 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-Shot Offline RL via Behavioral Task Sampling
Apr 28, 2026Offline zero-shot reinforcement learning (RL) aims to learn agents that optimize unseen reward functions without additional environment interaction. The standard approach to this problem trains task-conditioned policies by sampling task vectors that define linear reward functions over learned state representations. In most existing algorithms, these task vectors are randomly sampled, implicitly assuming this adequately captures the structure of the task space. We argue that doing so leads to suboptimal zero-shot generalization. To address this limitation, we propose extracting task vectors directly from the offline dataset and using them to define the task distribution used for policy training. We introduce a simple and general reward function extraction procedure that integrates into existing offline zero-shot RL algorithms. Across multiple benchmark environments and baselines, our approach improves zero-shot performance by an average of 20%, highlighting the importance of principled task sampling in offline zero-shot RL.
Variance-Reduced Model Predictive Path Integral via Quadratic Model Approximation
Feb 03, 2026Sampling-based controllers, such as Model Predictive Path Integral (MPPI) methods, offer substantial flexibility but often suffer from high variance and low sample efficiency. To address these challenges, we introduce a hybrid variance-reduced MPPI framework that integrates a prior model into the sampling process. Our key insight is to decompose the objective function into a known approximate model and a residual term. Since the residual captures only the discrepancy between the model and the objective, it typically exhibits a smaller magnitude and lower variance than the original objective. Although this principle applies to general modeling choices, we demonstrate that adopting a quadratic approximation enables the derivation of a closed-form, model-guided prior that effectively concentrates samples in informative regions. Crucially, the framework is agnostic to the source of geometric information, allowing the quadratic model to be constructed from exact derivatives, structural approximations (e.g., Gauss- or Quasi-Newton), or gradient-free randomized smoothing. We validate the approach on standard optimization benchmarks, a nonlinear, underactuated cart-pole control task, and a contact-rich manipulation problem with non-smooth dynamics. Across these domains, we achieve faster convergence and superior performance in low-sample regimes compared to standard MPPI. These results suggest that the method can make sample-based control strategies more practical in scenarios where obtaining samples is expensive or limited.
Learning to explore when mistakes are not allowed
Feb 19, 2025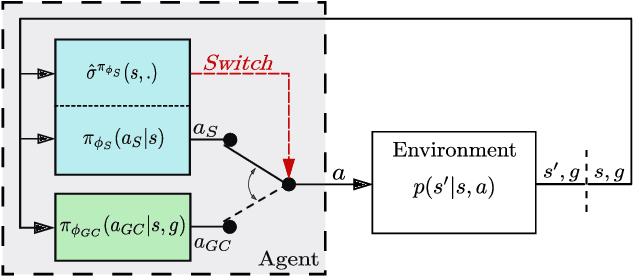

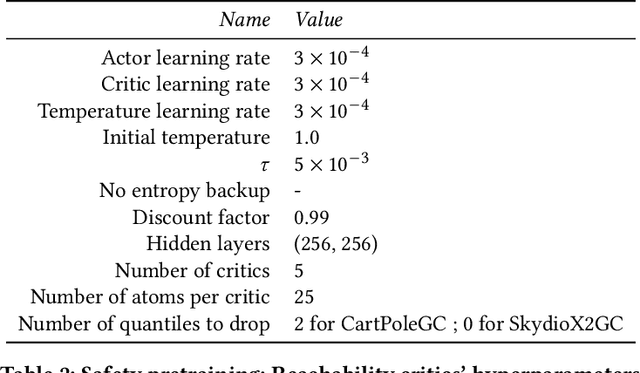
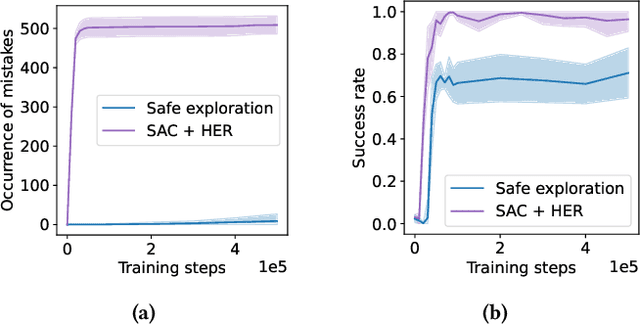
Goal-Conditioned Reinforcement Learning (GCRL) provides a versatile framework for developing unified controllers capable of handling wide ranges of tasks, exploring environments, and adapting behaviors. However, its reliance on trial-and-error poses challenges for real-world applications, as errors can result in costly and potentially damaging consequences. To address the need for safer learning, we propose a method that enables agents to learn goal-conditioned behaviors that explore without the risk of making harmful mistakes. Exploration without risks can seem paradoxical, but environment dynamics are often uniform in space, therefore a policy trained for safety without exploration purposes can still be exploited globally. Our proposed approach involves two distinct phases. First, during a pretraining phase, we employ safe reinforcement learning and distributional techniques to train a safety policy that actively tries to avoid failures in various situations. In the subsequent safe exploration phase, a goal-conditioned (GC) policy is learned while ensuring safety. To achieve this, we implement an action-selection mechanism leveraging the previously learned distributional safety critics to arbitrate between the safety policy and the GC policy, ensuring safe exploration by switching to the safety policy when needed. We evaluate our method in simulated environments and demonstrate that it not only provides substantial coverage of the goal space but also reduces the occurrence of mistakes to a minimum, in stark contrast to traditional GCRL approaches. Additionally, we conduct an ablation study and analyze failure modes, offering insights for future research directions.
