 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDREAM Architecture: a Developmental Approach to Open-Ended Learning in Robotics
May 13, 2020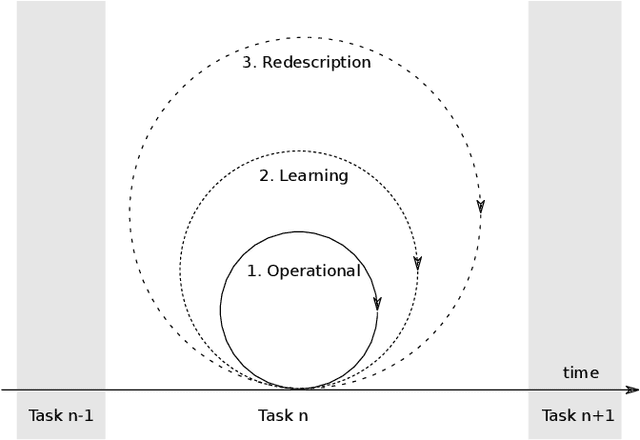
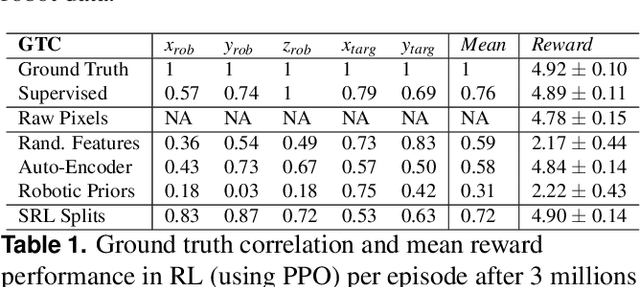
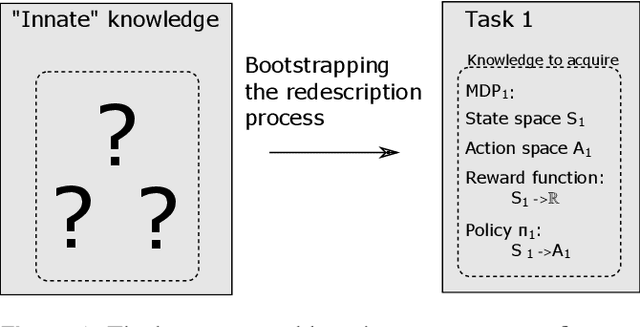
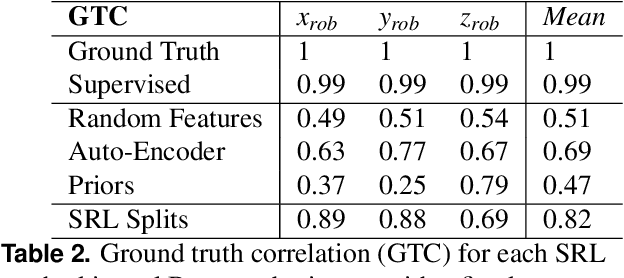
Robots are still limited to controlled conditions, that the robot designer knows with enough details to endow the robot with the appropriate models or behaviors. Learning algorithms add some flexibility with the ability to discover the appropriate behavior given either some demonstrations or a reward to guide its exploration with a reinforcement learning algorithm. Reinforcement learning algorithms rely on the definition of state and action spaces that define reachable behaviors. Their adaptation capability critically depends on the representations of these spaces: small and discrete spaces result in fast learning while large and continuous spaces are challenging and either require a long training period or prevent the robot from converging to an appropriate behavior. Beside the operational cycle of policy execution and the learning cycle, which works at a slower time scale to acquire new policies, we introduce the redescription cycle, a third cycle working at an even slower time scale to generate or adapt the required representations to the robot, its environment and the task. We introduce the challenges raised by this cycle and we present DREAM (Deferred Restructuring of Experience in Autonomous Machines), a developmental cognitive architecture to bootstrap this redescription process stage by stage, build new state representations with appropriate motivations, and transfer the acquired knowledge across domains or tasks or even across robots. We describe results obtained so far with this approach and end up with a discussion of the questions it raises in Neuroscience.
