 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Financially Inclusive Credit Products Through Financial Time Series Clustering
Feb 16, 2024Financial inclusion ensures that individuals have access to financial products and services that meet their needs. As a key contributing factor to economic growth and investment opportunity, financial inclusion increases consumer spending and consequently business development. It has been shown that institutions are more profitable when they provide marginalised social groups access to financial services. Customer segmentation based on consumer transaction data is a well-known strategy used to promote financial inclusion. While the required data is available to modern institutions, the challenge remains that segment annotations are usually difficult and/or expensive to obtain. This prevents the usage of time series classification models for customer segmentation based on domain expert knowledge. As a result, clustering is an attractive alternative to partition customers into homogeneous groups based on the spending behaviour encoded within their transaction data. In this paper, we present a solution to one of the key challenges preventing modern financial institutions from providing financially inclusive credit, savings and insurance products: the inability to understand consumer financial behaviour, and hence risk, without the introduction of restrictive conventional credit scoring techniques. We present a novel time series clustering algorithm that allows institutions to understand the financial behaviour of their customers. This enables unique product offerings to be provided based on the needs of the customer, without reliance on restrictive credit practices.
Counting Reward Automata: Sample Efficient Reinforcement Learning Through the Exploitation of Reward Function Structure
Dec 18, 2023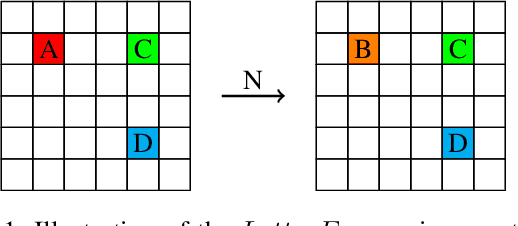
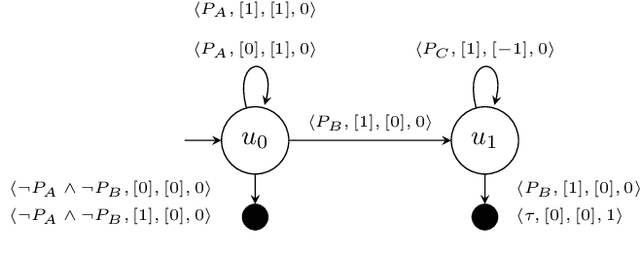
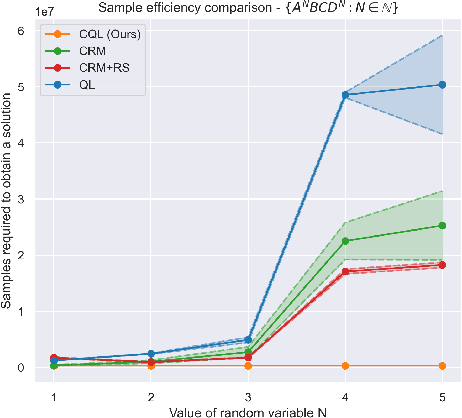
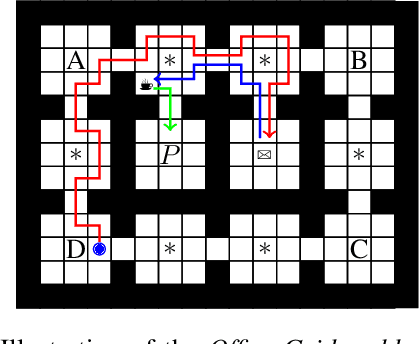
We present counting reward automata-a finite state machine variant capable of modelling any reward function expressible as a formal language. Unlike previous approaches, which are limited to the expression of tasks as regular languages, our framework allows for tasks described by unrestricted grammars. We prove that an agent equipped with such an abstract machine is able to solve a larger set of tasks than those utilising current approaches. We show that this increase in expressive power does not come at the cost of increased automaton complexity. A selection of learning algorithms are presented which exploit automaton structure to improve sample efficiency. We show that the state machines required in our formulation can be specified from natural language task descriptions using large language models. Empirical results demonstrate that our method outperforms competing approaches in terms of sample efficiency, automaton complexity, and task completion.