 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoralityGym: A Benchmark for Evaluating Hierarchical Moral Alignment in Sequential Decision-Making Agents
Feb 13, 2026Evaluating moral alignment in agents navigating conflicting, hierarchically structured human norms is a critical challenge at the intersection of AI safety, moral philosophy, and cognitive science. We introduce Morality Chains, a novel formalism for representing moral norms as ordered deontic constraints, and MoralityGym, a benchmark of 98 ethical-dilemma problems presented as trolley-dilemma-style Gymnasium environments. By decoupling task-solving from moral evaluation and introducing a novel Morality Metric, MoralityGym allows the integration of insights from psychology and philosophy into the evaluation of norm-sensitive reasoning. Baseline results with Safe RL methods reveal key limitations, underscoring the need for more principled approaches to ethical decision-making. This work provides a foundation for developing AI systems that behave more reliably, transparently, and ethically in complex real-world contexts.
Unsupervised Hierarchical Skill Discovery
Jan 30, 2026We consider the problem of unsupervised skill segmentation and hierarchical structure discovery in reinforcement learning. While recent approaches have sought to segment trajectories into reusable skills or options, most rely on action labels, rewards, or handcrafted annotations, limiting their applicability. We propose a method that segments unlabelled trajectories into skills and induces a hierarchical structure over them using a grammar-based approach. The resulting hierarchy captures both low-level behaviours and their composition into higher-level skills. We evaluate our approach in high-dimensional, pixel-based environments, including Craftax and the full, unmodified version of Minecraft. Using metrics for skill segmentation, reuse, and hierarchy quality, we find that our method consistently produces more structured and semantically meaningful hierarchies than existing baselines. Furthermore, as a proof of concept for utility, we demonstrate that these discovered hierarchies accelerate and stabilise learning on downstream reinforcement learning tasks.
Mortar: Evolving Mechanics for Automatic Game Design
Dec 31, 2025We present Mortar, a system for autonomously evolving game mechanics for automatic game design. Game mechanics define the rules and interactions that govern gameplay, and designing them manually is a time-consuming and expert-driven process. Mortar combines a quality-diversity algorithm with a large language model to explore a diverse set of mechanics, which are evaluated by synthesising complete games that incorporate both evolved mechanics and those drawn from an archive. The mechanics are evaluated by composing complete games through a tree search procedure, where the resulting games are evaluated by their ability to preserve a skill-based ordering over players -- that is, whether stronger players consistently outperform weaker ones. We assess the mechanics based on their contribution towards the skill-based ordering score in the game. We demonstrate that Mortar produces games that appear diverse and playable, and mechanics that contribute more towards the skill-based ordering score in the game. We perform ablation studies to assess the role of each system component and a user study to evaluate the games based on human feedback.
Word2Minecraft: Generating 3D Game Levels through Large Language Models
Mar 18, 2025We present Word2Minecraft, a system that leverages large language models to generate playable game levels in Minecraft based on structured stories. The system transforms narrative elements-such as protagonist goals, antagonist challenges, and environmental settings-into game levels with both spatial and gameplay constraints. We introduce a flexible framework that allows for the customization of story complexity, enabling dynamic level generation. The system employs a scaling algorithm to maintain spatial consistency while adapting key game elements. We evaluate Word2Minecraft using both metric-based and human-based methods. Our results show that GPT-4-Turbo outperforms GPT-4o-Mini in most areas, including story coherence and objective enjoyment, while the latter excels in aesthetic appeal. We also demonstrate the system' s ability to generate levels with high map enjoyment, offering a promising step forward in the intersection of story generation and game design. We open-source the code at https://github.com/JMZ-kk/Word2Minecraft/tree/word2mc_v0
GameTraversalBenchmark: Evaluating Planning Abilities Of Large Language Models Through Traversing 2D Game Maps
Oct 10, 2024



Large language models (LLMs) have recently demonstrated great success in generating and understanding natural language. While they have also shown potential beyond the domain of natural language, it remains an open question as to what extent and in which way these LLMs can plan. We investigate their planning capabilities by proposing GameTraversalBenchmark (GTB), a benchmark consisting of diverse 2D grid-based game maps. An LLM succeeds if it can traverse through given objectives, with a minimum number of steps and a minimum number of generation errors. We evaluate a number of LLMs on GTB and found that GPT-4-Turbo achieved the highest score of 44.97% on GTB\_Score (GTBS), a composite score that combines the three above criteria. Furthermore, we preliminarily test large reasoning models, namely o1, which scores $67.84\%$ on GTBS, indicating that the benchmark remains challenging for current models. Code, data, and documentation are available at https://github.com/umair-nasir14/Game-Traversal-Benchmark.
