 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: the Stochastic Parrot in the Coal Mine. Model Collapse is a Threat to Low-Resource Communities
May 05, 2026Model collapse, the degradation in performance that arises when generative models are trained on the outputs of prior models, is an increasing concern as artificially generated content proliferates. Related critiques of large language models have highlighted their tendency to reproduce frequent patterns in training data, their reliance on vast datasets, and their substantial environmental cost. Together, these factors contribute to data degradation, the reinforcement of cultural biases, and inefficient resource use. In this position paper we aim to combine these views and argue that model collapse threatens current efforts to democratize AI. By reducing training efficiency and skewing data distributions away from the tails of their support, model collapse disproportionately impacts low-resource and marginalized communities. We examine both the environmental and cultural implications of this phenomenon, situate our position within recent position papers on model collapse, and conclude with a call to action. Finally, we outline initial directions for mitigating these effects.
MoralityGym: A Benchmark for Evaluating Hierarchical Moral Alignment in Sequential Decision-Making Agents
Feb 13, 2026Evaluating moral alignment in agents navigating conflicting, hierarchically structured human norms is a critical challenge at the intersection of AI safety, moral philosophy, and cognitive science. We introduce Morality Chains, a novel formalism for representing moral norms as ordered deontic constraints, and MoralityGym, a benchmark of 98 ethical-dilemma problems presented as trolley-dilemma-style Gymnasium environments. By decoupling task-solving from moral evaluation and introducing a novel Morality Metric, MoralityGym allows the integration of insights from psychology and philosophy into the evaluation of norm-sensitive reasoning. Baseline results with Safe RL methods reveal key limitations, underscoring the need for more principled approaches to ethical decision-making. This work provides a foundation for developing AI systems that behave more reliably, transparently, and ethically in complex real-world contexts.
Unsupervised Hierarchical Skill Discovery
Jan 30, 2026We consider the problem of unsupervised skill segmentation and hierarchical structure discovery in reinforcement learning. While recent approaches have sought to segment trajectories into reusable skills or options, most rely on action labels, rewards, or handcrafted annotations, limiting their applicability. We propose a method that segments unlabelled trajectories into skills and induces a hierarchical structure over them using a grammar-based approach. The resulting hierarchy captures both low-level behaviours and their composition into higher-level skills. We evaluate our approach in high-dimensional, pixel-based environments, including Craftax and the full, unmodified version of Minecraft. Using metrics for skill segmentation, reuse, and hierarchy quality, we find that our method consistently produces more structured and semantically meaningful hierarchies than existing baselines. Furthermore, as a proof of concept for utility, we demonstrate that these discovered hierarchies accelerate and stabilise learning on downstream reinforcement learning tasks.
Beyond Sliding Windows: Learning to Manage Memory in Non-Markovian Environments
Dec 22, 2025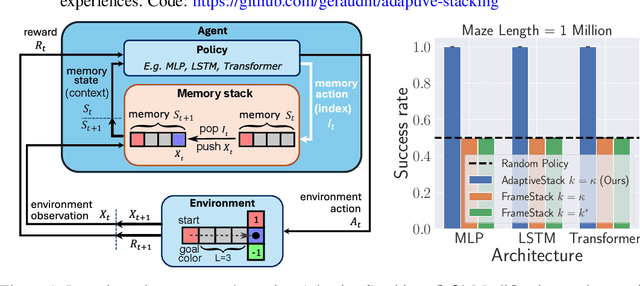

