 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein binding affinity prediction under multiple substitutions applying eGNNs on Residue and Atomic graphs combined with Language model information: eGRAL
May 03, 2024Protein-protein interactions (PPIs) play a crucial role in numerous biological processes. Developing methods that predict binding affinity changes under substitution mutations is fundamental for modelling and re-engineering biological systems. Deep learning is increasingly recognized as a powerful tool capable of bridging the gap between in-silico predictions and in-vitro observations. With this contribution, we propose eGRAL, a novel SE(3) equivariant graph neural network (eGNN) architecture designed for predicting binding affinity changes from multiple amino acid substitutions in protein complexes. eGRAL leverages residue, atomic and evolutionary scales, thanks to features extracted from protein large language models. To address the limited availability of large-scale affinity assays with structural information, we generate a simulated dataset comprising approximately 500,000 data points. Our model is pre-trained on this dataset, then fine-tuned and tested on experimental data.
Assessing Quality-Diversity Neuro-Evolution Algorithms Performance in Hard Exploration Problems
Nov 24, 2022A fascinating aspect of nature lies in its ability to produce a collection of organisms that are all high-performing in their niche. Quality-Diversity (QD) methods are evolutionary algorithms inspired by this observation, that obtained great results in many applications, from wing design to robot adaptation. Recently, several works demonstrated that these methods could be applied to perform neuro-evolution to solve control problems in large search spaces. In such problems, diversity can be a target in itself. Diversity can also be a way to enhance exploration in tasks exhibiting deceptive reward signals. While the first aspect has been studied in depth in the QD community, the latter remains scarcer in the literature. Exploration is at the heart of several domains trying to solve control problems such as Reinforcement Learning and QD methods are promising candidates to overcome the challenges associated. Therefore, we believe that standardized benchmarks exhibiting control problems in high dimension with exploration difficulties are of interest to the QD community. In this paper, we highlight three candidate benchmarks and explain why they appear relevant for systematic evaluation of QD algorithms. We also provide open-source implementations in Jax allowing practitioners to run fast and numerous experiments on few compute resources.
