 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised On-Policy Reinforcement Learning via Contrastive Proximal Policy Optimisation
May 13, 2026Contrastive reinforcement learning (CRL) learns goal-conditioned Q-values through a contrastive objective over state-action and goal representations, removing the need for hand-crafted reward functions. Despite impressive success in achieving viable self-supervised learning in RL, all existing CRL algorithms rely on off-policy optimisation and are mostly constrained to continuous action spaces, with little research invested in discrete environments. This leaves CRL disconnected from widely used and effective, modern on-policy training pipelines adopted across both single-agent and multi-agent RL in continuous and discrete environments. To establish a first connection, we introduce Contrastive Proximal Policy Optimisation (CPPO). CPPO is an on-policy contrastive RL algorithm that derives policy advantages directly from contrastive Q-values and optimises them via the standard PPO objective, without requiring a reward function or a replay buffer. We evaluate CPPO across continuous and discrete, single-agent and cooperative multi-agent tasks. Whilst the existence of an on-policy approach is inherently useful, we observe that \textbf{CPPO not only significantly outperforms the previous CRL baselines in 14 out of 18 tasks, but also matches or exceeds PPO's performance, which uses hand-crafted dense rewards, in 12 out of the 18 tasks tested.}
Oryx: a Performant and Scalable Algorithm for Many-Agent Coordination in Offline MARL
May 28, 2025


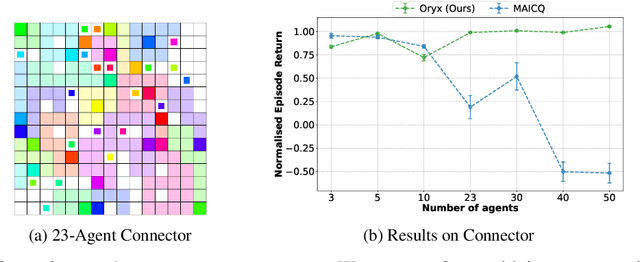
A key challenge in offline multi-agent reinforcement learning (MARL) is achieving effective many-agent multi-step coordination in complex environments. In this work, we propose Oryx, a novel algorithm for offline cooperative MARL to directly address this challenge. Oryx adapts the recently proposed retention-based architecture Sable and combines it with a sequential form of implicit constraint Q-learning (ICQ), to develop a novel offline auto-regressive policy update scheme. This allows Oryx to solve complex coordination challenges while maintaining temporal coherence over lengthy trajectories. We evaluate Oryx across a diverse set of benchmarks from prior works (SMAC, RWARE, and Multi-Agent MuJoCo) covering tasks of both discrete and continuous control, varying in scale and difficulty. Oryx achieves state-of-the-art performance on more than 80% of the 65 tested datasets, outperforming prior offline MARL methods and demonstrating robust generalisation across domains with many agents and long horizons. Finally, we introduce new datasets to push the limits of many-agent coordination in offline MARL, and demonstrate Oryx's superior ability to scale effectively in such settings. We will make all of our datasets, experimental data, and code available upon publication.
Breaking the Performance Ceiling in Complex Reinforcement Learning requires Inference Strategies
May 27, 2025



Reinforcement learning (RL) systems have countless applications, from energy-grid management to protein design. However, such real-world scenarios are often extremely difficult, combinatorial in nature, and require complex coordination between multiple agents. This level of complexity can cause even state-of-the-art RL systems, trained until convergence, to hit a performance ceiling which they are unable to break out of with zero-shot inference. Meanwhile, many digital or simulation-based applications allow for an inference phase that utilises a specific time and compute budget to explore multiple attempts before outputting a final solution. In this work, we show that such an inference phase employed at execution time, and the choice of a corresponding inference strategy, are key to breaking the performance ceiling observed in complex multi-agent RL problems. Our main result is striking: we can obtain up to a 126% and, on average, a 45% improvement over the previous state-of-the-art across 17 tasks, using only a couple seconds of extra wall-clock time during execution. We also demonstrate promising compute scaling properties, supported by over 60k experiments, making it the largest study on inference strategies for complex RL to date. Our experimental data and code are available at https://sites.google.com/view/inf-marl.
Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization
Jun 24, 2024Combinatorial Optimization is crucial to numerous real-world applications, yet still presents challenges due to its (NP-)hard nature. Amongst existing approaches, heuristics often offer the best trade-off between quality and scalability, making them suitable for industrial use. While Reinforcement Learning (RL) offers a flexible framework for designing heuristics, its adoption over handcrafted heuristics remains incomplete within industrial solvers. Existing learned methods still lack the ability to adapt to specific instances and fully leverage the available computational budget. The current best methods either rely on a collection of pre-trained policies, or on data-inefficient fine-tuning; hence failing to fully utilize newly available information within the constraints of the budget. In response, we present MEMENTO, an RL approach that leverages memory to improve the adaptation of neural solvers at inference time. MEMENTO enables updating the action distribution dynamically based on the outcome of previous decisions. We validate its effectiveness on benchmark problems, in particular Traveling Salesman and Capacitated Vehicle Routing, demonstrating it can successfully be combined with standard methods to boost their performance under a given budget, both in and out-of-distribution, improving their performance on all 12 evaluated tasks.
Combinatorial Optimization with Policy Adaptation using Latent Space Search
Nov 13, 2023Combinatorial Optimization underpins many real-world applications and yet, designing performant algorithms to solve these complex, typically NP-hard, problems remains a significant research challenge. Reinforcement Learning (RL) provides a versatile framework for designing heuristics across a broad spectrum of problem domains. However, despite notable progress, RL has not yet supplanted industrial solvers as the go-to solution. Current approaches emphasize pre-training heuristics that construct solutions but often rely on search procedures with limited variance, such as stochastically sampling numerous solutions from a single policy or employing computationally expensive fine-tuning of the policy on individual problem instances. Building on the intuition that performant search at inference time should be anticipated during pre-training, we propose COMPASS, a novel RL approach that parameterizes a distribution of diverse and specialized policies conditioned on a continuous latent space. We evaluate COMPASS across three canonical problems - Travelling Salesman, Capacitated Vehicle Routing, and Job-Shop Scheduling - and demonstrate that our search strategy (i) outperforms state-of-the-art approaches on 11 standard benchmarking tasks and (ii) generalizes better, surpassing all other approaches on a set of 18 procedurally transformed instance distributions.
QDax: A Library for Quality-Diversity and Population-based Algorithms with Hardware Acceleration
Aug 07, 2023QDax is an open-source library with a streamlined and modular API for Quality-Diversity (QD) optimization algorithms in Jax. The library serves as a versatile tool for optimization purposes, ranging from black-box optimization to continuous control. QDax offers implementations of popular QD, Neuroevolution, and Reinforcement Learning (RL) algorithms, supported by various examples. All the implementations can be just-in-time compiled with Jax, facilitating efficient execution across multiple accelerators, including GPUs and TPUs. These implementations effectively demonstrate the framework's flexibility and user-friendliness, easing experimentation for research purposes. Furthermore, the library is thoroughly documented and tested with 95\% coverage.
The Quality-Diversity Transformer: Generating Behavior-Conditioned Trajectories with Decision Transformers
Mar 27, 2023In the context of neuroevolution, Quality-Diversity algorithms have proven effective in generating repertoires of diverse and efficient policies by relying on the definition of a behavior space. A natural goal induced by the creation of such a repertoire is trying to achieve behaviors on demand, which can be done by running the corresponding policy from the repertoire. However, in uncertain environments, two problems arise. First, policies can lack robustness and repeatability, meaning that multiple episodes under slightly different conditions often result in very different behaviors. Second, due to the discrete nature of the repertoire, solutions vary discontinuously. Here we present a new approach to achieve behavior-conditioned trajectory generation based on two mechanisms: First, MAP-Elites Low-Spread (ME-LS), which constrains the selection of solutions to those that are the most consistent in the behavior space. Second, the Quality-Diversity Transformer (QDT), a Transformer-based model conditioned on continuous behavior descriptors, which trains on a dataset generated by policies from a ME-LS repertoire and learns to autoregressively generate sequences of actions that achieve target behaviors. Results show that ME-LS produces consistent and robust policies, and that its combination with the QDT yields a single policy capable of achieving diverse behaviors on demand with high accuracy.