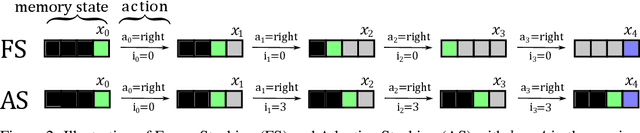

Recent success in developing increasingly general purpose agents based on sequence models has led to increased focus on the problem of deploying computationally limited agents within the vastly more complex real-world. A key challenge experienced in these more realistic domains is highly non-Markovian dependencies with respect to the agent's observations, which are less common in small controlled domains. The predominant approach for dealing with this in the literature is to stack together a window of the most recent observations (Frame Stacking), but this window size must grow with the degree of non-Markovian dependencies, which results in prohibitive computational and memory requirements for both action inference and learning. In this paper, we are motivated by the insight that in many environments that are highly non-Markovian with respect to time, the environment only causally depends on a relatively small number of observations over that time-scale. A natural direction would then be to consider meta-algorithms that maintain relatively small adaptive stacks of memories such that it is possible to express highly non-Markovian dependencies with respect to time while considering fewer observations at each step and thus experience substantial savings in both compute and memory requirements. Hence, we propose a meta-algorithm (Adaptive Stacking) for achieving exactly that with convergence guarantees and quantify the reduced computation and memory constraints for MLP, LSTM, and Transformer-based agents. Our experiments utilize popular memory tasks, which give us control over the degree of non-Markovian dependencies. This allows us to demonstrate that an appropriate meta-algorithm can learn the removal of memories not predictive of future rewards without excessive removal of important experiences. Code: https://github.com/geraudnt/adaptive-stacking
Make Haste Slowly: A Theory of Emergent Structured Mixed Selectivity in Feature Learning ReLU Networks
Mar 08, 2025In spite of finite dimension ReLU neural networks being a consistent factor behind recent deep learning successes, a theory of feature learning in these models remains elusive. Currently, insightful theories still rely on assumptions including the linearity of the network computations, unstructured input data and architectural constraints such as infinite width or a single hidden layer. To begin to address this gap we establish an equivalence between ReLU networks and Gated Deep Linear Networks, and use their greater tractability to derive dynamics of learning. We then consider multiple variants of a core task reminiscent of multi-task learning or contextual control which requires both feature learning and nonlinearity. We make explicit that, for these tasks, the ReLU networks possess an inductive bias towards latent representations which are not strictly modular or disentangled but are still highly structured and reusable between contexts. This effect is amplified with the addition of more contexts and hidden layers. Thus, we take a step towards a theory of feature learning in finite ReLU networks and shed light on how structured mixed-selective latent representations can emerge due to a bias for node-reuse and learning speed.
Revisiting the Role of Relearning in Semantic Dementia
Mar 05, 2025Patients with semantic dementia (SD) present with remarkably consistent atrophy of neurons in the anterior temporal lobe and behavioural impairments, such as graded loss of category knowledge. While relearning of lost knowledge has been shown in acute brain injuries such as stroke, it has not been widely supported in chronic cognitive diseases such as SD. Previous research has shown that deep linear artificial neural networks exhibit stages of semantic learning akin to humans. Here, we use a deep linear network to test the hypothesis that relearning during disease progression rather than particular atrophy cause the specific behavioural patterns associated with SD. After training the network to generate the common semantic features of various hierarchically organised objects, neurons are successively deleted to mimic atrophy while retraining the model. The model with relearning and deleted neurons reproduced errors specific to SD, including prototyping errors and cross-category confusions. This suggests that relearning is necessary for artificial neural networks to reproduce the behavioural patterns associated with SD in the absence of \textit{output} non-linearities. Our results support a theory of SD progression that results from continuous relearning of lost information. Future research should revisit the role of relearning as a contributing factor to cognitive diseases.
The Esethu Framework: Reimagining Sustainable Dataset Governance and Curation for Low-Resource Languages
Feb 21, 2025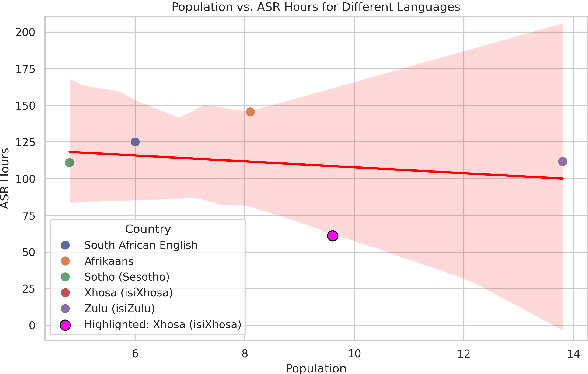

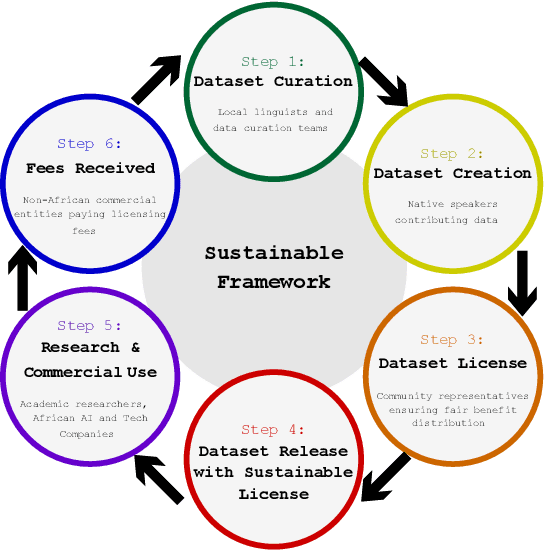

This paper presents the Esethu Framework, a sustainable data curation framework specifically designed to empower local communities and ensure equitable benefit-sharing from their linguistic resources. This framework is supported by the Esethu license, a novel community-centric data license. As a proof of concept, we introduce the Vuk'uzenzele isiXhosa Speech Dataset (ViXSD), an open-source corpus developed under the Esethu Framework and License. The dataset, containing read speech from native isiXhosa speakers enriched with demographic and linguistic metadata, demonstrates how community-driven licensing and curation principles can bridge resource gaps in automatic speech recognition (ASR) for African languages while safeguarding the interests of data creators. We describe the framework guiding dataset development, outline the Esethu license provisions, present the methodology for ViXSD, and present ASR experiments validating ViXSD's usability in building and refining voice-driven applications for isiXhosa.
The Zeno's Paradox of `Low-Resource' Languages
Oct 28, 2024