Coping with the variability in humans reward during simulated human-robot interactions through the coordination of multiple learning strategies
May 06, 2020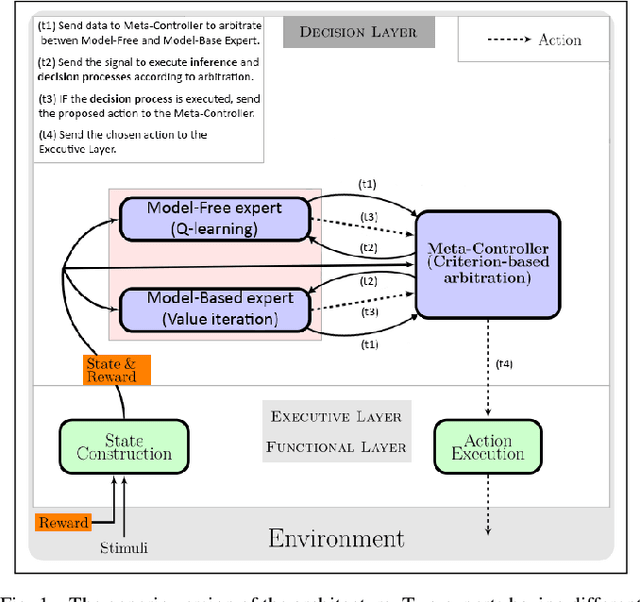
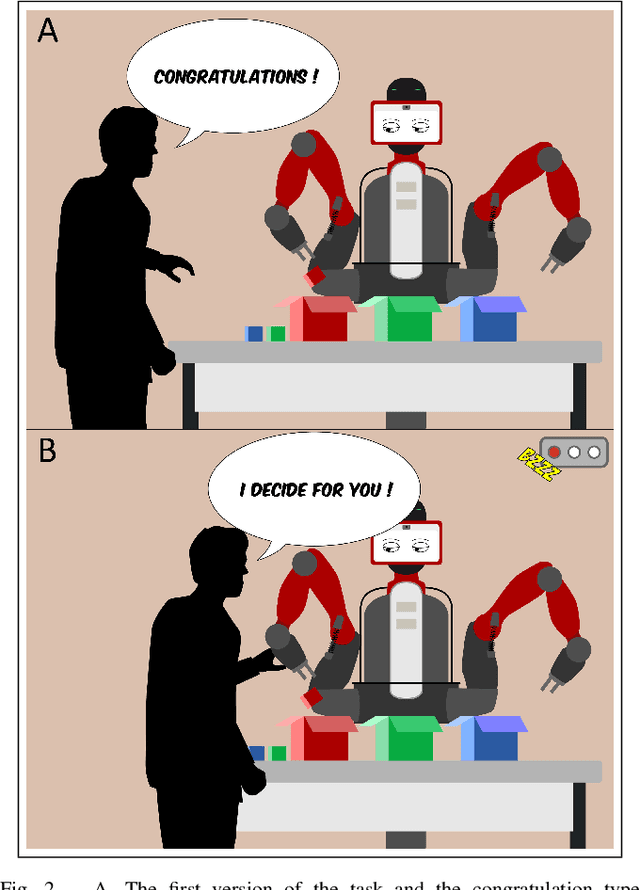
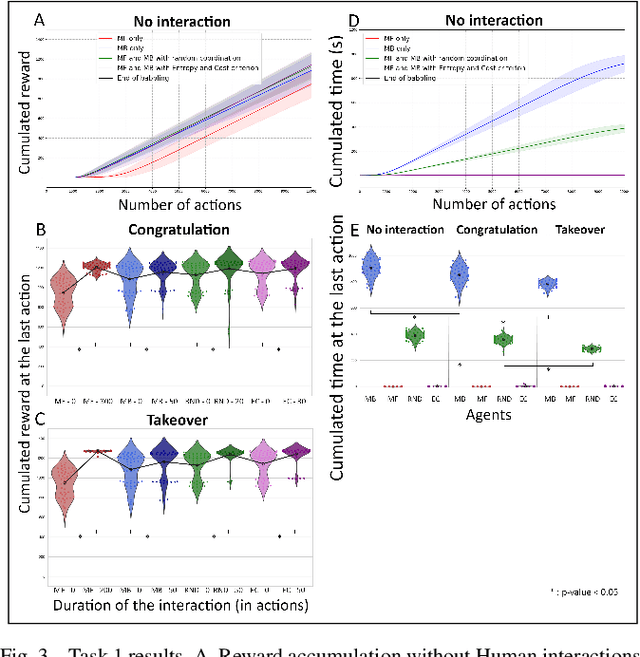
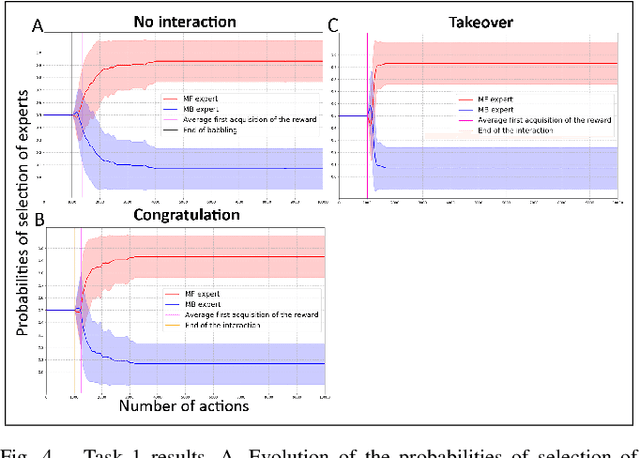
An important current challenge in Human-Robot Interaction (HRI) is to enable robots to learn on-the-fly from human feedback. However, humans show a great variability in the way they reward robots. We propose to address this issue by enabling the robot to combine different learning strategies, namely model-based (MB) and model-free (MF) reinforcement learning. We simulate two HRI scenarios: a simple task where the human congratulates the robot for putting the right cubes in the right boxes, and a more complicated version of this task where cubes have to be placed in a specific order. We show that our existing MB-MF coordination algorithm previously tested in robot navigation works well here without retuning parameters. It leads to the maximal performance while producing the same minimal computational cost as MF alone. Moreover, the algorithm gives a robust performance no matter the variability of the simulated human feedback, while each strategy alone is impacted by this variability. Overall, the results suggest a promising way to promote robot learning flexibility when facing variable human feedback.