Assessing Quality-Diversity Neuro-Evolution Algorithms Performance in Hard Exploration Problems
Nov 24, 2022A fascinating aspect of nature lies in its ability to produce a collection of organisms that are all high-performing in their niche. Quality-Diversity (QD) methods are evolutionary algorithms inspired by this observation, that obtained great results in many applications, from wing design to robot adaptation. Recently, several works demonstrated that these methods could be applied to perform neuro-evolution to solve control problems in large search spaces. In such problems, diversity can be a target in itself. Diversity can also be a way to enhance exploration in tasks exhibiting deceptive reward signals. While the first aspect has been studied in depth in the QD community, the latter remains scarcer in the literature. Exploration is at the heart of several domains trying to solve control problems such as Reinforcement Learning and QD methods are promising candidates to overcome the challenges associated. Therefore, we believe that standardized benchmarks exhibiting control problems in high dimension with exploration difficulties are of interest to the QD community. In this paper, we highlight three candidate benchmarks and explain why they appear relevant for systematic evaluation of QD algorithms. We also provide open-source implementations in Jax allowing practitioners to run fast and numerous experiments on few compute resources.
Empirical analysis of PGA-MAP-Elites for Neuroevolution in Uncertain Domains
Oct 24, 2022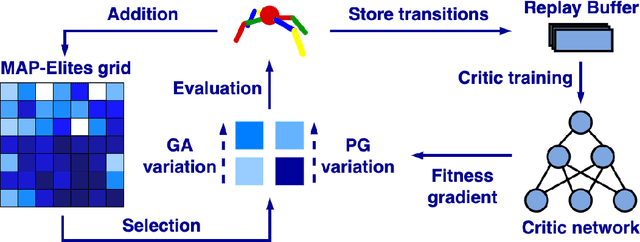
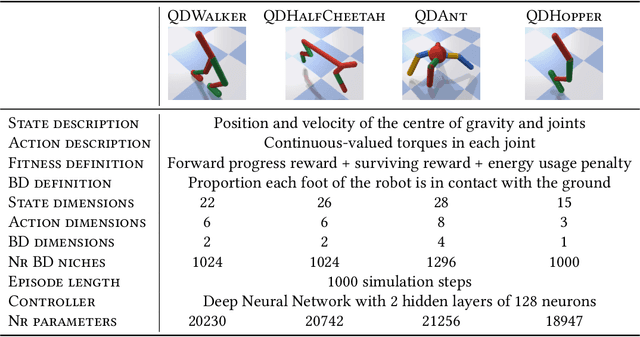

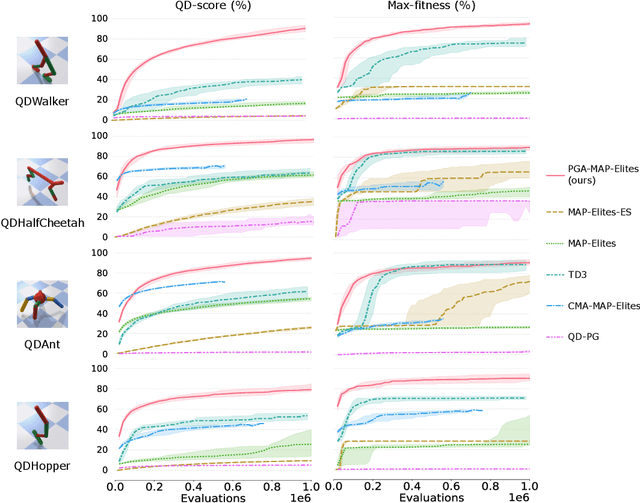
Quality-Diversity algorithms, among which MAP-Elites, have emerged as powerful alternatives to performance-only optimisation approaches as they enable generating collections of diverse and high-performing solutions to an optimisation problem. However, they are often limited to low-dimensional search spaces and deterministic environments. The recently introduced Policy Gradient Assisted MAP-Elites (PGA-MAP-Elites) algorithm overcomes this limitation by pairing the traditional Genetic operator of MAP-Elites with a gradient-based operator inspired by Deep Reinforcement Learning. This new operator guides mutations toward high-performing solutions using policy-gradients. In this work, we propose an in-depth study of PGA-MAP-Elites. We demonstrate the benefits of policy-gradients on the performance of the algorithm and the reproducibility of the generated solutions when considering uncertain domains. We first prove that PGA-MAP-Elites is highly performant in both deterministic and uncertain high-dimensional environments, decorrelating the two challenges it tackles. Secondly, we show that in addition to outperforming all the considered baselines, the collections of solutions generated by PGA-MAP-Elites are highly reproducible in uncertain environments, approaching the reproducibility of solutions found by Quality-Diversity approaches built specifically for uncertain applications. Finally, we propose an ablation and in-depth analysis of the dynamic of the policy-gradients-based variation. We demonstrate that the policy-gradient variation operator is determinant to guarantee the performance of PGA-MAP-Elites but is only essential during the early stage of the process, where it finds high-performing regions of the search space.