AFU: Actor-Free critic Updates in off-policy RL for continuous control
Apr 24, 2024
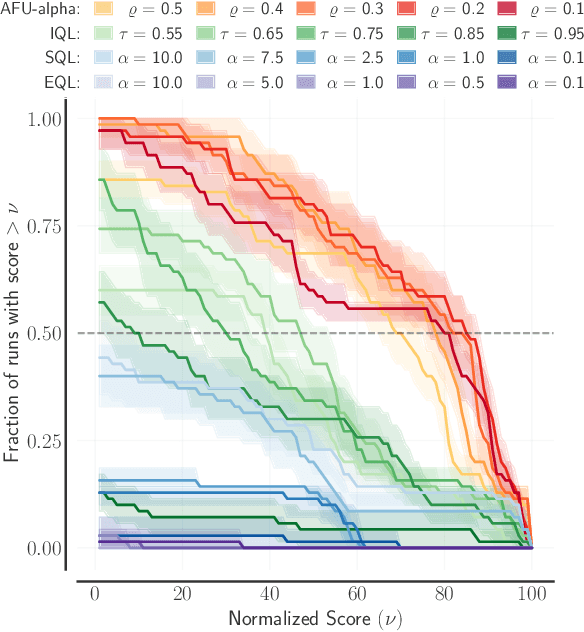
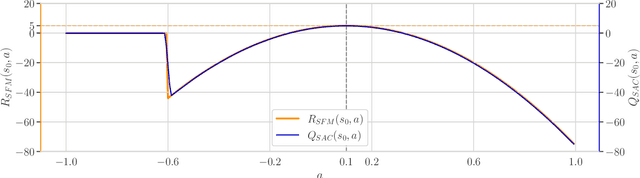

This paper presents AFU, an off-policy deep RL algorithm addressing in a new way the challenging "max-Q problem" in Q-learning for continuous action spaces, with a solution based on regression and conditional gradient scaling. AFU has an actor but its critic updates are entirely independent from it. As a consequence, the actor can be chosen freely. In the initial version, AFU-alpha, we employ the same stochastic actor as in Soft Actor-Critic (SAC), but we then study a simple failure mode of SAC and show how AFU can be modified to make actor updates less likely to become trapped in local optima, resulting in a second version of the algorithm, AFU-beta. Experimental results demonstrate the sample efficiency of both versions of AFU, marking it as the first model-free off-policy algorithm competitive with state-of-the-art actor-critic methods while departing from the actor-critic perspective.