How to reduce computation time while sparing performance during robot navigation? A neuro-inspired architecture for autonomous shifting between model-based and model-free learning
Apr 30, 2020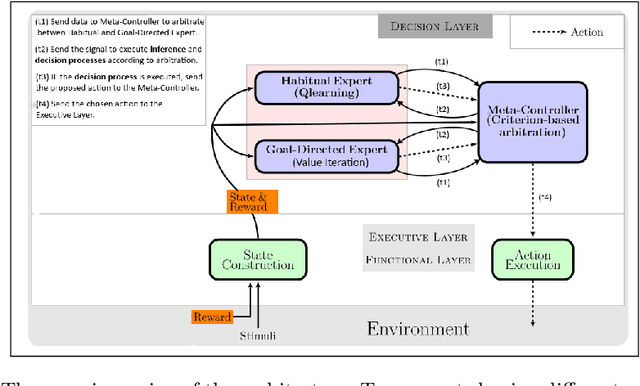
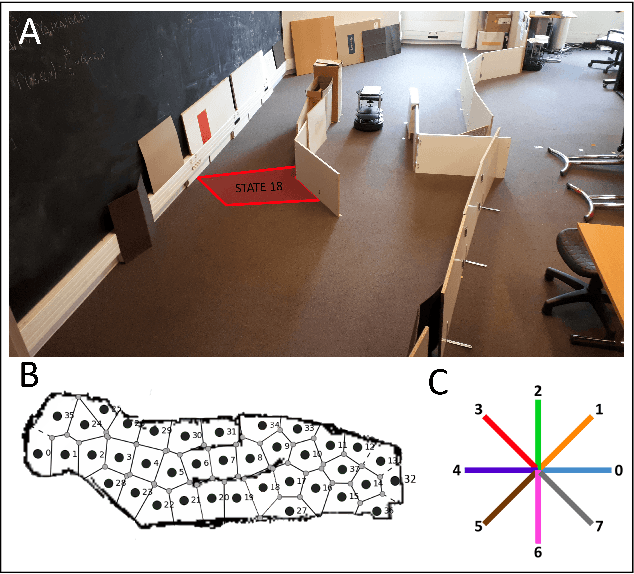
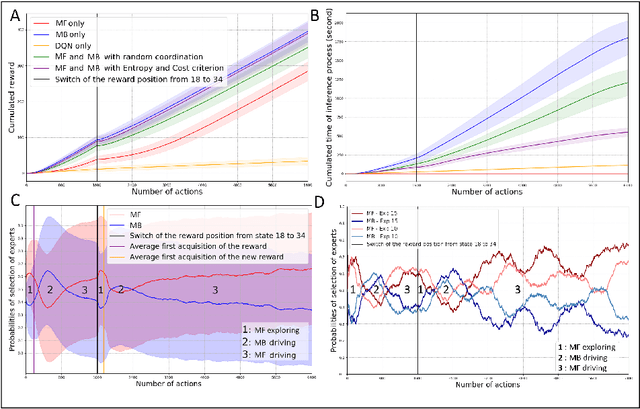
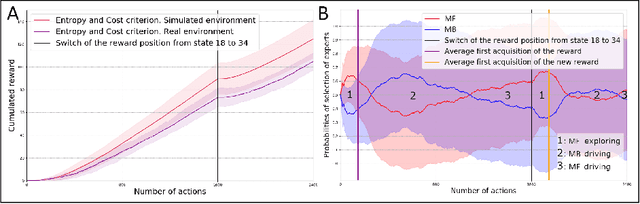
Taking inspiration from how the brain coordinates multiple learning systems is an appealing strategy to endow robots with more flexibility. One of the expected advantages would be for robots to autonomously switch to the least costly system when its performance is satisfying. However, to our knowledge no study on a real robot has yet shown that the measured computational cost is reduced while performance is maintained with such brain-inspired algorithms. We present navigation experiments involving paths of different lengths to the goal, dead-end, and non-stationarity (i.e., change in goal location and apparition of obstacles). We present a novel arbitration mechanism between learning systems that explicitly measures performance and cost. We find that the robot can adapt to environment changes by switching between learning systems so as to maintain a high performance. Moreover, when the task is stable, the robot also autonomously shifts to the least costly system, which leads to a drastic reduction in computation cost while keeping a high performance. Overall, these results illustrates the interest of using multiple learning systems.
