 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARiTy: A Vision Transformer for Multi-Label Classification and Weakly-Supervised Localization of Chest X-ray Pathologies
Dec 18, 2025The interpretation of chest X-rays (CXRs) poses significant challenges, particularly in achieving accurate multi-label pathology classification and spatial localization. These tasks demand different levels of annotation granularity but are frequently constrained by the scarcity of region-level (dense) annotations. We introduce CLARiTy (Class Localizing and Attention Refining Image Transformer), a vision transformer-based model for joint multi-label classification and weakly-supervised localization of thoracic pathologies. CLARiTy employs multiple class-specific tokens to generate discriminative attention maps, and a SegmentCAM module for foreground segmentation and background suppression using explicit anatomical priors. Trained on image-level labels from the NIH ChestX-ray14 dataset, it leverages distillation from a ConvNeXtV2 teacher for efficiency. Evaluated on the official NIH split, the CLARiTy-S-16-512 (a configuration of CLARiTy), achieves competitive classification performance across 14 pathologies, and state-of-the-art weakly-supervised localization performance on 8 pathologies, outperforming prior methods by 50.7%. In particular, pronounced gains occur for small pathologies like nodules and masses. The lower-resolution variant of CLARiTy, CLARiTy-S-16-224, offers high efficiency while decisively surpassing baselines, thereby having the potential for use in low-resource settings. An ablation study confirms contributions of SegmentCAM, DINO pretraining, orthogonal class token loss, and attention pooling. CLARiTy advances beyond CNN-ViT hybrids by harnessing ViT self-attention for global context and class-specific localization, refined through convolutional background suppression for precise, noise-reduced heatmaps.
Make Haste Slowly: A Theory of Emergent Structured Mixed Selectivity in Feature Learning ReLU Networks
Mar 08, 2025In spite of finite dimension ReLU neural networks being a consistent factor behind recent deep learning successes, a theory of feature learning in these models remains elusive. Currently, insightful theories still rely on assumptions including the linearity of the network computations, unstructured input data and architectural constraints such as infinite width or a single hidden layer. To begin to address this gap we establish an equivalence between ReLU networks and Gated Deep Linear Networks, and use their greater tractability to derive dynamics of learning. We then consider multiple variants of a core task reminiscent of multi-task learning or contextual control which requires both feature learning and nonlinearity. We make explicit that, for these tasks, the ReLU networks possess an inductive bias towards latent representations which are not strictly modular or disentangled but are still highly structured and reusable between contexts. This effect is amplified with the addition of more contexts and hidden layers. Thus, we take a step towards a theory of feature learning in finite ReLU networks and shed light on how structured mixed-selective latent representations can emerge due to a bias for node-reuse and learning speed.
Revisiting the Role of Relearning in Semantic Dementia
Mar 05, 2025Patients with semantic dementia (SD) present with remarkably consistent atrophy of neurons in the anterior temporal lobe and behavioural impairments, such as graded loss of category knowledge. While relearning of lost knowledge has been shown in acute brain injuries such as stroke, it has not been widely supported in chronic cognitive diseases such as SD. Previous research has shown that deep linear artificial neural networks exhibit stages of semantic learning akin to humans. Here, we use a deep linear network to test the hypothesis that relearning during disease progression rather than particular atrophy cause the specific behavioural patterns associated with SD. After training the network to generate the common semantic features of various hierarchically organised objects, neurons are successively deleted to mimic atrophy while retraining the model. The model with relearning and deleted neurons reproduced errors specific to SD, including prototyping errors and cross-category confusions. This suggests that relearning is necessary for artificial neural networks to reproduce the behavioural patterns associated with SD in the absence of \textit{output} non-linearities. Our results support a theory of SD progression that results from continuous relearning of lost information. Future research should revisit the role of relearning as a contributing factor to cognitive diseases.
