 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised On-Policy Reinforcement Learning via Contrastive Proximal Policy Optimisation
May 13, 2026Contrastive reinforcement learning (CRL) learns goal-conditioned Q-values through a contrastive objective over state-action and goal representations, removing the need for hand-crafted reward functions. Despite impressive success in achieving viable self-supervised learning in RL, all existing CRL algorithms rely on off-policy optimisation and are mostly constrained to continuous action spaces, with little research invested in discrete environments. This leaves CRL disconnected from widely used and effective, modern on-policy training pipelines adopted across both single-agent and multi-agent RL in continuous and discrete environments. To establish a first connection, we introduce Contrastive Proximal Policy Optimisation (CPPO). CPPO is an on-policy contrastive RL algorithm that derives policy advantages directly from contrastive Q-values and optimises them via the standard PPO objective, without requiring a reward function or a replay buffer. We evaluate CPPO across continuous and discrete, single-agent and cooperative multi-agent tasks. Whilst the existence of an on-policy approach is inherently useful, we observe that \textbf{CPPO not only significantly outperforms the previous CRL baselines in 14 out of 18 tasks, but also matches or exceeds PPO's performance, which uses hand-crafted dense rewards, in 12 out of the 18 tasks tested.}
Physics informed Transformer-VAE for biophysical parameter estimation: PROSAIL model inversion in Sentinel-2 imagery
Nov 17, 2025



Accurate retrieval of vegetation biophysical variables from satellite imagery is crucial for ecosystem monitoring and agricultural management. In this work, we propose a physics-informed Transformer-VAE architecture to invert the PROSAIL radiative transfer model for simultaneous estimation of key canopy parameters from Sentinel-2 data. Unlike previous hybrid approaches that require real satellite images for self-supevised training. Our model is trained exclusively on simulated data, yet achieves performance on par with state-of-the-art methods that utilize real imagery. The Transformer-VAE incorporates the PROSAIL model as a differentiable physical decoder, ensuring that inferred latent variables correspond to physically plausible leaf and canopy properties. We demonstrate retrieval of leaf area index (LAI) and canopy chlorophyll content (CCC) on real-world field datasets (FRM4Veg and BelSAR) with accuracy comparable to models trained with real Sentinel-2 data. Our method requires no in-situ labels or calibration on real images, offering a cost-effective and self-supervised solution for global vegetation monitoring. The proposed approach illustrates how integrating physical models with advanced deep networks can improve the inversion of RTMs, opening new prospects for large-scale, physically-constrained remote sensing of vegetation traits.
Oryx: a Performant and Scalable Algorithm for Many-Agent Coordination in Offline MARL
May 28, 2025


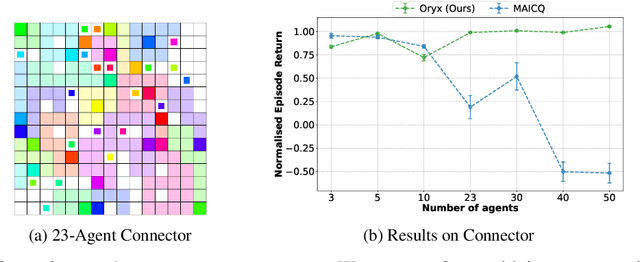
A key challenge in offline multi-agent reinforcement learning (MARL) is achieving effective many-agent multi-step coordination in complex environments. In this work, we propose Oryx, a novel algorithm for offline cooperative MARL to directly address this challenge. Oryx adapts the recently proposed retention-based architecture Sable and combines it with a sequential form of implicit constraint Q-learning (ICQ), to develop a novel offline auto-regressive policy update scheme. This allows Oryx to solve complex coordination challenges while maintaining temporal coherence over lengthy trajectories. We evaluate Oryx across a diverse set of benchmarks from prior works (SMAC, RWARE, and Multi-Agent MuJoCo) covering tasks of both discrete and continuous control, varying in scale and difficulty. Oryx achieves state-of-the-art performance on more than 80% of the 65 tested datasets, outperforming prior offline MARL methods and demonstrating robust generalisation across domains with many agents and long horizons. Finally, we introduce new datasets to push the limits of many-agent coordination in offline MARL, and demonstrate Oryx's superior ability to scale effectively in such settings. We will make all of our datasets, experimental data, and code available upon publication.