Fast Population-Based Reinforcement Learning on a Single Machine
Jun 17, 2022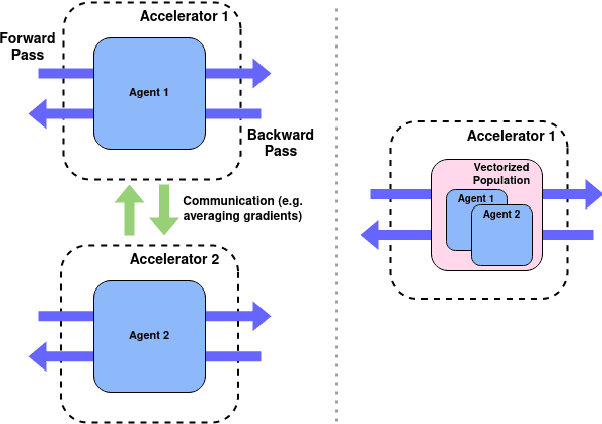

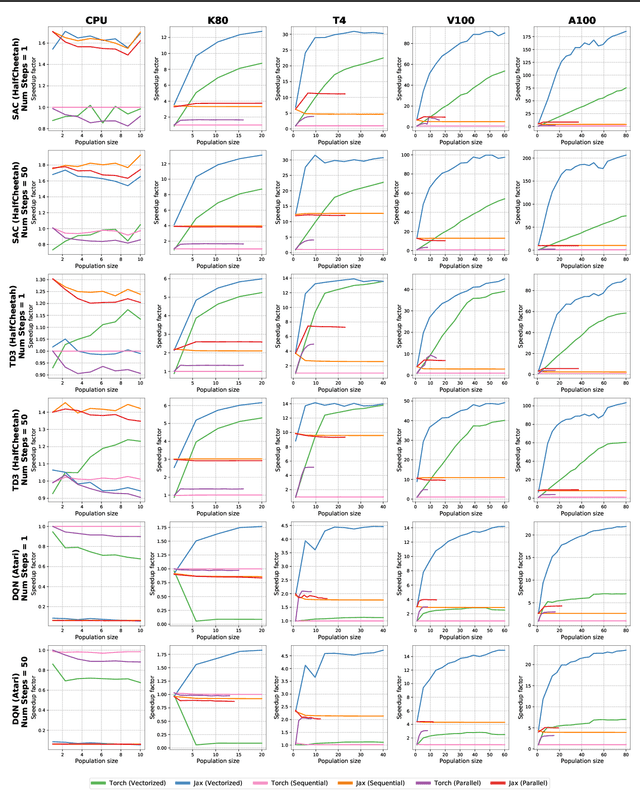

Training populations of agents has demonstrated great promise in Reinforcement Learning for stabilizing training, improving exploration and asymptotic performance, and generating a diverse set of solutions. However, population-based training is often not considered by practitioners as it is perceived to be either prohibitively slow (when implemented sequentially), or computationally expensive (if agents are trained in parallel on independent accelerators). In this work, we compare implementations and revisit previous studies to show that the judicious use of compilation and vectorization allows population-based training to be performed on a single machine with one accelerator with minimal overhead compared to training a single agent. We also show that, when provided with a few accelerators, our protocols extend to large population sizes for applications such as hyperparameter tuning. We hope that this work and the public release of our code will encourage practitioners to use population-based learning more frequently for their research and applications.
Multi-Objective Quality Diversity Optimization
Feb 07, 2022
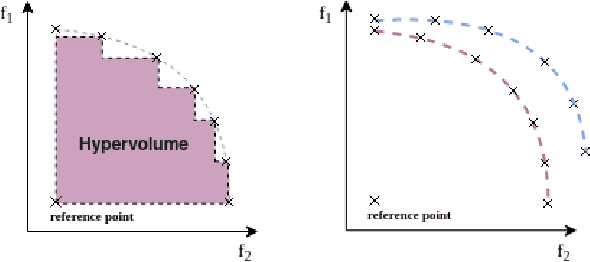


In this work, we consider the problem of Quality-Diversity (QD) optimization with multiple objectives. QD algorithms have been proposed to search for a large collection of both diverse and high-performing solutions instead of a single set of local optima. Thriving for diversity was shown to be useful in many industrial and robotics applications. On the other hand, most real-life problems exhibit several potentially antagonist objectives to be optimized. Hence being able to optimize for multiple objectives with an appropriate technique while thriving for diversity is important to many fields. Here, we propose an extension of the MAP-Elites algorithm in the multi-objective setting: Multi-Objective MAP-Elites (MOME). Namely, it combines the diversity inherited from the MAP-Elites grid algorithm with the strength of multi-objective optimizations by filling each cell with a Pareto Front. As such, it allows to extract diverse solutions in the descriptor space while exploring different compromises between objectives. We evaluate our method on several tasks, from standard optimization problems to robotics simulations. Our experimental evaluation shows the ability of MOME to provide diverse solutions while providing global performances similar to standard multi-objective algorithms.
