 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract-QD Framework: A Generic Approach for Quality-Diversity in Noisy, Stochastic or Uncertain Domains
Feb 10, 2025



Quality-Diversity (QD) has demonstrated potential in discovering collections of diverse solutions to optimisation problems. Originally designed for deterministic environments, QD has been extended to noisy, stochastic, or uncertain domains through various Uncertain-QD (UQD) methods. However, the large number of UQD methods, each with unique constraints, makes selecting the most suitable one challenging. To remedy this situation, we present two contributions: first, the Extract-QD Framework (EQD Framework), and second, Extract-ME (EME), a new method derived from it. The EQD Framework unifies existing approaches within a modular view, and facilitates developing novel methods by interchanging modules. We use it to derive EME, a novel method that consistently outperforms or matches the best existing methods on standard benchmarks, while previous methods show varying performance. In a second experiment, we show how our EQD Framework can be used to augment existing QD algorithms and in particular the well-established Policy-Gradient-Assisted-MAP-Elites method, and demonstrate improved performance in uncertain domains at no additional evaluation cost. For any new uncertain task, our contributions now provide EME as a reliable "first guess" method, and the EQD Framework as a tool for developing task-specific approaches. Together, these contributions aim to lower the cost of adopting UQD insights in QD applications.
Task-Aware Robotic Grasping by evaluating Quality Diversity Solutions through Foundation Models
Nov 22, 2024Task-aware robotic grasping is a challenging problem that requires the integration of semantic understanding and geometric reasoning. Traditional grasp planning approaches focus on stable or feasible grasps, often disregarding the specific tasks the robot needs to accomplish. This paper proposes a novel framework that leverages Large Language Models (LLMs) and Quality Diversity (QD) algorithms to enable zero-shot task-conditioned grasp selection. The framework segments objects into meaningful subparts and labels each subpart semantically, creating structured representations that can be used to prompt an LLM. By coupling semantic and geometric representations of an object's structure, the LLM's knowledge about tasks and which parts to grasp can be applied in the physical world. The QD-generated grasp archive provides a diverse set of grasps, allowing us to select the most suitable grasp based on the task. We evaluate the proposed method on a subset of the YCB dataset, where a Franka Emika robot is assigned to perform various actions based on object-specific task requirements. We created a ground truth by conducting a survey with six participants to determine the best grasp region for each task-object combination according to human intuition. The model was evaluated on 12 different objects across 4--7 object-specific tasks, achieving a weighted intersection over union (IoU) of 76.4% when compared to the survey data.
A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
Nov 02, 2023A lot of recent machine learning research papers have "Open-ended learning" in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with these previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to always produce novel elements from time to time over an infinite horizon. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems, as this framework facilitates the definition of learning a growing repertoire of skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
Integrating LLMs and Decision Transformers for Language Grounded Generative Quality-Diversity
Aug 25, 2023Quality-Diversity is a branch of stochastic optimization that is often applied to problems from the Reinforcement Learning and control domains in order to construct repertoires of well-performing policies/skills that exhibit diversity with respect to a behavior space. Such archives are usually composed of a finite number of reactive agents which are each associated to a unique behavior descriptor, and instantiating behavior descriptors outside of that coarsely discretized space is not straight-forward. While a few recent works suggest solutions to that issue, the trajectory that is generated is not easily customizable beyond the specification of a target behavior descriptor. We propose to jointly solve those problems in environments where semantic information about static scene elements is available by leveraging a Large Language Model to augment the repertoire with natural language descriptions of trajectories, and training a policy conditioned on those descriptions. Thus, our method allows a user to not only specify an arbitrary target behavior descriptor, but also provide the model with a high-level textual prompt to shape the generated trajectory. We also propose an LLM-based approach to evaluating the performance of such generative agents. Furthermore, we develop a benchmark based on simulated robot navigation in a 2d maze that we use for experimental validation.
Data-efficient, Explainable and Safe Payload Manipulation: An Illustration of the Advantages of Physical Priors in Model-Predictive Control
Mar 02, 2023Machine Learning methods, such as those from the Reinforcement Learning (RL) literature, have increasingly been applied to robot control problems. However, such control methods, even when learning environment dynamics (e.g. as in Model-Based RL/control) often remain data-inefficient. Furthermore, the decisions made by learned policies or the estimations made by learned dynamic models, unlike those made by their hand-designed counterparts, are not readily interpretable by a human user without the use of Explainable AI techniques. This has several disadvantages, such as increased difficulty both in debugging and integration in safety-critical systems. On the other hand, in many robotic systems, prior knowledge of environment kinematics and dynamics is at least partially available (e.g. from classical mechanics). Arguably, incorporating such priors to the environment model or decision process can help address the aforementioned problems: it reduces problem complexity and the needs in terms of exploration, while also facilitating the expression of the decisions taken by the agent in terms of physically meaningful entities. Our aim with this paper is to illustrate and support this point of view. We model a payload manipulation problem based on a real robotic system, and show that leveraging prior knowledge about the dynamics of the environment can lead to improved explainability and an increase in both safety and data-efficiency,leading to satisfying generalization properties with less data.
E2R: a Hierarchical-Learning inspired Novelty-Search method to generate diverse repertoires of grasping trajectories
Oct 14, 2022