Breaking the Performance Ceiling in Complex Reinforcement Learning requires Inference Strategies
May 27, 2025



Reinforcement learning (RL) systems have countless applications, from energy-grid management to protein design. However, such real-world scenarios are often extremely difficult, combinatorial in nature, and require complex coordination between multiple agents. This level of complexity can cause even state-of-the-art RL systems, trained until convergence, to hit a performance ceiling which they are unable to break out of with zero-shot inference. Meanwhile, many digital or simulation-based applications allow for an inference phase that utilises a specific time and compute budget to explore multiple attempts before outputting a final solution. In this work, we show that such an inference phase employed at execution time, and the choice of a corresponding inference strategy, are key to breaking the performance ceiling observed in complex multi-agent RL problems. Our main result is striking: we can obtain up to a 126% and, on average, a 45% improvement over the previous state-of-the-art across 17 tasks, using only a couple seconds of extra wall-clock time during execution. We also demonstrate promising compute scaling properties, supported by over 60k experiments, making it the largest study on inference strategies for complex RL to date. Our experimental data and code are available at https://sites.google.com/view/inf-marl.
Performant, Memory Efficient and Scalable Multi-Agent Reinforcement Learning
Oct 02, 2024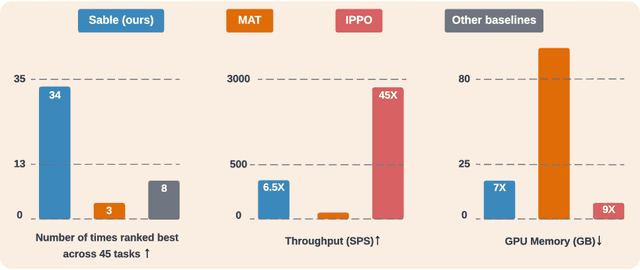
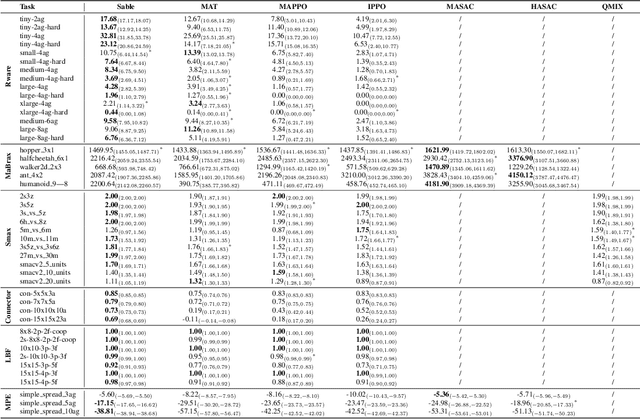

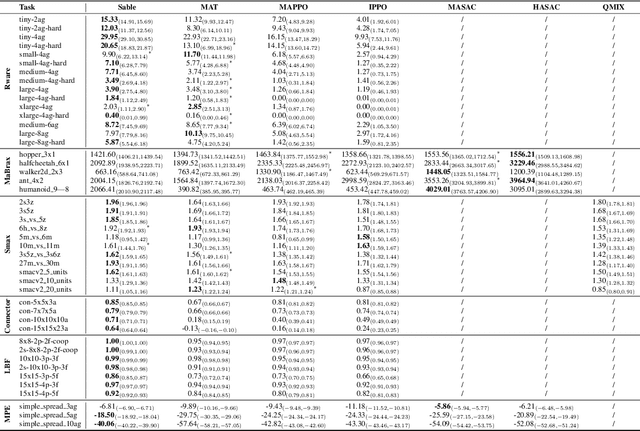
As the field of multi-agent reinforcement learning (MARL) progresses towards larger and more complex environments, achieving strong performance while maintaining memory efficiency and scalability to many agents becomes increasingly important. Although recent research has led to several advanced algorithms, to date, none fully address all of these key properties simultaneously. In this work, we introduce Sable, a novel and theoretically sound algorithm that adapts the retention mechanism from Retentive Networks to MARL. Sable's retention-based sequence modelling