Mava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021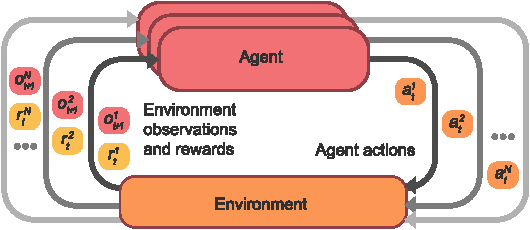
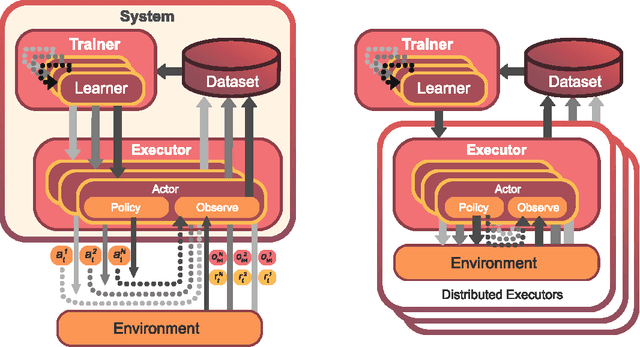
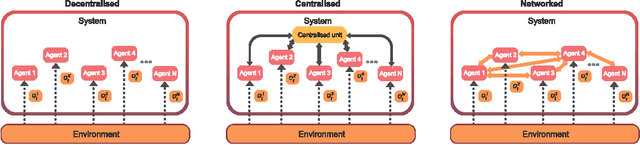

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.
Designing a Prospective COVID-19 Therapeutic with Reinforcement Learning
Dec 03, 2020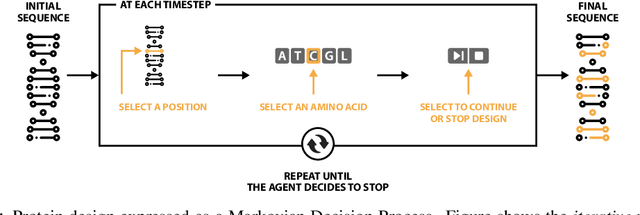
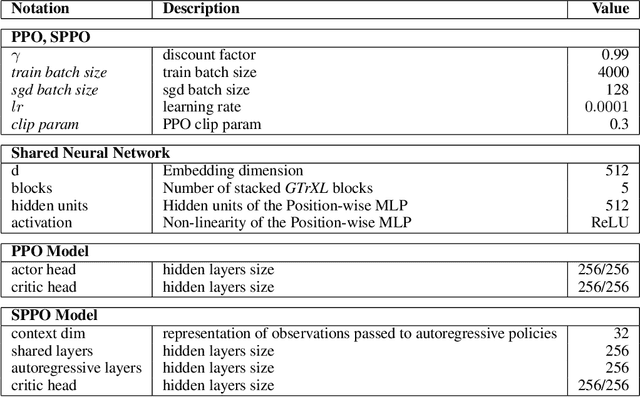
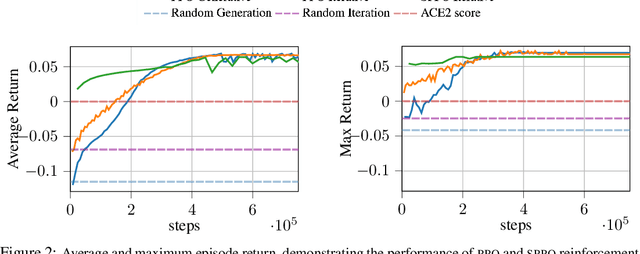
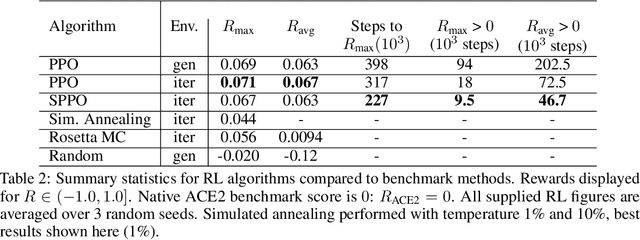
The SARS-CoV-2 pandemic has created a global race for a cure. One approach focuses on designing a novel variant of the human angiotensin-converting enzyme 2 (ACE2) that binds more tightly to the SARS-CoV-2 spike protein and diverts it from human cells. Here we formulate a novel protein design framework as a reinforcement learning problem. We generate new designs efficiently through the combination of a fast, biologically-grounded reward function and sequential action-space formulation. The use of Policy Gradients reduces the compute budget needed to reach consistent, high-quality designs by at least an order of magnitude compared to standard methods. Complexes designed by this method have been validated by molecular dynamics simulations, confirming their increased stability. This suggests that combining leading protein design methods with modern deep reinforcement learning is a viable path for discovering a Covid-19 cure and may accelerate design of peptide-based therapeutics for other diseases.