Prioritized Sweeping Neural DynaQ with Multiple Predecessors, and Hippocampal Replays
Aug 13, 2018
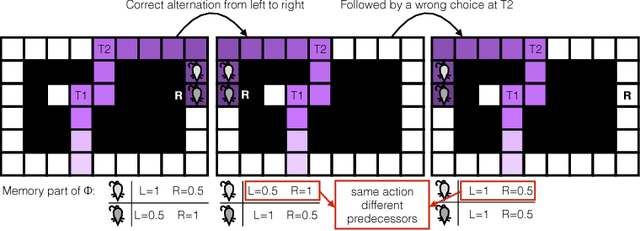

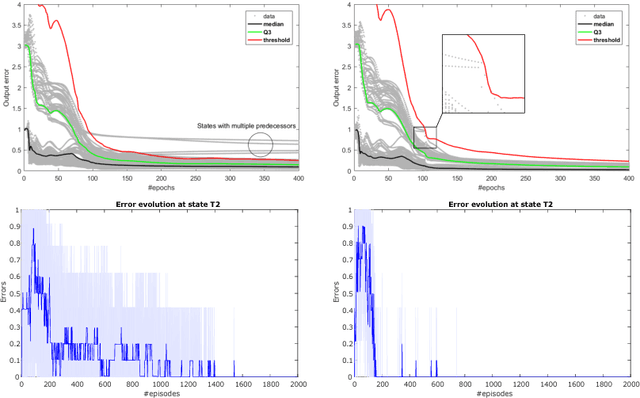
During sleep and awake rest, the hippocampus replays sequences of place cells that have been activated during prior experiences. These have been interpreted as a memory consolidation process, but recent results suggest a possible interpretation in terms of reinforcement learning. The Dyna reinforcement learning algorithms use off-line replays to improve learning. Under limited replay budget, a prioritized sweeping approach, which requires a model of the transitions to the predecessors, can be used to improve performance. We investigate whether such algorithms can explain the experimentally observed replays. We propose a neural network version of prioritized sweeping Q-learning, for which we developed a growing multiple expert algorithm, able to cope with multiple predecessors. The resulting architecture is able to improve the learning of simulated agents confronted to a navigation task. We predict that, in animals, learning the world model should occur during rest periods, and that the corresponding replays should be shuffled.
Adaptive coordination of working-memory and reinforcement learning in non-human primates performing a trial-and-error problem solving task
Nov 02, 2017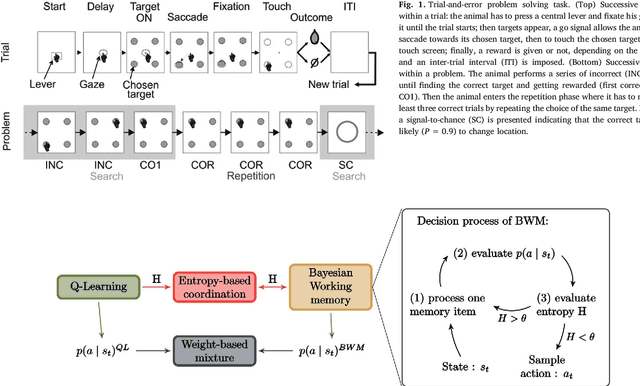
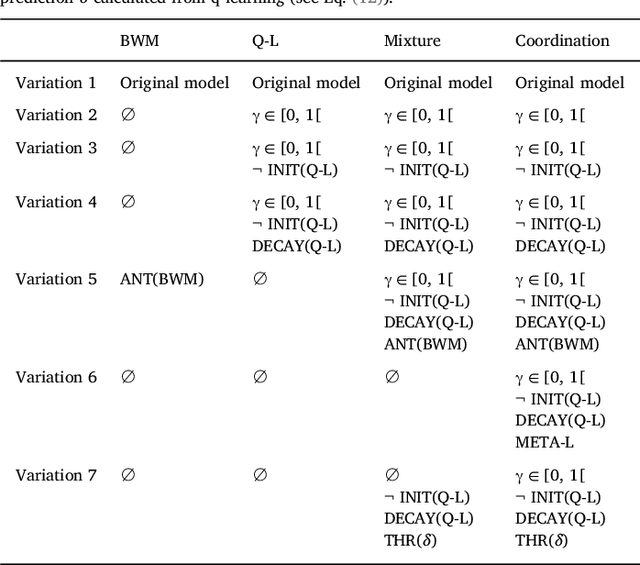
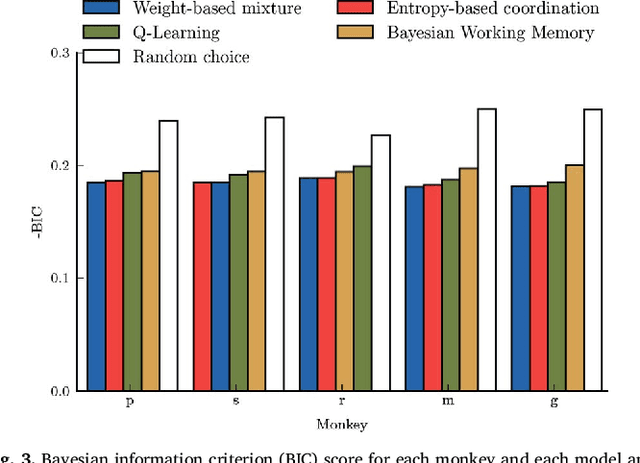
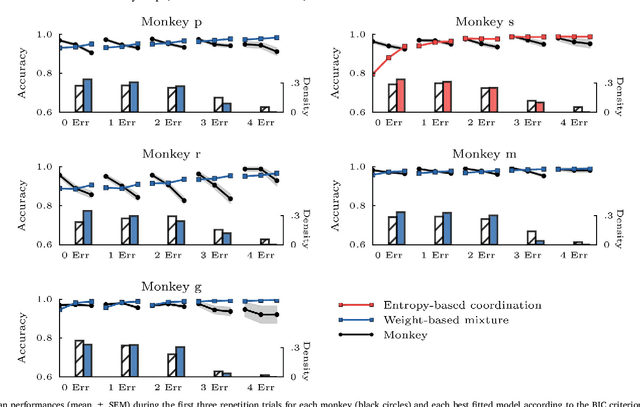