Neuroevolution is a Competitive Alternative to Reinforcement Learning for Skill Discovery
Oct 06, 2022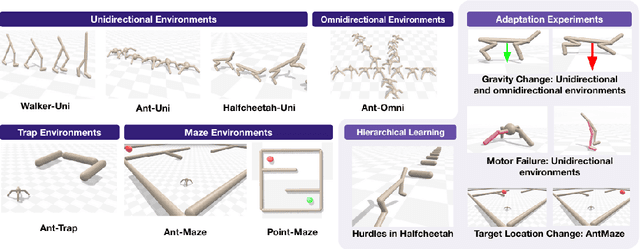
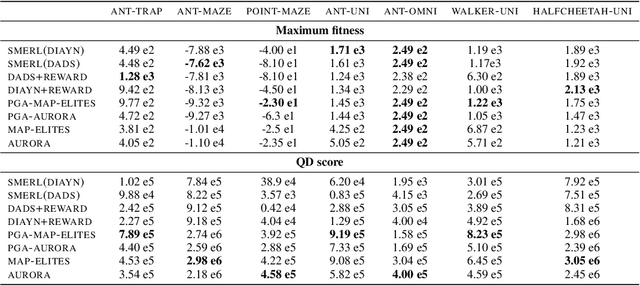
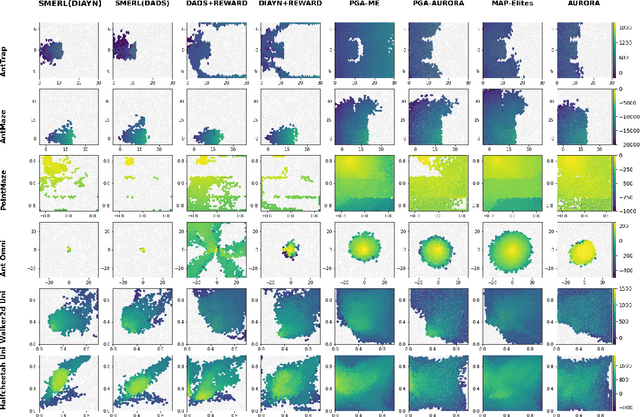
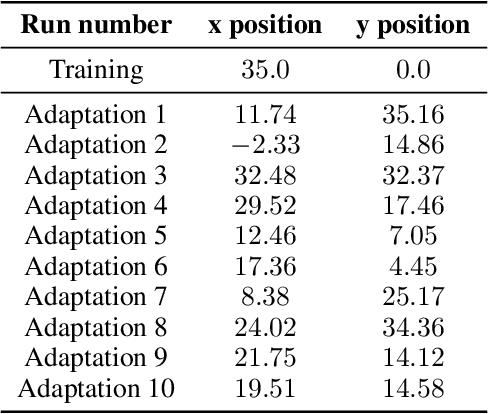
Deep Reinforcement Learning (RL) has emerged as a powerful paradigm for training neural policies to solve complex control tasks. However, these policies tend to be overfit to the exact specifications of the task and environment they were trained on, and thus do not perform well when conditions deviate slightly or when composed hierarchically to solve even more complex tasks. Recent work has shown that training a mixture of policies, as opposed to a single one, that are driven to explore different regions of the state-action space can address this shortcoming by generating a diverse set of behaviors, referred to as skills, that can be collectively used to great effect in adaptation tasks or for hierarchical planning. This is typically realized by including a diversity term - often derived from information theory - in the objective function optimized by RL. However these approaches often require careful hyperparameter tuning to be effective. In this work, we demonstrate that less widely-used neuroevolution methods, specifically Quality Diversity (QD), are a competitive alternative to information-theory-augmented RL for skill discovery. Through an extensive empirical evaluation comparing eight state-of-the-art methods on the basis of (i) metrics directly evaluating the skills' diversity, (ii) the skills' performance on adaptation tasks, and (iii) the skills' performance when used as primitives for hierarchical planning; QD methods are found to provide equal, and sometimes improved, performance whilst being less sensitive to hyperparameters and more scalable. As no single method is found to provide near-optimal performance across all environments, there is a rich scope for further research which we support by proposing future directions and providing optimized open-source implementations.