architecture allows for computationally efficient scaling to a large number of agents, as well as maintaining a long temporal context, making it well-suited for large-scale partially observable environments. Through extensive evaluations across six diverse environments, we demonstrate how Sable is able to significantly outperform existing state-of-the-art methods in the majority of tasks (34 out of 45, roughly 75\%). Furthermore, Sable demonstrates stable performance as we scale the number of agents, handling environments with more than a thousand agents while exhibiting a linear increase in memory usage. Finally, we conduct ablation studies to isolate the source of Sable's performance gains and confirm its efficient computational memory usage. Our results highlight Sable's performance and efficiency, positioning it as a leading approach to MARL at scale.
Putting Data at the Centre of Offline Multi-Agent Reinforcement Learning
Sep 18, 2024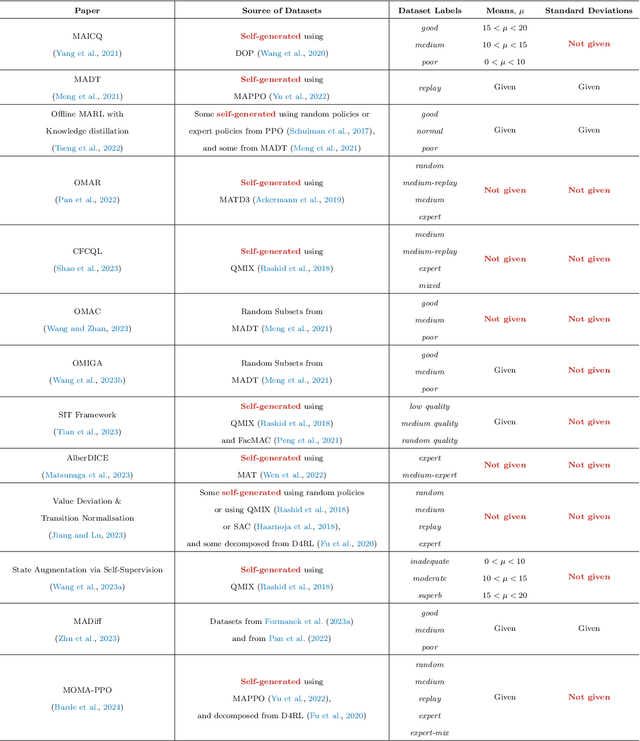
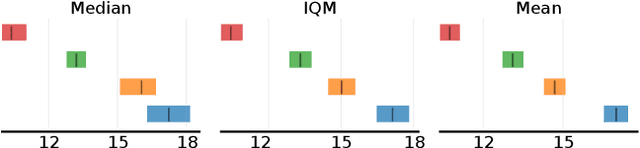

Offline multi-agent reinforcement learning (MARL) is an exciting direction of research that uses static datasets to find optimal control policies for multi-agent systems. Though the field is by definition data-driven, efforts have thus far neglected data in their drive to achieve state-of-the-art results. We first substantiate this claim by surveying the literature, showing how the majority of works generate their own datasets without consistent methodology and provide sparse information about the characteristics of these datasets. We then show why neglecting the nature of the data is problematic, through salient examples of how tightly algorithmic performance is coupled to the dataset used, necessitating a common foundation for experiments in the field. In response, we take a big step towards improving data usage and data awareness in offline MARL, with three key contributions: (1) a clear guideline for generating novel datasets; (2) a standardisation of over 80 existing datasets, hosted in a publicly available repository, using a consistent storage format and easy-to-use API; and (3) a suite of analysis tools that allow us to understand these datasets better, aiding further development.