$Γ$-VAE: Curvature regularized variational autoencoders for uncovering emergent low dimensional geometric structure in high dimensional data
Mar 02, 2024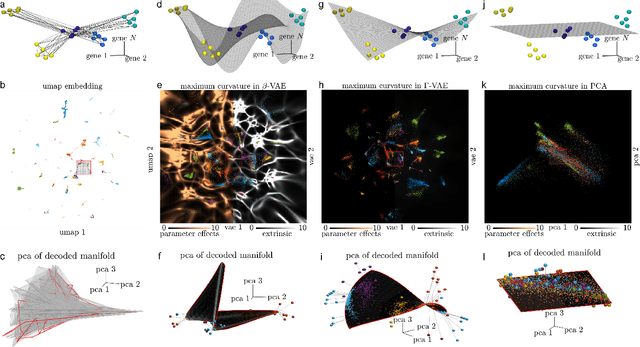
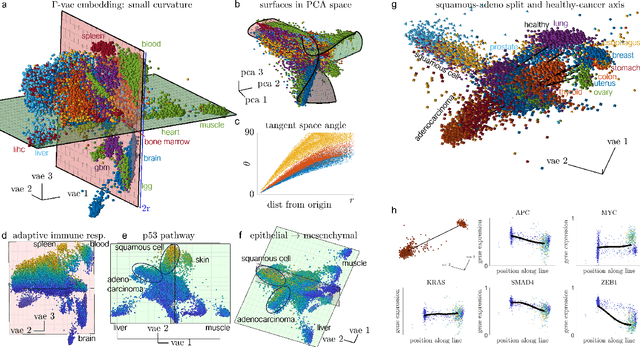
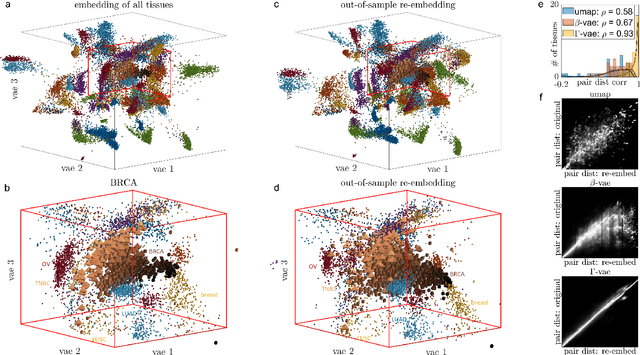

Natural systems with emergent behaviors often organize along low-dimensional subsets of high-dimensional spaces. For example, despite the tens of thousands of genes in the human genome, the principled study of genomics is fruitful because biological processes rely on coordinated organization that results in lower dimensional phenotypes. To uncover this organization, many nonlinear dimensionality reduction techniques have successfully embedded high-dimensional data into low-dimensional spaces by preserving local similarities between data points. However, the nonlinearities in these methods allow for too much curvature to preserve general trends across multiple non-neighboring data clusters, thereby limiting their interpretability and generalizability to out-of-distribution data. Here, we address both of these limitations by regularizing the curvature of manifolds generated by variational autoencoders, a process we coin ``$\Gamma$-VAE''. We demonstrate its utility using two example data sets: bulk RNA-seq from the The Cancer Genome Atlas (TCGA) and the Genotype Tissue Expression (GTEx); and single cell RNA-seq from a lineage tracing experiment in hematopoietic stem cell differentiation. We find that the resulting regularized manifolds identify mesoscale structure associated with different cancer cell types, and accurately re-embed tissues from completely unseen, out-of distribution cancers as if they were originally trained on them. Finally, we show that preserving long-range relationships to differentiated cells separates undifferentiated cells -- which have not yet specialized -- according to their eventual fate. Broadly, we anticipate that regularizing the curvature of generative models will enable more consistent, predictive, and generalizable models in any high-dimensional system with emergent low-dimensional behavior.
Single-Reset Divide & Conquer Imitation Learning
Feb 14, 2024Demonstrations are commonly used to speed up the learning process of Deep Reinforcement Learning algorithms. To cope with the difficulty of accessing multiple demonstrations, some algorithms have been developed to learn from a single demonstration. In particular, the Divide & Conquer Imitation Learning algorithms leverage a sequential bias to learn a control policy for complex robotic tasks using a single state-based demonstration. The latest version, DCIL-II demonstrates remarkable sample efficiency. This novel method operates within an extended Goal-Conditioned Reinforcement Learning framework, ensuring compatibility between intermediate and subsequent goals extracted from the demonstration. However, a fundamental limitation arises from the assumption that the system can be reset to specific states along the demonstrated trajectory, confining the application to simulated systems. In response, we introduce an extension called Single-Reset DCIL (SR-DCIL), designed to overcome this constraint by relying on a single initial state reset rather than sequential resets. To address this more challenging setting, we integrate two mechanisms inspired by the Learning from Demonstrations literature, including a Demo-Buffer and Value Cloning, to guide the agent toward compatible success states. In addition, we introduce Approximate Goal Switching to facilitate training to reach goals distant from the reset state. Our paper makes several contributions, highlighting the importance of the reset assumption in DCIL-II, presenting the mechanisms of SR-DCIL variants and evaluating their performance in challenging robotic tasks compared to DCIL-II. In summary, this work offers insights into the significance of reset assumptions in the framework of DCIL and proposes SR-DCIL, a first step toward a versatile algorithm capable of learning control policies under a weaker reset assumption.
