 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Data at the Centre of Offline Multi-Agent Reinforcement Learning
Sep 18, 2024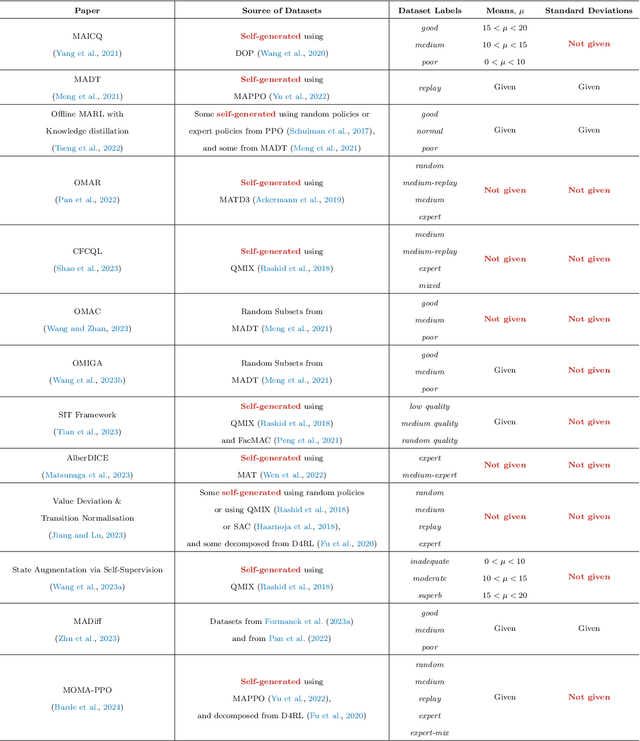
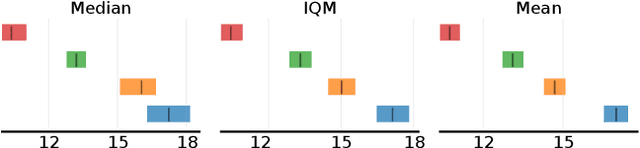
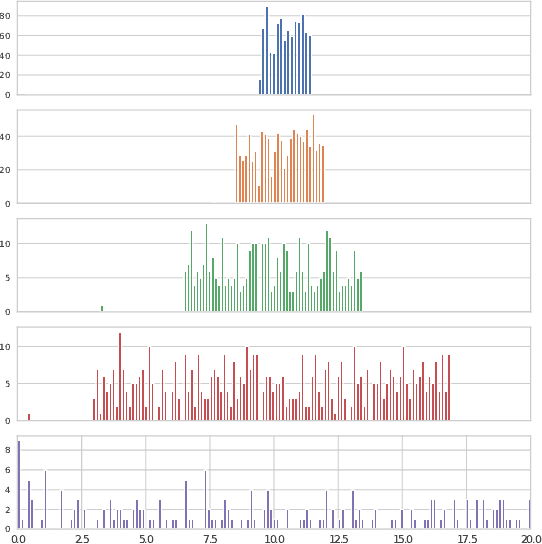

Offline multi-agent reinforcement learning (MARL) is an exciting direction of research that uses static datasets to find optimal control policies for multi-agent systems. Though the field is by definition data-driven, efforts have thus far neglected data in their drive to achieve state-of-the-art results. We first substantiate this claim by surveying the literature, showing how the majority of works generate their own datasets without consistent methodology and provide sparse information about the characteristics of these datasets. We then show why neglecting the nature of the data is problematic, through salient examples of how tightly algorithmic performance is coupled to the dataset used, necessitating a common foundation for experiments in the field. In response, we take a big step towards improving data usage and data awareness in offline MARL, with three key contributions: (1) a clear guideline for generating novel datasets; (2) a standardisation of over 80 existing datasets, hosted in a publicly available repository, using a consistent storage format and easy-to-use API; and (3) a suite of analysis tools that allow us to understand these datasets better, aiding further development.
