 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Reward Automata: Sample Efficient Reinforcement Learning Through the Exploitation of Reward Function Structure
Paper and Code
Dec 18, 2023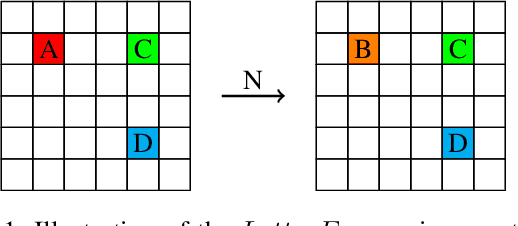
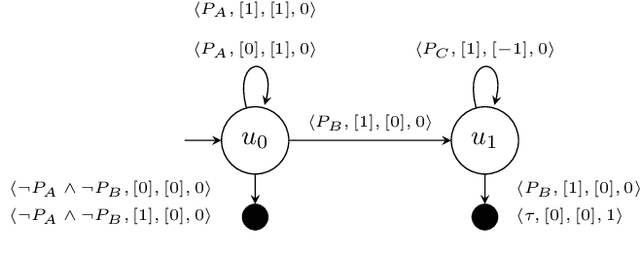
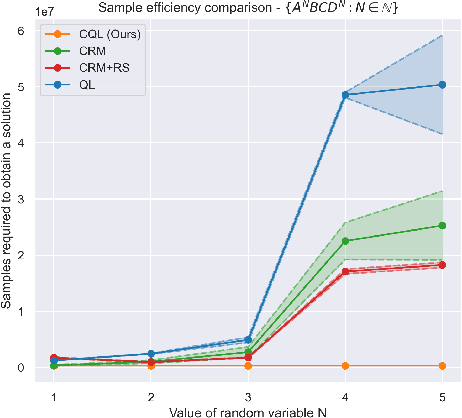
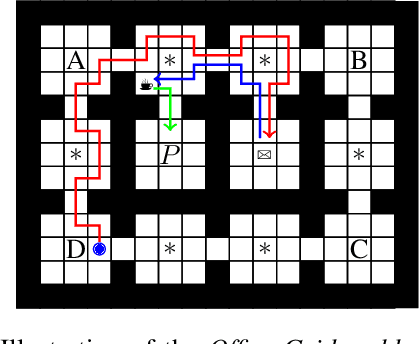
We present counting reward automata-a finite state machine variant capable of modelling any reward function expressible as a formal language. Unlike previous approaches, which are limited to the expression of tasks as regular languages, our framework allows for tasks described by unrestricted grammars. We prove that an agent equipped with such an abstract machine is able to solve a larger set of tasks than those utilising current approaches. We show that this increase in expressive power does not come at the cost of increased automaton complexity. A selection of learning algorithms are presented which exploit automaton structure to improve sample efficiency. We show that the state machines required in our formulation can be specified from natural language task descriptions using large language models. Empirical results demonstrate that our method outperforms competing approaches in terms of sample efficiency, automaton complexity, and task completion.