Coordination Failure in Cooperative Offline MARL
Jul 01, 2024
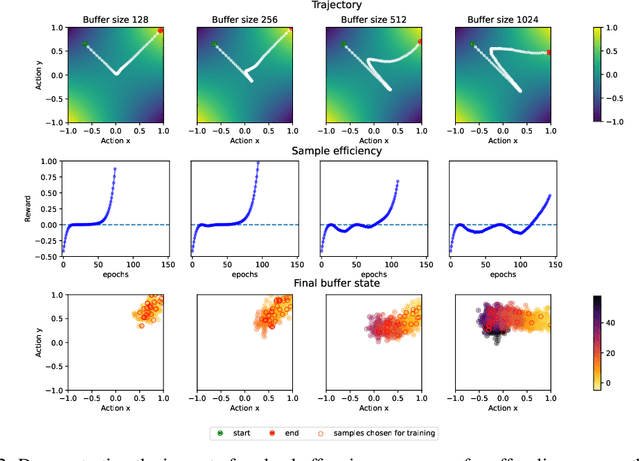
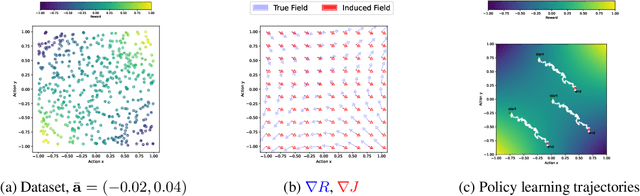
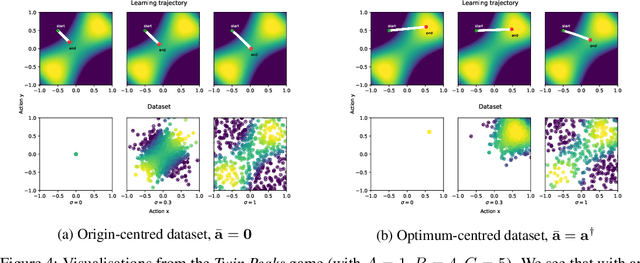
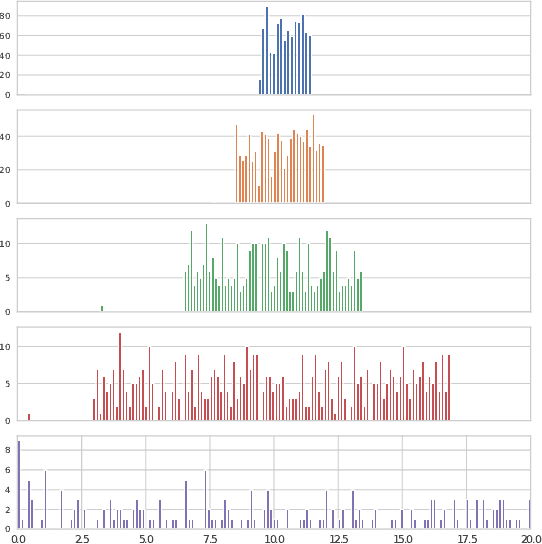
Offline multi-agent reinforcement learning (MARL) leverages static datasets of experience to learn optimal multi-agent control. However, learning from static data presents several unique challenges to overcome. In this paper, we focus on coordination failure and investigate the role of joint actions in multi-agent policy gradients with offline data, focusing on a common setting we refer to as the 'Best Response Under Data' (BRUD) approach. By using two-player polynomial games as an analytical tool, we demonstrate a simple yet overlooked failure mode of BRUD-based algorithms, which can lead to catastrophic coordination failure in the offline setting. Building on these insights, we propose an approach to mitigate such failure, by prioritising samples from the dataset based on joint-action similarity during policy learning and demonstrate its effectiveness in detailed experiments. More generally, however, we argue that prioritised dataset sampling is a promising area for innovation in offline MARL that can be combined with other effective approaches such as critic and policy regularisation. Importantly, our work shows how insights drawn from simplified, tractable games can lead to useful, theoretically grounded insights that transfer to more complex contexts. A core dimension of offering is an interactive notebook, from which almost all of our results can be reproduced, in a browser.