Offline Reinforcement Learning Hands-On
Nov 29, 2020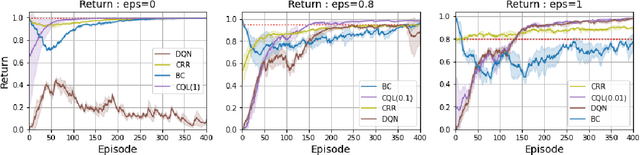

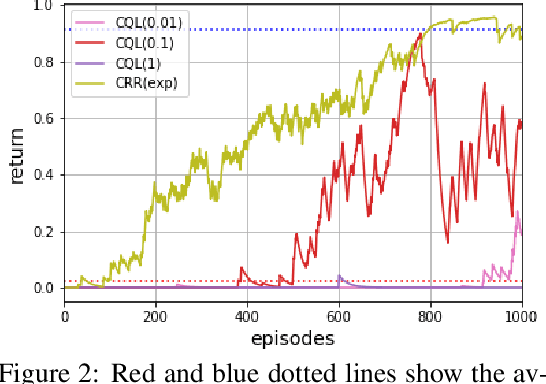

Offline Reinforcement Learning (RL) aims to turn large datasets into powerful decision-making engines without any online interactions with the environment. This great promise has motivated a large amount of research that hopes to replicate the success RL has experienced in simulation settings. This work ambitions to reflect upon these efforts from a practitioner viewpoint. We start by discussing the dataset properties that we hypothesise can characterise the type of offline methods that will be the most successful. We then verify these claims through a set of experiments and designed datasets generated from environments with both discrete and continuous action spaces. We experimentally validate that diversity and high-return examples in the data are crucial to the success of offline RL and show that behavioural cloning remains a strong contender compared to its contemporaries. Overall, this work stands as a tutorial to help people build their intuition on today's offline RL methods and their applicability.
A game-theoretic analysis of networked system control for common-pool resource management using multi-agent reinforcement learning
Oct 15, 2020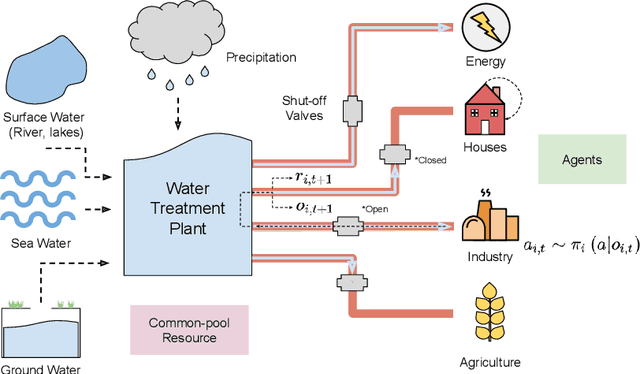
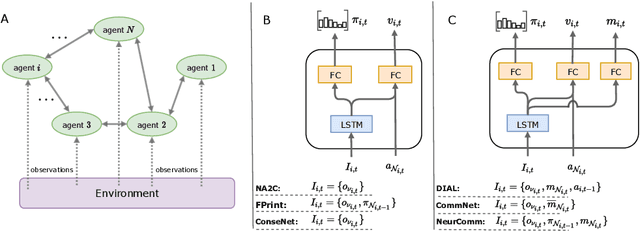
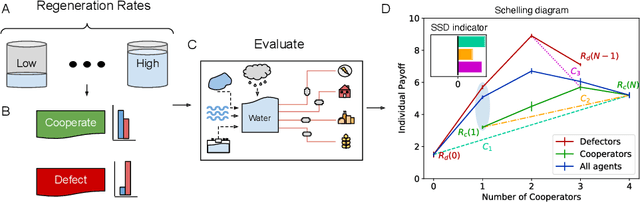
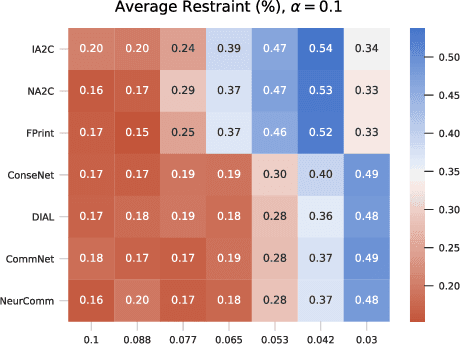
Multi-agent reinforcement learning has recently shown great promise as an approach to networked system control. Arguably, one of the most difficult and important tasks for which large scale networked system control is applicable is common-pool resource management. Crucial common-pool resources include arable land, fresh water, wetlands, wildlife, fish stock, forests and the atmosphere, of which proper management is related to some of society's greatest challenges such as food security, inequality and climate change. Here we take inspiration from a recent research program investigating the game-theoretic incentives of humans in social dilemma situations such as the well-known tragedy of the commons. However, instead of focusing on biologically evolved