Word2World: Generating Stories and Worlds through Large Language Models
May 06, 2024Large Language Models (LLMs) have proven their worth across a diverse spectrum of disciplines. LLMs have shown great potential in Procedural Content Generation (PCG) as well, but directly generating a level through a pre-trained LLM is still challenging. This work introduces Word2World, a system that enables LLMs to procedurally design playable games through stories, without any task-specific fine-tuning. Word2World leverages the abilities of LLMs to create diverse content and extract information. Combining these abilities, LLMs can create a story for the game, design narrative, and place tiles in appropriate places to create coherent worlds and playable games. We test Word2World with different LLMs and perform a thorough ablation study to validate each step. We open-source the code at https://github.com/umair-nasir14/Word2World.
MinePlanner: A Benchmark for Long-Horizon Planning in Large Minecraft Worlds
Dec 20, 2023We propose a new benchmark for planning tasks based on the Minecraft game. Our benchmark contains 45 tasks overall, but also provides support for creating both propositional and numeric instances of new Minecraft tasks automatically. We benchmark numeric and propositional planning systems on these tasks, with results demonstrating that state-of-the-art planners are currently incapable of dealing with many of the challenges advanced by our new benchmark, such as scaling to instances with thousands of objects. Based on these results, we identify areas of improvement for future planners. Our framework is made available at https://github.com/IretonLiu/mine-pddl/.
Counting Reward Automata: Sample Efficient Reinforcement Learning Through the Exploitation of Reward Function Structure
Dec 18, 2023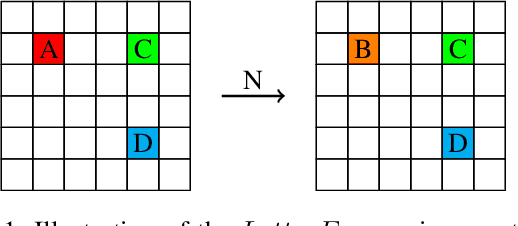
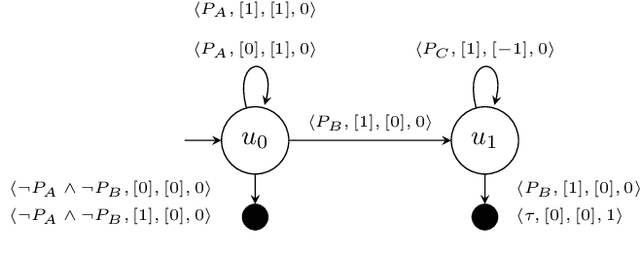
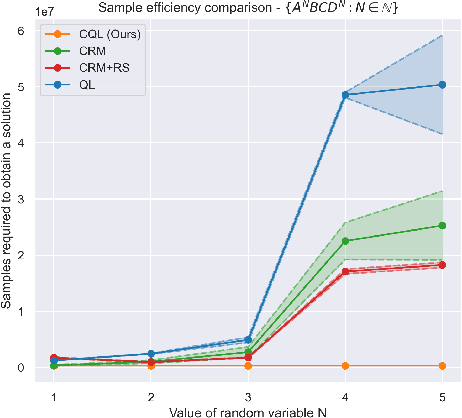
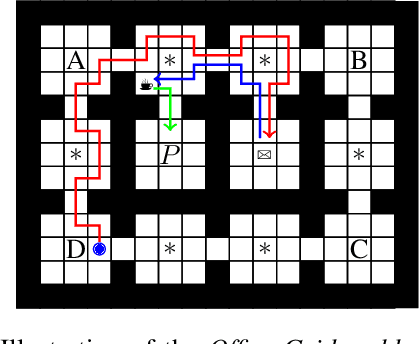
We present counting reward automata-a finite state machine variant capable of modelling any reward function expressible as a formal language. Unlike previous approaches, which are limited to the expression of tasks as regular languages, our framework allows for tasks described by unrestricted grammars. We prove that an agent equipped with such an abstract machine is able to solve a larger set of tasks than those utilising current approaches. We show that this increase in expressive power does not come at the cost of increased automaton complexity. A selection of learning algorithms are presented which exploit automaton structure to improve sample efficiency. We show that the state machines required in our formulation can be specified from natural language task descriptions using large language models. Empirical results demonstrate that our method outperforms competing approaches in terms of sample efficiency, automaton complexity, and task completion.
