 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Data at the Centre of Offline Multi-Agent Reinforcement Learning
Paper and Code
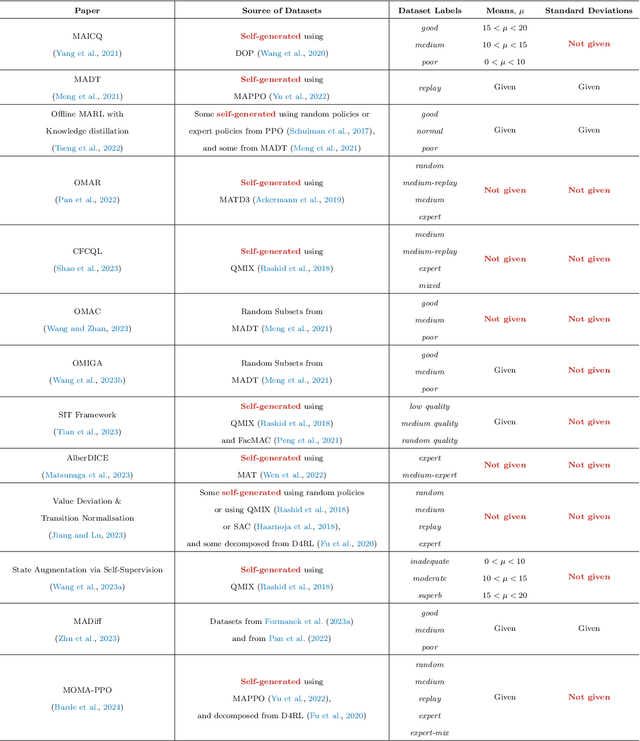
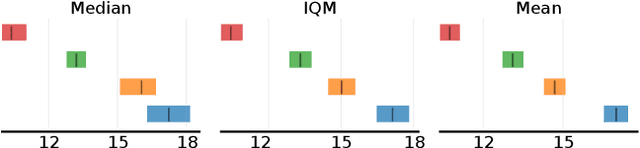
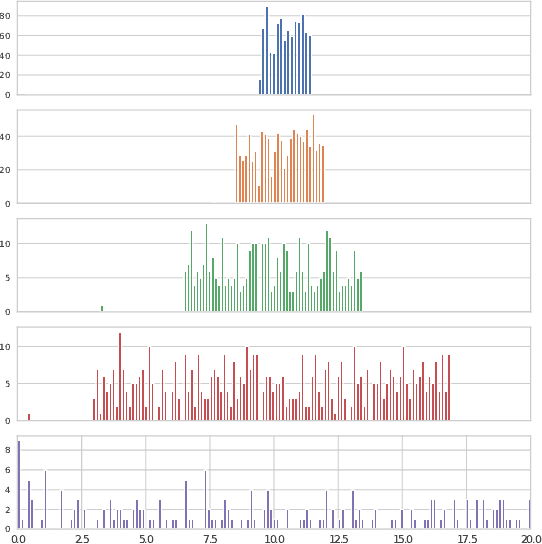

Offline multi-agent reinforcement learning (MARL) is an exciting direction of research that uses static datasets to find optimal control policies for multi-agent systems. Though the field is by definition data-driven, efforts have thus far neglected data in their drive to achieve state-of-the-art results. We first substantiate this claim by surveying the literature, showing how the majority of works generate their own datasets without consistent methodology and provide sparse information about the characteristics of these datasets. We then show why neglecting the nature of the data is problematic, through salient examples of how tightly algorithmic performance is coupled to the dataset used, necessitating a common foundation for experiments in the field. In response, we take a big step towards improving data usage and data awareness in offline MARL, with three key contributions: (1) a clear guideline for generating novel datasets; (2) a standardisation of over 80 existing datasets, hosted in a publicly available repository, using a consistent storage format and easy-to-use API; and (3) a suite of analysis tools that allow us to understand these datasets better, aiding further development.