human-like agents, our concern is rather to better understand the learning and operating behaviour of engineered networked systems comprising general-purpose reinforcement learning agents, subject only to nonbiological constraints such as memory, computation and communication bandwidth. Harnessing tools from empirical game-theoretic analysis, we analyse the differences in resulting solution concepts that stem from employing different information structures in the design of networked multi-agent systems. These information structures pertain to the type of information shared between agents as well as the employed communication protocol and network topology. Our analysis contributes new insights into the consequences associated with certain design choices and provides an additional dimension of comparison between systems beyond efficiency, robustness, scalability and mean control performance.
Learning Compositional Neural Programs for Continuous Control
Jul 27, 2020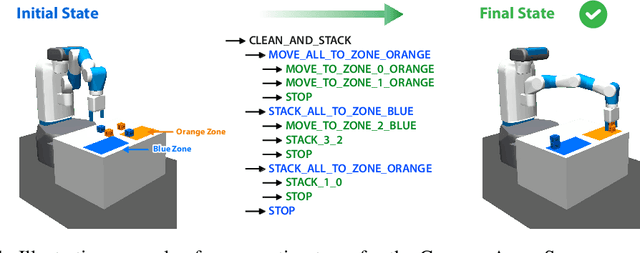

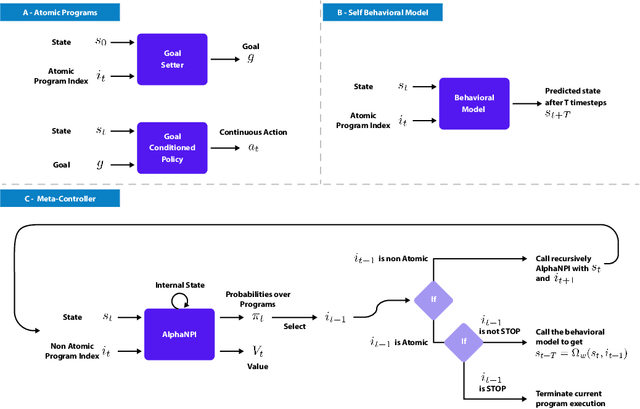
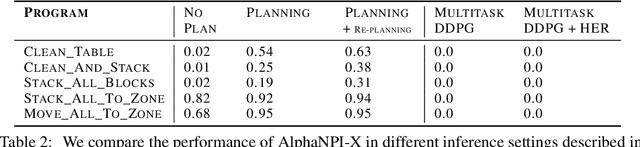
We propose a novel solution to challenging sparse-reward, continuous control problems that require hierarchical planning at multiple levels of abstraction. Our solution, dubbed AlphaNPI-X, involves three separate stages of learning. First, we use off-policy reinforcement learning algorithms with experience replay to learn a set of atomic goal-conditioned policies, which can be easily repurposed for many tasks. Second, we learn self-models describing the effect of the atomic policies on the environment. Third, the self-models are harnessed to learn recursive compositional programs with multiple levels of abstraction. The key insight is that the self-models enable planning by imagination, obviating the need for interaction with the world when learning higher-level compositional programs. To accomplish the third stage of learning, we extend the AlphaNPI algorithm, which applies AlphaZero to learn recursive neural programmer-interpreters. We empirically show that AlphaNPI-X can effectively learn to tackle challenging sparse manipulation tasks, such as stacking multiple blocks, where powerful model-free baselines fail.