Robotics grasping refers to the task of making a robotic system pick an object by applying forces and torques on its surface. Despite the recent advances in data-driven approaches, grasping remains an unsolved problem. Most of the works on this task are relying on priors and heavy constraints to avoid the exploration problem. Novelty Search (NS) refers to evolutionary algorithms that replace selection of best performing individuals with selection of the most novel ones. Such methods have already shown promising results on hard exploration problems. In this work, we introduce a new NS-based method that can generate large datasets of grasping trajectories in a platform-agnostic manner. Inspired by the hierarchical learning paradigm, our method decouples approach and prehension to make the behavioral space smoother. Experiments conducted on 3 different robot-gripper setups and on several standard objects shows that our method outperforms state-of-the-art for generating diverse repertoire of grasping trajectories, getting a higher successful run ratio, as well as a better diversity for both approach and prehension. Some of the generated solutions have been successfully deployed on a real robot, showing the exploitability of the obtained repertoires.
Meta Neural Ordinary Differential Equations For Adaptive Asynchronous Control
Jul 25, 2022

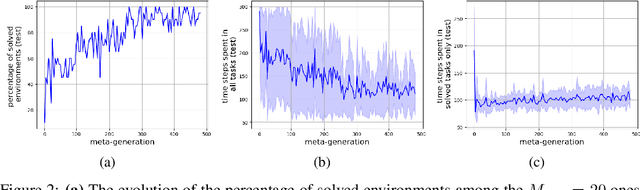
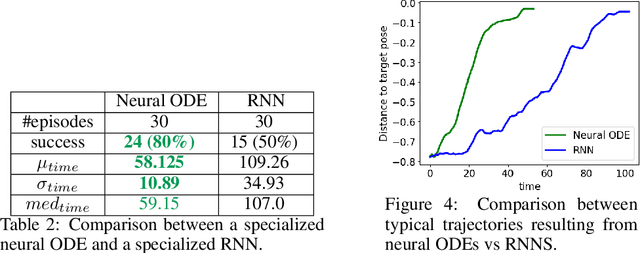
Model-based Reinforcement Learning and Control have demonstrated great potential in various sequential decision making problem domains, including in robotics settings. However, real-world robotics systems often present challenges that limit the applicability of those methods. In particular, we note two problems that jointly happen in many industrial systems: 1) Irregular/asynchronous observations and actions and 2) Dramatic changes in environment dynamics from an episode to another (e.g. varying payload inertial properties). We propose a general framework that overcomes those difficulties by meta-learning adaptive dynamics models for continuous-time prediction and control. We evaluate the proposed approach on a simulated industrial robot. Evaluations on real robotic systems will be added in future iterations of this pre-print.
Towards QD-suite: developing a set of benchmarks for Quality-Diversity algorithms
May 06, 2022



