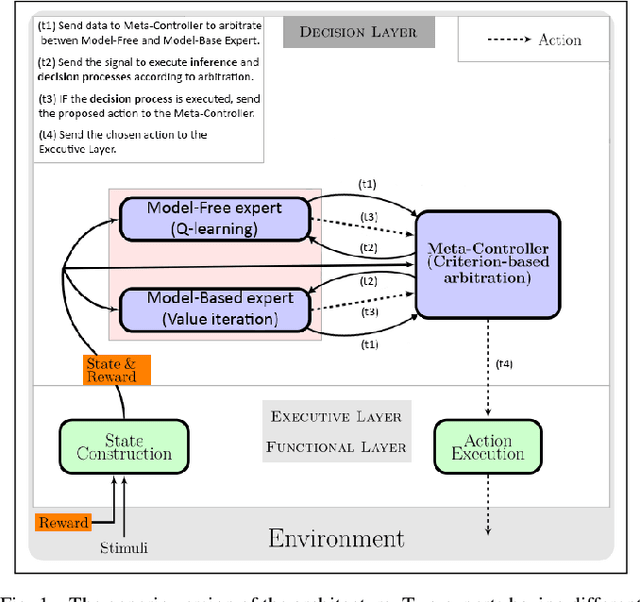
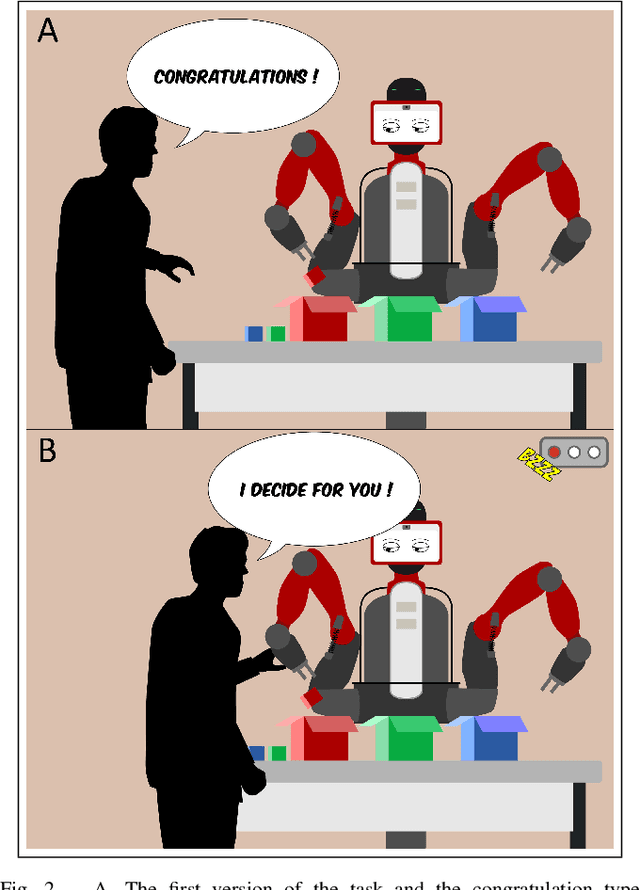
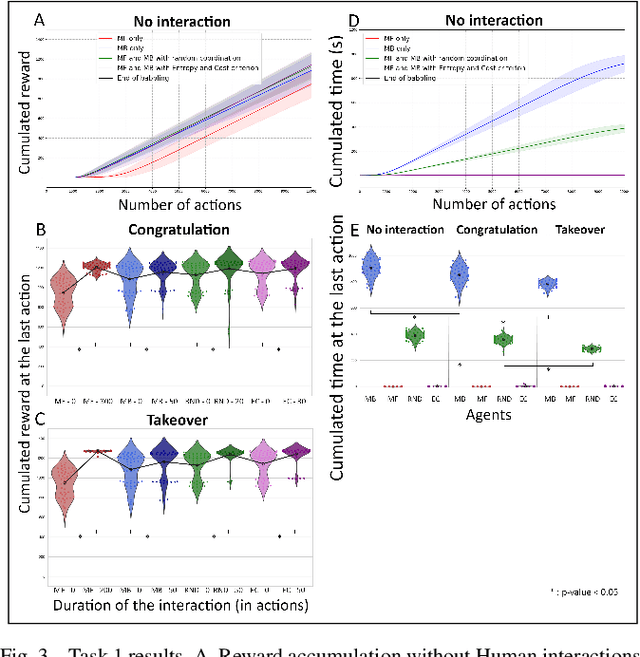
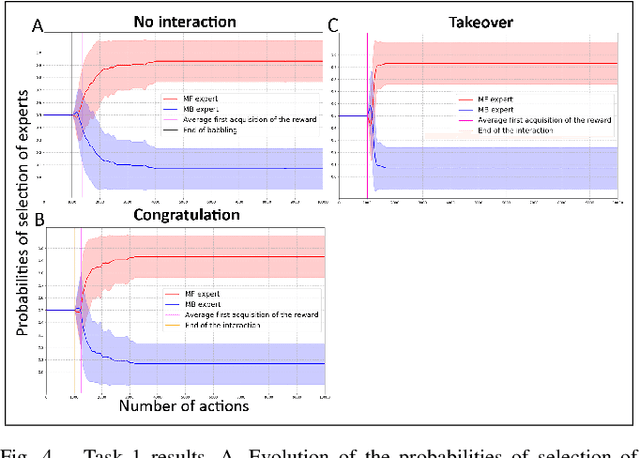
An important current challenge in Human-Robot Interaction (HRI) is to enable robots to learn on-the-fly from human feedback. However, humans show a great variability in the way they reward robots. We propose to address this issue by enabling the robot to combine different learning strategies, namely model-based (MB) and model-free (MF) reinforcement learning. We simulate two HRI scenarios: a simple task where the human congratulates the robot for putting the right cubes in the right boxes, and a more complicated version of this task where cubes have to be placed in a specific order. We show that our existing MB-MF coordination algorithm previously tested in robot navigation works well here without retuning parameters. It leads to the maximal performance while producing the same minimal computational cost as MF alone. Moreover, the algorithm gives a robust performance no matter the variability of the simulated human feedback, while each strategy alone is impacted by this variability. Overall, the results suggest a promising way to promote robot learning flexibility when facing variable human feedback.
How to reduce computation time while sparing performance during robot navigation? A neuro-inspired architecture for autonomous shifting between model-based and model-free learning
Apr 30, 2020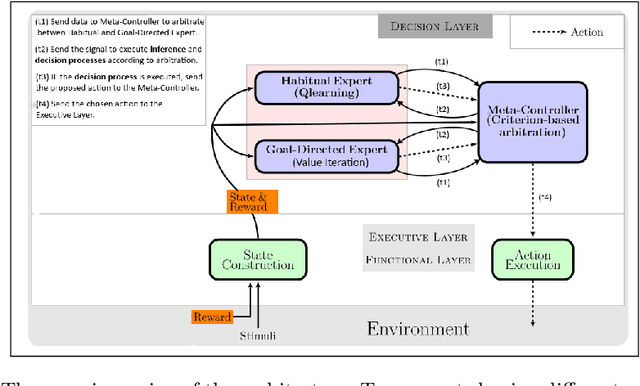
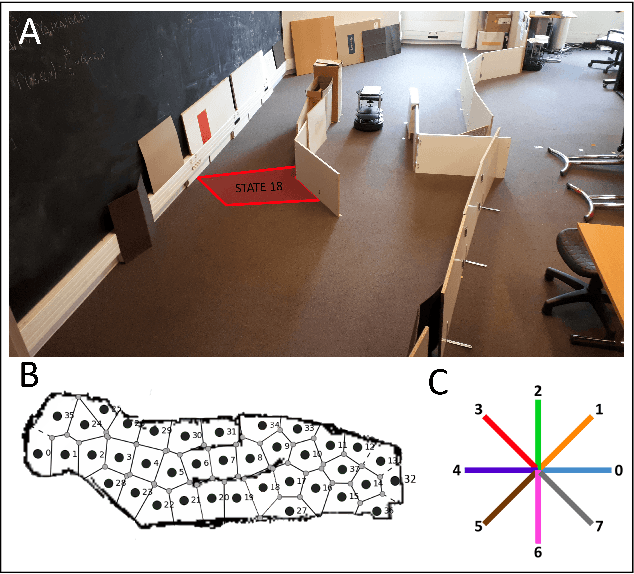
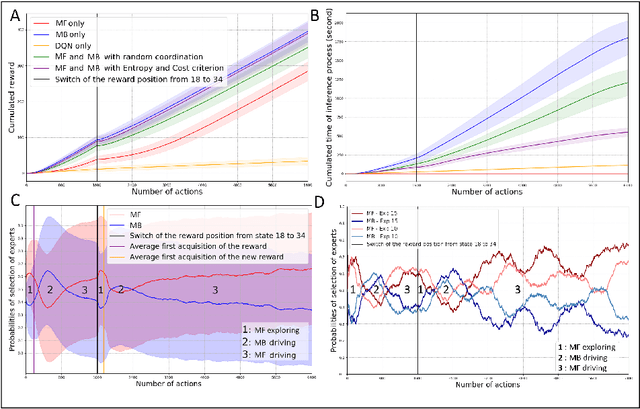