QD-RL: Efficient Mixing of Quality and Diversity in Reinforcement Learning
Jun 15, 2020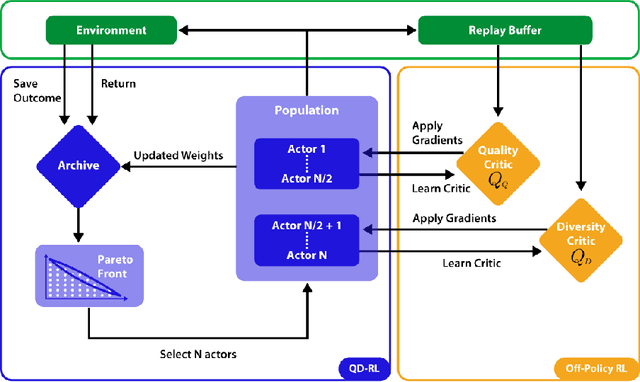
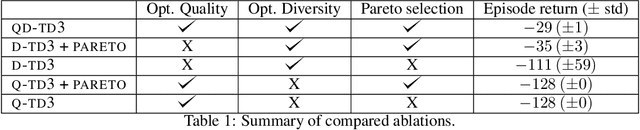
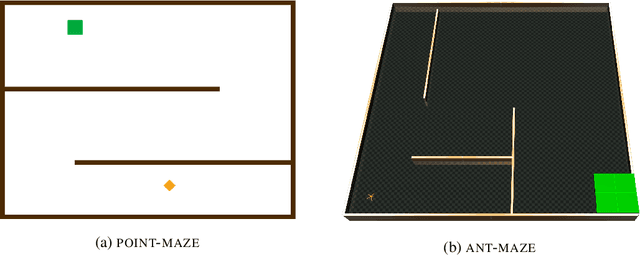
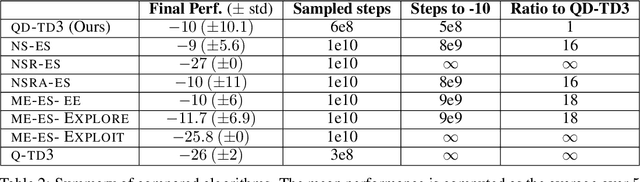
We propose a novel reinforcement learning algorithm,QD-RL, that incorporates the strengths of off-policy RL algorithms into Quality Diversity (QD) approaches. Quality-Diversity methods contribute structural biases by decoupling the search for diversity from the search for high return, resulting in efficient management of the exploration-exploitation trade-off. However, these approaches generally suffer from sample inefficiency as they call upon evolutionary techniques. QD-RL removes this limitation by relying on off-policy RL algorithms. More precisely, we train a population of off-policy deep RL agents to simultaneously maximize diversity inside the population and the return of the agents. QD-RL selects agents from the diversity-return Pareto Front, resulting in stable and efficient population updates. Our experiments on the Ant-Maze environment show that QD-RL can solve challenging exploration and control problems with deceptive rewards while being more than 15 times more sample efficient than its evolutionary counterparts.