The disparity in the languages commonly studied in Natural Language Processing (NLP) is typically reflected by referring to languages as low vs high-resourced. However, there is limited consensus on what exactly qualifies as a `low-resource language.' To understand how NLP papers define and study `low resource' languages, we qualitatively analyzed 150 papers from the ACL Anthology and popular speech-processing conferences that mention the keyword `low-resource.' Based on our analysis, we show how several interacting axes contribute to `low-resourcedness' of a language and why that makes it difficult to track progress for each individual language. We hope our work (1) elicits explicit definitions of the terminology when it is used in papers and (2) provides grounding for the different axes to consider when connoting a language as low-resource.
InkubaLM: A small language model for low-resource African languages
Sep 03, 2024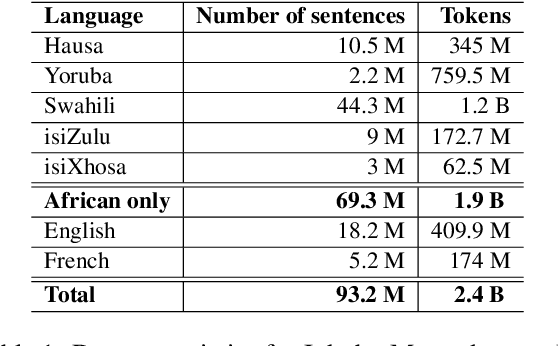
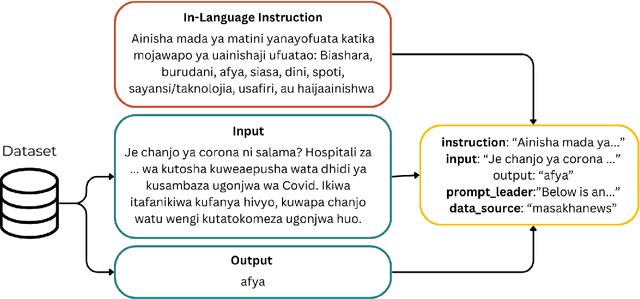
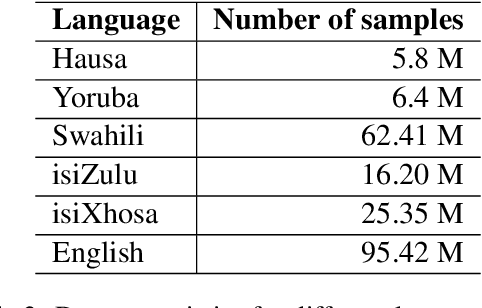
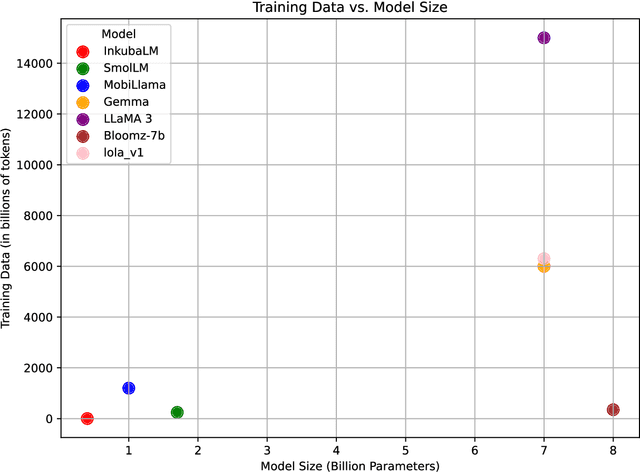
High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
Multi-State-Action Tokenisation in Decision Transformers for Multi-Discrete Action Spaces
Jul 01, 2024



Decision Transformers, in their vanilla form, struggle to perform on image-based environments with multi-discrete action spaces. Although enhanced Decision Transformer architectures have been developed to improve performance, these methods have not specifically addressed this problem of multi-discrete action spaces which hampers existing Decision Transformer architectures from learning good representations. To mitigate this, we propose Multi-State Action Tokenisation (M-SAT), an approach for tokenising actions in multi-discrete action spaces that enhances the model's performance in such environments. Our approach involves two key changes: disentangling actions to the individual action level and tokenising the actions with auxiliary state information. These two key changes also improve individual action level interpretability and visibility within the attention layers. We demonstrate the performance gains of M-SAT on challenging ViZDoom environments with multi-discrete action spaces and image-based state spaces, including the Deadly Corridor and My Way Home scenarios, where M-SAT outperforms the baseline Decision Transformer without any additional data or heavy computational overheads. Additionally, we find that removing positional encoding does not adversely affect M-SAT's performance and, in some cases, even improves it.