While the field of Quality-Diversity (QD) has grown into a distinct branch of stochastic optimization, a few problems, in particular locomotion and navigation tasks, have become de facto standards. Are such benchmarks sufficient? Are they representative of the key challenges faced by QD algorithms? Do they provide the ability to focus on one particular challenge by properly disentangling it from others? Do they have much predictive power in terms of scalability and generalization? Existing benchmarks are not standardized, and there is currently no MNIST equivalent for QD. Inspired by recent works on Reinforcement Learning benchmarks, we argue that the identification of challenges faced by QD methods and the development of targeted, challenging, scalable but affordable benchmarks is an important step. As an initial effort, we identify three problems that are challenging in sparse reward settings, and propose associated benchmarks: (1) Behavior metric bias, which can result from the use of metrics that do not match the structure of the behavior space. (2) Behavioral Plateaus, with varying characteristics, such that escaping them would require adaptive QD algorithms and (3) Evolvability Traps, where small variations in genotype result in large behavioral changes. The environments that we propose satisfy the properties listed above.
Geodesics, Non-linearities and the Archive of Novelty Search
May 06, 2022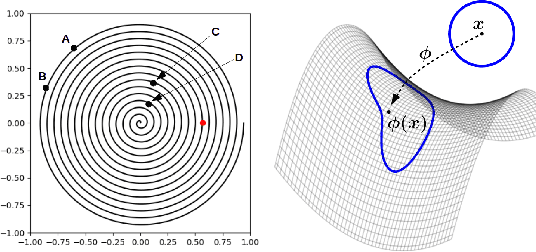


The Novelty Search (NS) algorithm was proposed more than a decade ago. However, the mechanisms behind its empirical success are still not well formalized/understood. This short note focuses on the effects of the archive on exploration. Experimental evidence from a few application domains suggests that archive-based NS performs in general better than when Novelty is solely computed with respect to the population. An argument that is often encountered in the literature is that the archive prevents exploration from backtracking or cycling, i.e. from revisiting previously encountered areas in the behavior space. We argue that this is not a complete or accurate explanation as backtracking - beside often being desirable - can actually be enabled by the archive. Through low-dimensional/analytical examples, we show that a key effect of the archive is that it counterbalances the exploration biases that result, among other factors, from the use of inadequate behavior metrics and the non-linearities of the behavior mapping. Our observations seem to hint that attributing a more active role to the archive in sampling can be beneficial.
* 4 pages, 3 figures
Discovering and Exploiting Sparse Rewards in a Learned Behavior Space
Nov 02, 2021



Learning optimal policies in sparse rewards settings is difficult as the learning agent has little to no feedback on the quality of its actions. In these situations, a good strategy is to focus on exploration, hopefully leading to the discovery of a reward signal to improve on. A learning algorithm capable of dealing with this kind of settings has to be able to (1) explore possible agent behaviors and (2) exploit any possible discovered reward. Efficient exploration algorithms have been proposed that require to define a behavior space, that associates to an agent its resulting behavior in a space that is known to be worth exploring. The need to define this space is a limitation of these algorithms. In this work, we introduce STAX, an algorithm designed to learn a behavior space on-the-fly and to explore it while efficiently optimizing any reward discovered. It does so by separating the exploration and learning of the behavior space from the exploitation of the reward through an alternating two-steps process. In the first step, STAX builds a repertoire of diverse policies while learning a low-dimensional representation of the high-dimensional observations generated during the policies evaluation. In the exploitation step, emitters are used to optimize the performance of the discovered rewarding solutions. Experiments conducted on three different sparse reward environments show that STAX performs comparably to existing baselines while requiring much less prior information about the task as it autonomously builds the behavior space.