Memory-Enhanced Neural Solvers for Efficient Adaptation in Combinatorial Optimization
Jun 24, 2024Combinatorial Optimization is crucial to numerous real-world applications, yet still presents challenges due to its (NP-)hard nature. Amongst existing approaches, heuristics often offer the best trade-off between quality and scalability, making them suitable for industrial use. While Reinforcement Learning (RL) offers a flexible framework for designing heuristics, its adoption over handcrafted heuristics remains incomplete within industrial solvers. Existing learned methods still lack the ability to adapt to specific instances and fully leverage the available computational budget. The current best methods either rely on a collection of pre-trained policies, or on data-inefficient fine-tuning; hence failing to fully utilize newly available information within the constraints of the budget. In response, we present MEMENTO, an RL approach that leverages memory to improve the adaptation of neural solvers at inference time. MEMENTO enables updating the action distribution dynamically based on the outcome of previous decisions. We validate its effectiveness on benchmark problems, in particular Traveling Salesman and Capacitated Vehicle Routing, demonstrating it can successfully be combined with standard methods to boost their performance under a given budget, both in and out-of-distribution, improving their performance on all 12 evaluated tasks.
Dispelling the Mirage of Progress in Offline MARL through Standardised Baselines and Evaluation
Jun 13, 2024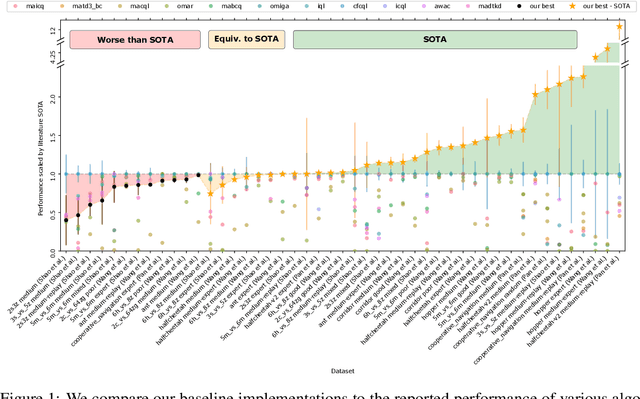


Offline multi-agent reinforcement learning (MARL) is an emerging field with great promise for real-world applications. Unfortunately, the current state of research in offline MARL is plagued by inconsistencies in baselines and evaluation protocols, which ultimately makes it difficult to accurately assess progress, trust newly proposed innovations, and allow researchers to easily build upon prior work. In this paper, we firstly identify significant shortcomings in existing methodologies for measuring the performance of novel algorithms through a representative study of published offline MARL work. Secondly, by directly comparing to this prior work, we demonstrate that simple, well-implemented baselines can achieve state-of-the-art (SOTA) results across a wide range of tasks. Specifically, we show that on 35 out of 47 datasets used in prior work (almost 75% of cases), we match or surpass the performance of the current purported SOTA. Strikingly, our baselines often substantially outperform these more sophisticated algorithms. Finally, we correct for the shortcomings highlighted from this prior work by introducing a straightforward standardised methodology for evaluation and by providing our baseline implementations with statistically robust results across several scenarios, useful for comparisons in future work. Our proposal includes simple and sensible steps that are easy to adopt, which in combination with solid baselines and comparative results, could substantially improve the overall rigour of empirical science in offline MARL moving forward.