Accumulating evidence suggest that human behavior in trial-and-error learning tasks based on decisions between discrete actions may involve a combination of reinforcement learning (RL) and working-memory (WM). While the understanding of brain activity at stake in this type of tasks often involve the comparison with non-human primate neurophysiological results, it is not clear whether monkeys use similar combined RL and WM processes to solve these tasks. Here we analyzed the behavior of five monkeys with computational models combining RL and WM. Our model-based analysis approach enables to not only fit trial-by-trial choices but also transient slowdowns in reaction times, indicative of WM use. We found that the behavior of the five monkeys was better explained in terms of a combination of RL and WM despite inter-individual differences. The same coordination dynamics we used in a previous study in humans best explained the behavior of some monkeys while the behavior of others showed the opposite pattern, revealing a possible different dynamics of WM process. We further analyzed different variants of the tested models to open a discussion on how the long pretraining in these tasks may have favored particular coordination dynamics between RL and WM. This points towards either inter-species differences or protocol differences which could be further tested in humans.
A biologically constrained model of the whole basal ganglia addressing the paradoxes of connections and selection
Aug 27, 2015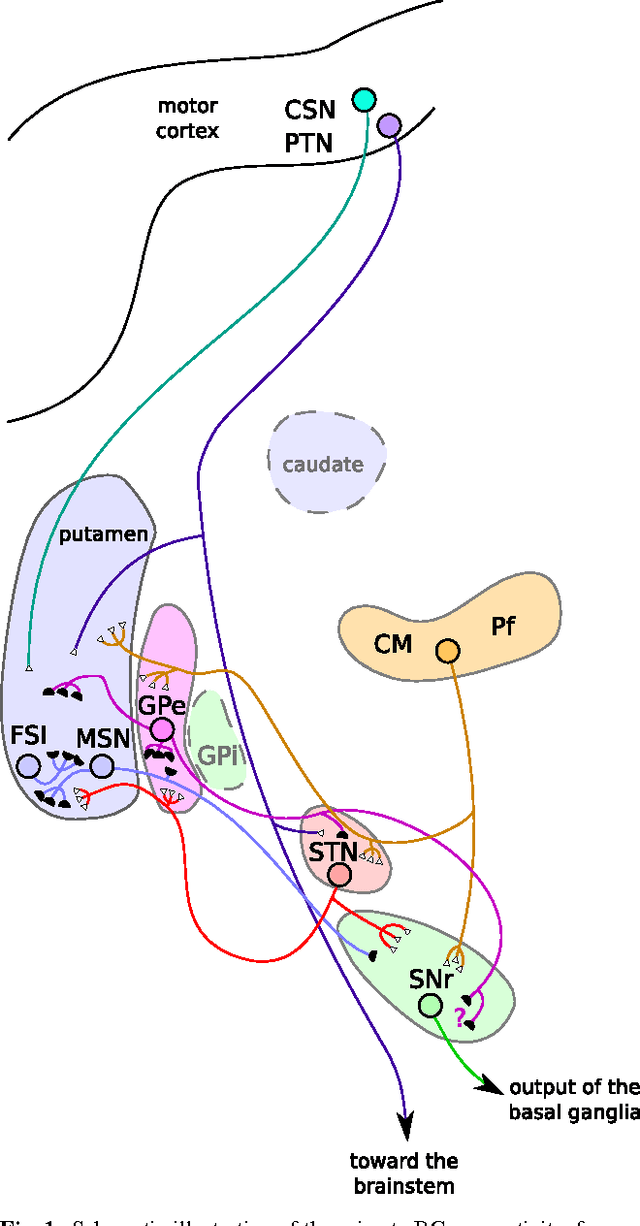
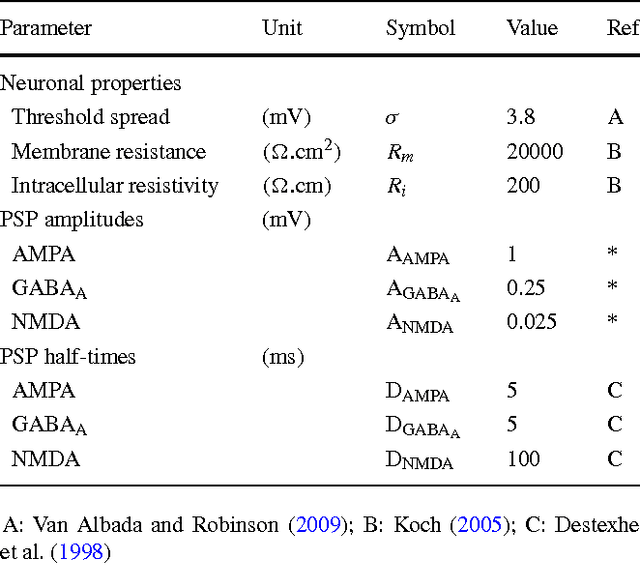
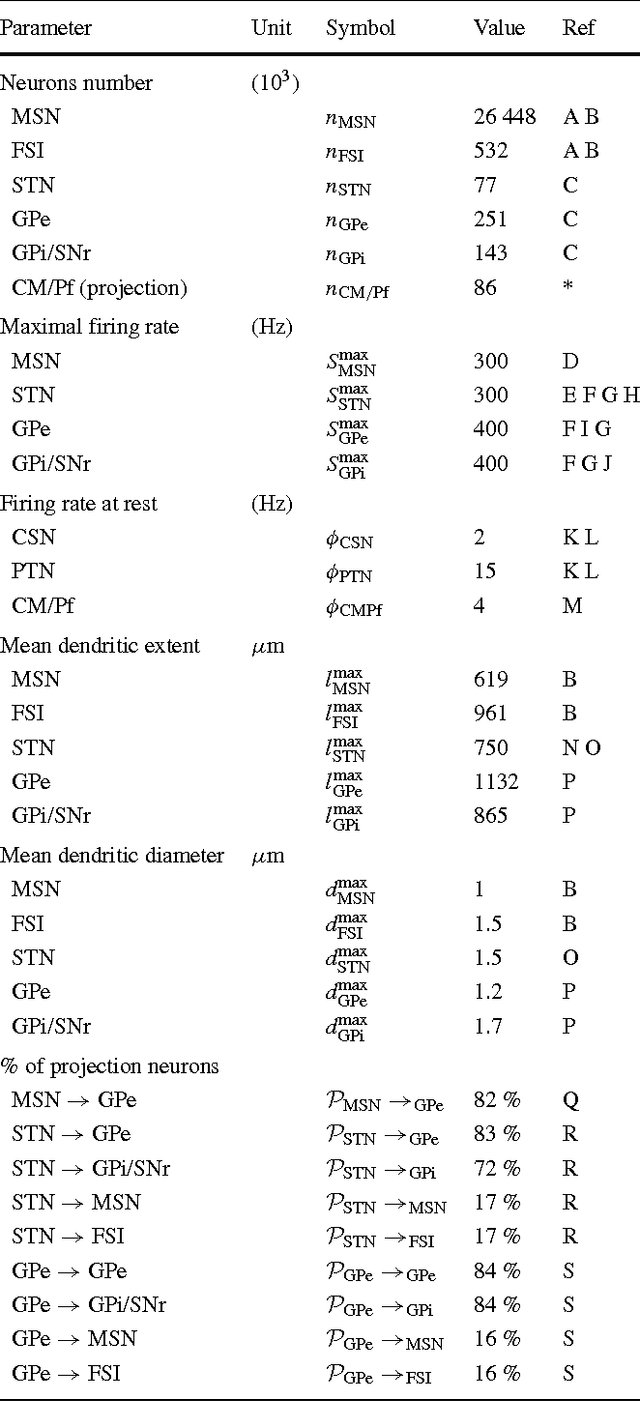