Dynamics Generalisation in Reinforcement Learning via Adaptive Context-Aware Policies
Oct 25, 2023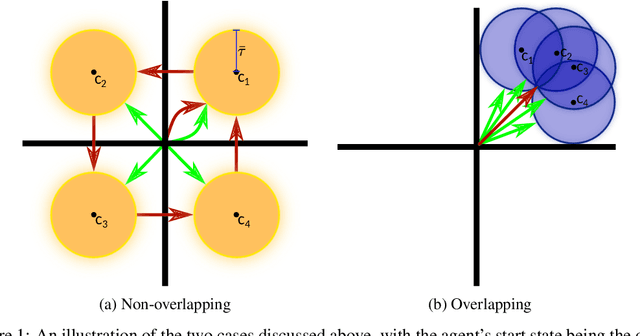
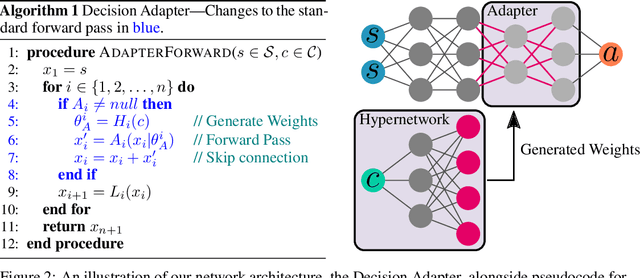
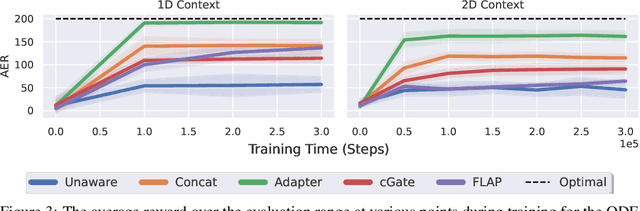
While reinforcement learning has achieved remarkable successes in several domains, its real-world application is limited due to many methods failing to generalise to unfamiliar conditions. In this work, we consider the problem of generalising to new transition dynamics, corresponding to cases in which the environment's response to the agent's actions differs. For example, the gravitational force exerted on a robot depends on its mass and changes the robot's mobility. Consequently, in such cases, it is necessary to condition an agent's actions on extrinsic state information and pertinent contextual information reflecting how the environment responds. While the need for context-sensitive policies has been established, the manner in which context is incorporated architecturally has received less attention. Thus, in this work, we present an investigation into how context information should be incorporated into behaviour learning to improve generalisation. To this end, we introduce a neural network architecture, the Decision Adapter, which generates the weights of an adapter module and conditions the behaviour of an agent on the context information. We show that the Decision Adapter is a useful generalisation of a previously proposed architecture and empirically demonstrate that it results in superior generalisation performance compared to previous approaches in several environments. Beyond this, the Decision Adapter is more robust to irrelevant distractor variables than several alternative methods.
LLMatic: Neural Architecture Search via Large Language Models and Quality-Diversity Optimization
Jun 01, 2023



Large Language Models (LLMs) have emerged as powerful tools capable of accomplishing a broad spectrum of tasks. Their abilities span numerous areas, and one area where they have made a significant impact is in the domain of code generation. In this context, we view LLMs as mutation and crossover tools. Meanwhile, Quality-Diversity (QD) algorithms are known to discover diverse and robust solutions. By merging the code-generating abilities of LLMs with the diversity and robustness of QD solutions, we introduce LLMatic, a Neural Architecture Search (NAS) algorithm. While LLMs struggle to conduct NAS directly through prompts, LLMatic uses a procedural approach, leveraging QD for prompts and network architecture to create diverse and highly performant networks. We test LLMatic on the CIFAR-10 image classification benchmark, demonstrating that it can produce competitive networks with just $2,000$ searches, even without prior knowledge of the benchmark domain or exposure to any previous top-performing models for the benchmark.