Coordination Failure in Cooperative Offline MARL
Jul 01, 2024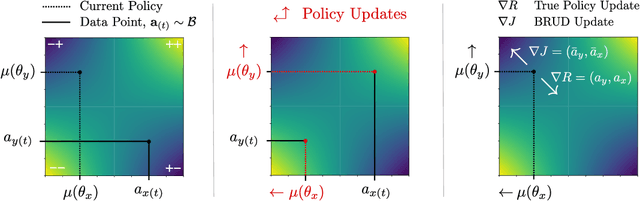
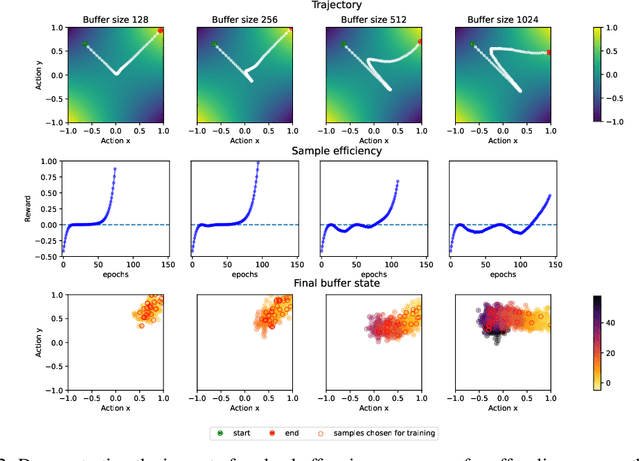
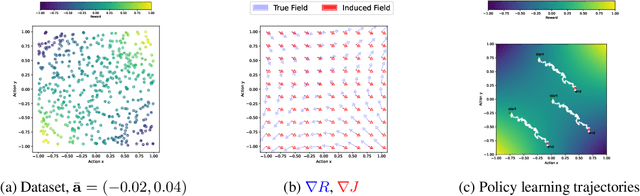
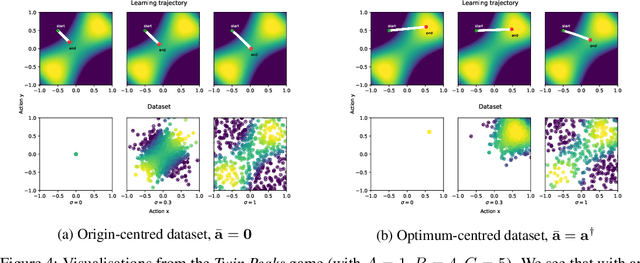
Offline multi-agent reinforcement learning (MARL) leverages static datasets of experience to learn optimal multi-agent control. However, learning from static data presents several unique challenges to overcome. In this paper, we focus on coordination failure and investigate the role of joint actions in multi-agent policy gradients with offline data, focusing on a common setting we refer to as the 'Best Response Under Data' (BRUD) approach. By using two-player polynomial games as an analytical tool, we demonstrate a simple yet overlooked failure mode of BRUD-based algorithms, which can lead to catastrophic coordination failure in the offline setting. Building on these insights, we propose an approach to mitigate such failure, by prioritising samples from the dataset based on joint-action similarity during policy learning and demonstrate its effectiveness in detailed experiments. More generally, however, we argue that prioritised dataset sampling is a promising area for innovation in offline MARL that can be combined with other effective approaches such as critic and policy regularisation. Importantly, our work shows how insights drawn from simplified, tractable games can lead to useful, theoretically grounded insights that transfer to more complex contexts. A core dimension of offering is an interactive notebook, from which almost all of our results can be reproduced, in a browser.
Planning to Learn: A Novel Algorithm for Active Learning during Model-Based Planning
Aug 15, 2023Active Inference is a recent framework for modeling planning under uncertainty. Empirical and theoretical work have now begun to evaluate the strengths and weaknesses of this approach and how it might be improved. A recent extension - the sophisticated inference (SI) algorithm - improves performance on multi-step planning problems through recursive decision tree search. However, little work to date has been done to compare SI to other established planning algorithms. SI was also developed with a focus on inference as opposed to learning. The present paper has two aims. First, we compare performance of SI to Bayesian reinforcement learning (RL) schemes designed to solve similar problems. Second, we present an extension of SI - sophisticated learning (SL) - that more fully incorporates active learning during planning. SL maintains beliefs about how model parameters would change under the future observations expected under each policy. This allows a form of counterfactual retrospective inference in which the agent considers what could be learned from current or past observations given different future observations. To accomplish these aims, we make use of a novel, biologically inspired environment designed to highlight the problem structure for which SL offers a unique solution. Here, an agent must continually search for available (but changing) resources in the presence of competing affordances for information gain. Our simulations show that SL outperforms all other algorithms in this context - most notably, Bayes-adaptive RL and upper confidence bound algorithms, which aim to solve multi-step planning problems using similar principles (i.e., directed exploration and counterfactual reasoning). These results provide added support for the utility of Active Inference in solving this class of biologically-relevant problems and offer added tools for testing hypotheses about human cognition.