The basal ganglia nuclei form a complex network of nuclei often assumed to perform selection, yet their individual roles and how they influence each other is still largely unclear. In particular, the ties between the external and internal parts of the globus pallidus are paradoxical, as anatomical data suggest a potent inhibitory projection between them while electrophys-iological recordings indicate that they have similar activities. Here we introduce a theoretical study that reconciles both views on the intra-pallidal projection, by providing a plausible characterization of the relationship between the external and internal globus pallidus. Specifically, we developed a mean-field model of the whole basal ganglia, whose parameterization is optimized to respect best a collection of numerous anatomical and electrophysiological data. We first obtained models respecting all our constraints, hence anatomical and electrophysiological data on the intrapallidal projection are globally consistent. This model furthermore predicts that both aforementioned views about the intra-pallidal projection may be reconciled when this projection is weakly inhibitory, thus making it possible to support similar neural activity in both nuclei and for the entire basal ganglia to select between actions. Second, we predicts that afferent projections are substantially unbalanced towards the external segment, as it receives the strongest excitation from STN and the weakest inhibition from the striatum. Finally, our study strongly suggest that the intrapallidal connection pattern is not focused but diffuse, as this latter pattern is more efficient for the overall selection performed in the basal ganglia.
* \<http://link.springer.com/article/10.1007%2Fs10827-013-0476-2\>. \<10.1007/s10827-013-0476-2\>
Multi-objective analysis of computational models
Jul 24, 2015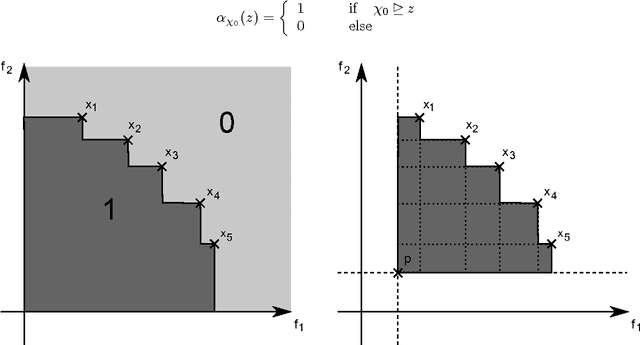
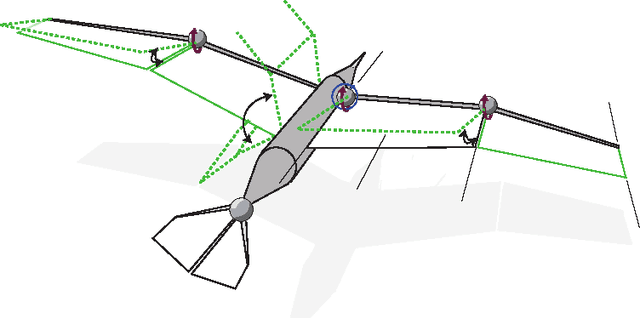
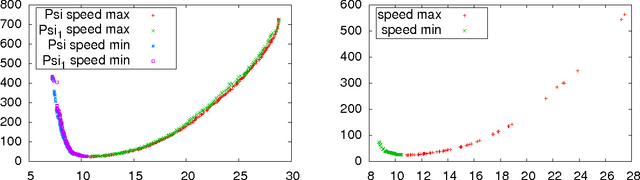
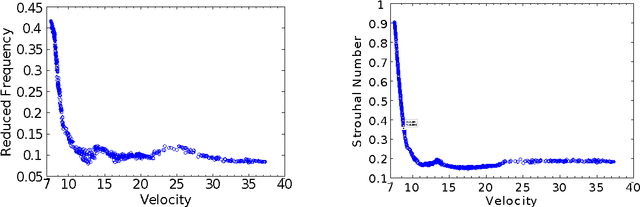
Computational models are of increasing complexity and their behavior may in particular emerge from the interaction of different parts. Studying such models becomes then more and more difficult and there is a need for methods and tools supporting this process. Multi-objective evolutionary algorithms generate a set of trade-off solutions instead of a single optimal solution. The availability of a set of solutions that have the specificity to be optimal relative to carefully chosen objectives allows to perform data mining in order to better understand model features and regularities. We review the corresponding work, propose a unifying framework, and highlight its potential use. Typical questions that such a methodology allows to address are the following: what are the most critical parameters of the model? What are the relations between the parameters and the objectives? What are the typical behaviors of the model? Two examples are provided to illustrate the capabilities of the methodology. The features of a flapping-wing robot are thus evaluated to find out its speed-energy relation, together with the criticality of its parameters. A neurocomputational model of the Basal Ganglia brain nuclei is then considered and its most salient features according to this methodology are presented and discussed.