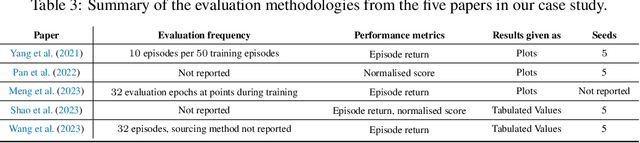
A Geospatial Approach to Predicting Desert Locust Breeding Grounds in Africa
Mar 21, 2024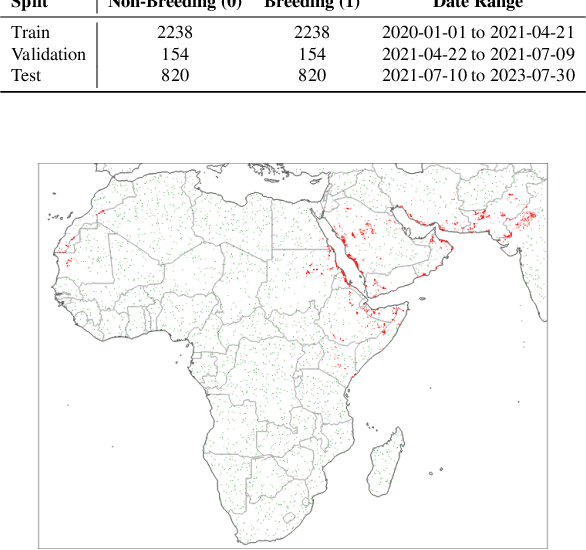
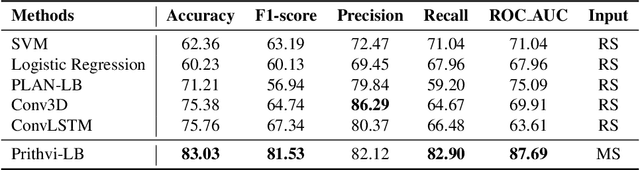
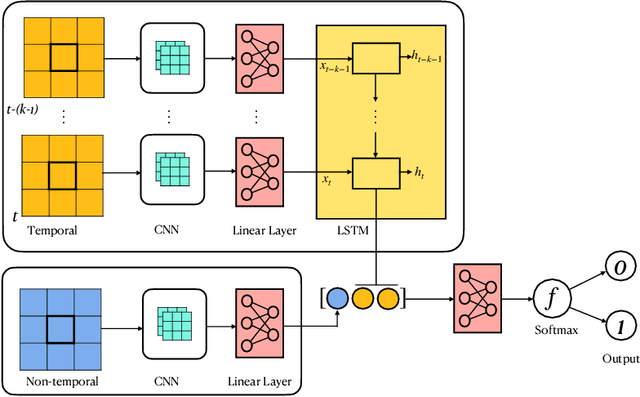
Desert locust swarms present a major threat to agriculture and food security. Addressing this challenge, our study develops an operationally-ready model for predicting locust breeding grounds, which has the potential to enhance early warning systems and targeted control measures. We curated a dataset from the United Nations Food and Agriculture Organization's (UN-FAO) locust observation records and analyzed it using two types of spatio-temporal input features: remotely-sensed environmental and climate data as well as multi-spectral earth observation images. Our approach employed custom deep learning models (three-dimensional and LSTM-based recurrent convolutional networks), along with the geospatial foundational model Prithvi recently released by Jakubik et al., 2023. These models notably outperformed existing baselines, with the Prithvi-based model, fine-tuned on multi-spectral images from NASA's Harmonized Landsat and Sentinel-2 (HLS) dataset, achieving the highest accuracy, F1 and ROC-AUC scores (83.03%, 81.53% and 87.69%, respectively). A significant finding from our research is that multi-spectral earth observation images alone are sufficient for effective locust breeding ground prediction without the need to explicitly incorporate climatic or environmental features.