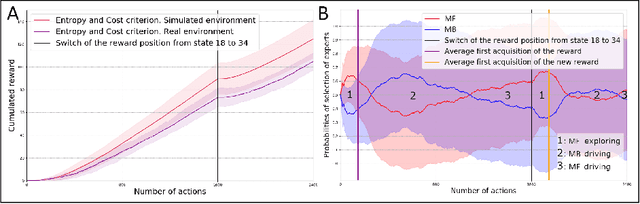
Taking inspiration from how the brain coordinates multiple learning systems is an appealing strategy to endow robots with more flexibility. One of the expected advantages would be for robots to autonomously switch to the least costly system when its performance is satisfying. However, to our knowledge no study on a real robot has yet shown that the measured computational cost is reduced while performance is maintained with such brain-inspired algorithms. We present navigation experiments involving paths of different lengths to the goal, dead-end, and non-stationarity (i.e., change in goal location and apparition of obstacles). We present a novel arbitration mechanism between learning systems that explicitly measures performance and cost. We find that the robot can adapt to environment changes by switching between learning systems so as to maintain a high performance. Moreover, when the task is stable, the robot also autonomously shifts to the least costly system, which leads to a drastic reduction in computation cost while keeping a high performance. Overall, these results illustrates the interest of using multiple learning systems.
Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible AI
Oct 22, 2019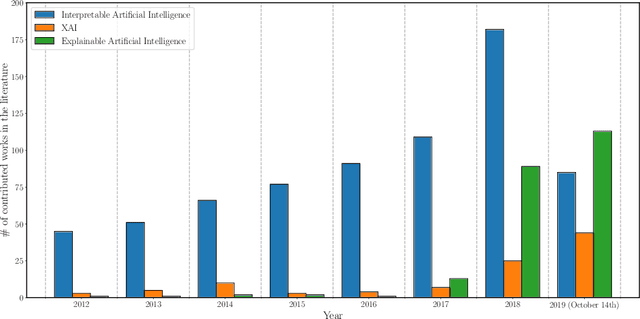
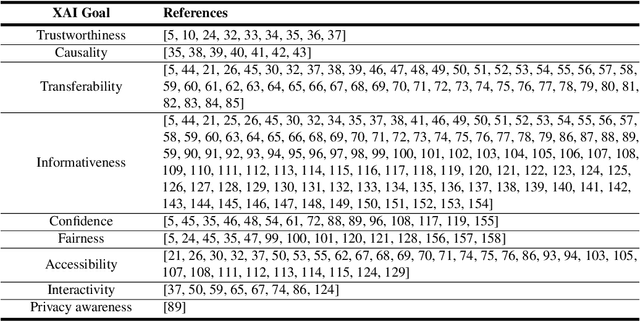

In the last years, Artificial Intelligence (AI) has achieved a notable momentum that may deliver the best of expectations over many application sectors across the field. For this to occur, the entire community stands in front of the barrier of explainability, an inherent problem of AI techniques brought by sub-symbolism (e.g. ensembles or Deep Neural Networks) that were not present in the last hype of AI. Paradigms underlying this problem fall within the so-called eXplainable AI (XAI) field, which is acknowledged as a crucial feature for the practical deployment of AI models. This overview examines the existing literature in the field of XAI, including a prospect toward what is yet to be reached. We summarize previous efforts to define explainability in Machine Learning, establishing a novel definition that covers prior conceptual propositions with a major focus on the audience for which explainability is sought. We then propose and discuss about a taxonomy of recent contributions related to the explainability of different Machine Learning models, including those aimed at Deep Learning methods for which a second taxonomy is built. This literature analysis serves as the background for a series of challenges faced by XAI, such as the crossroads between data fusion and explainability. Our prospects lead toward the concept of Responsible Artificial Intelligence, namely, a methodology for the large-scale implementation of AI methods in real organizations with fairness, model explainability and accountability at its core. Our ultimate goal is to provide newcomers to XAI with a reference material in order to stimulate future research advances, but also to encourage experts and professionals from other disciplines to embrace the benefits of AI in their activity sectors, without any prior bias for its lack of interpretability.