Integration of navigation and action selection functionalities in a computational model of cortico-basal ganglia-thalamo-cortical loops
Jan 03, 2006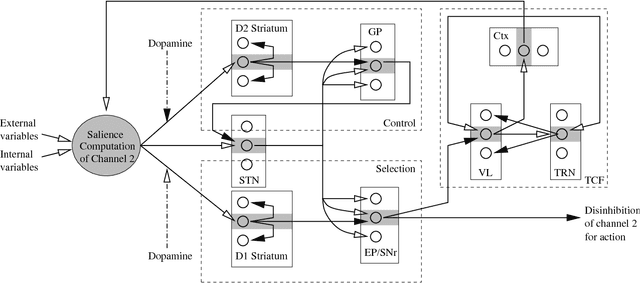
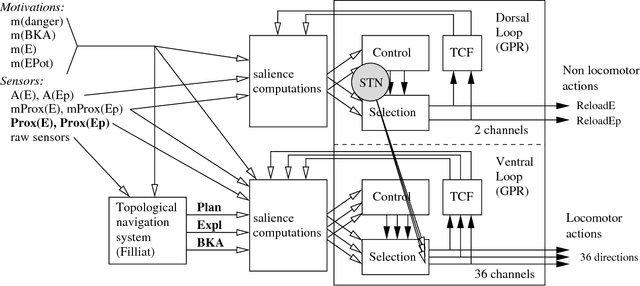
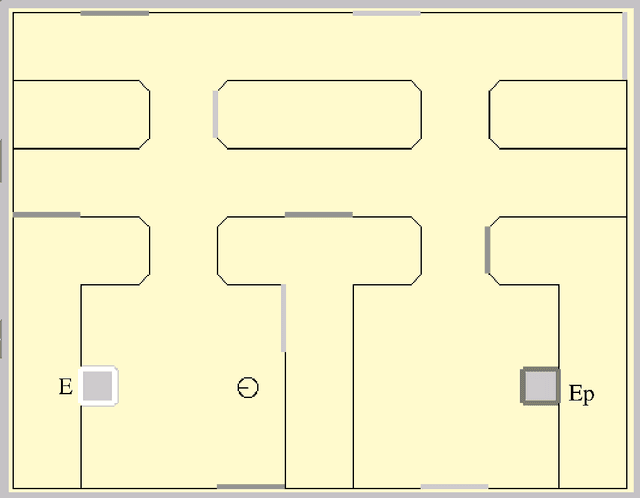
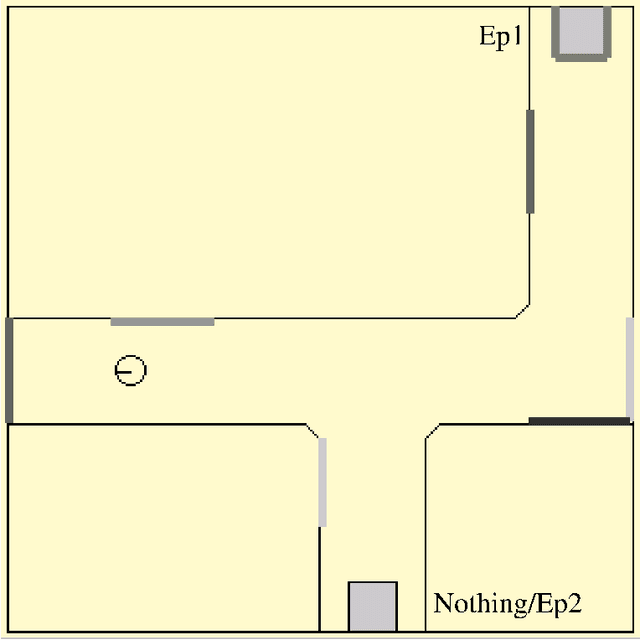
This article describes a biomimetic control architecture affording an animat both action selection and navigation functionalities. It satisfies the survival constraint of an artificial metabolism and supports several complementary navigation strategies. It builds upon an action selection model based on the basal ganglia of the vertebrate brain, using two interconnected cortico-basal ganglia-thalamo-cortical loops: a ventral one concerned with appetitive actions and a dorsal one dedicated to consummatory actions. The performances of the resulting model are evaluated in simulation. The experiments assess the prolonged survival permitted by the use of high level navigation strategies and the complementarity of navigation strategies in dynamic environments. The correctness of the behavioral choices in situations of antagonistic or synergetic internal states are also tested. Finally, the modelling choices are discussed with regard to their biomimetic plausibility, while the experimental results are estimated in terms of animat adaptivity.