A Definition of Open-Ended Learning Problems for Goal-Conditioned Agents
Nov 02, 2023A lot of recent machine learning research papers have "Open-ended learning" in their title. But very few of them attempt to define what they mean when using the term. Even worse, when looking more closely there seems to be no consensus on what distinguishes open-ended learning from related concepts such as continual learning, lifelong learning or autotelic learning. In this paper, we contribute to fixing this situation. After illustrating the genealogy of the concept and more recent perspectives about what it truly means, we outline that open-ended learning is generally conceived as a composite notion encompassing a set of diverse properties. In contrast with these previous approaches, we propose to isolate a key elementary property of open-ended processes, which is to always produce novel elements from time to time over an infinite horizon. From there, we build the notion of open-ended learning problems and focus in particular on the subset of open-ended goal-conditioned reinforcement learning problems, as this framework facilitates the definition of learning a growing repertoire of skills. Finally, we highlight the work that remains to be performed to fill the gap between our elementary definition and the more involved notions of open-ended learning that developmental AI researchers may have in mind.
Layered controller synthesis for dynamic multi-agent systems
Jul 13, 2023In this paper we present a layered approach for multi-agent control problem, decomposed into three stages, each building upon the results of the previous one. First, a high-level plan for a coarse abstraction of the system is computed, relying on parametric timed automata augmented with stopwatches as they allow to efficiently model simplified dynamics of such systems. In the second stage, the high-level plan, based on SMT-formulation, mainly handles the combinatorial aspects of the problem, provides a more dynamically accurate solution. These stages are collectively referred to as the SWA-SMT solver. They are correct by construction but lack a crucial feature: they cannot be executed in real time. To overcome this, we use SWA-SMT solutions as the initial training dataset for our last stage, which aims at obtaining a neural network control policy. We use reinforcement learning to train the policy, and show that the initial dataset is crucial for the overall success of the method.
The Quality-Diversity Transformer: Generating Behavior-Conditioned Trajectories with Decision Transformers
Mar 27, 2023In the context of neuroevolution, Quality-Diversity algorithms have proven effective in generating repertoires of diverse and efficient policies by relying on the definition of a behavior space. A natural goal induced by the creation of such a repertoire is trying to achieve behaviors on demand, which can be done by running the corresponding policy from the repertoire. However, in uncertain environments, two problems arise. First, policies can lack robustness and repeatability, meaning that multiple episodes under slightly different conditions often result in very different behaviors. Second, due to the discrete nature of the repertoire, solutions vary discontinuously. Here we present a new approach to achieve behavior-conditioned trajectory generation based on two mechanisms: First, MAP-Elites Low-Spread (ME-LS), which constrains the selection of solutions to those that are the most consistent in the behavior space. Second, the Quality-Diversity Transformer (QDT), a Transformer-based model conditioned on continuous behavior descriptors, which trains on a dataset generated by policies from a ME-LS repertoire and learns to autoregressively generate sequences of actions that achieve target behaviors. Results show that ME-LS produces consistent and robust policies, and that its combination with the QDT yields a single policy capable of achieving diverse behaviors on demand with high accuracy.
Assessing Quality-Diversity Neuro-Evolution Algorithms Performance in Hard Exploration Problems
Nov 24, 2022A fascinating aspect of nature lies in its ability to produce a collection of organisms that are all high-performing in their niche. Quality-Diversity (QD) methods are evolutionary algorithms inspired by this observation, that obtained great results in many applications, from wing design to robot adaptation. Recently, several works demonstrated that these methods could be applied to perform neuro-evolution to solve control problems in large search spaces. In such problems, diversity can be a target in itself. Diversity can also be a way to enhance exploration in tasks exhibiting deceptive reward signals. While the first aspect has been studied in depth in the QD community, the latter remains scarcer in the literature. Exploration is at the heart of several domains trying to solve control problems such as Reinforcement Learning and QD methods are promising candidates to overcome the challenges associated. Therefore, we believe that standardized benchmarks exhibiting control problems in high dimension with exploration difficulties are of interest to the QD community. In this paper, we highlight three candidate benchmarks and explain why they appear relevant for systematic evaluation of QD algorithms. We also provide open-source implementations in Jax allowing practitioners to run fast and numerous experiments on few compute resources.