A Large-scale Evaluation of Pretraining Paradigms for the Detection of Defects in Electroluminescence Solar Cell Images
Feb 27, 2024
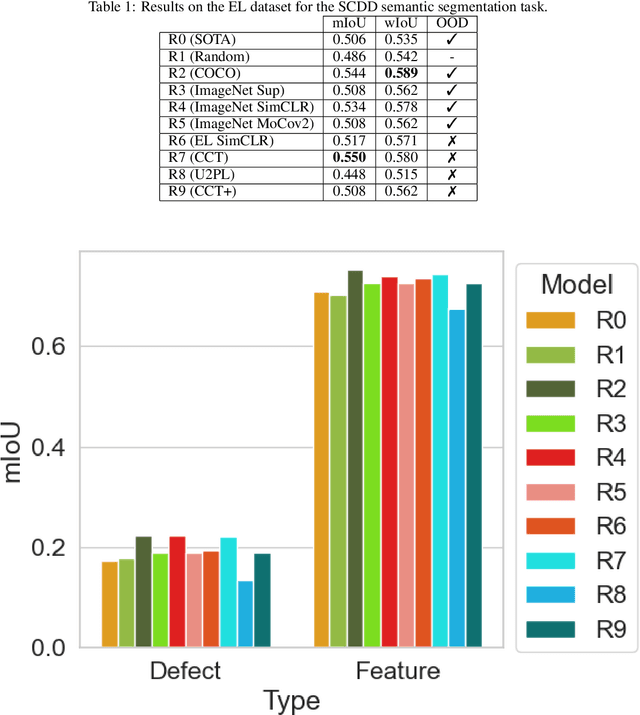
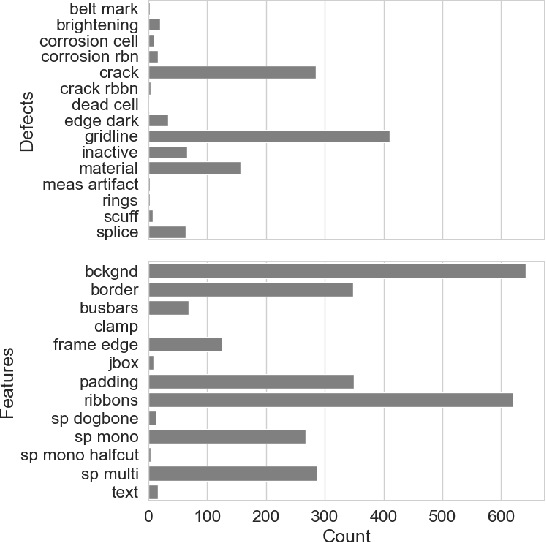

Pretraining has been shown to improve performance in many domains, including semantic segmentation, especially in domains with limited labelled data. In this work, we perform a large-scale evaluation and benchmarking of various pretraining methods for Solar Cell Defect Detection (SCDD) in electroluminescence images, a field with limited labelled datasets. We cover supervised training with semantic segmentation, semi-supervised learning, and two self-supervised techniques. We also experiment with both in-distribution and out-of-distribution (OOD) pretraining and observe how this affects downstream performance. The results suggest that supervised training on a large OOD dataset (COCO), self-supervised pretraining on a large OOD dataset (ImageNet), and semi-supervised pretraining (CCT) all yield statistically equivalent performance for mean Intersection over Union (mIoU). We achieve a new state-of-the-art for SCDD and demonstrate that certain pretraining schemes result in superior performance on underrepresented classes. Additionally, we provide a large-scale unlabelled EL image dataset of $22000$ images, and a $642$-image labelled semantic segmentation EL dataset, for further research in developing self- and semi-supervised training techniques in this domain.
DeepSet SimCLR: Self-supervised deep sets for improved pathology representation learning
Feb 23, 2024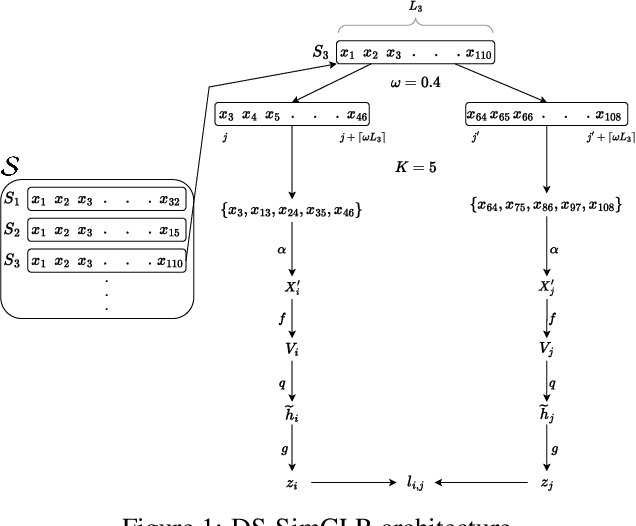

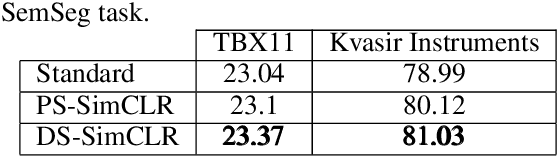
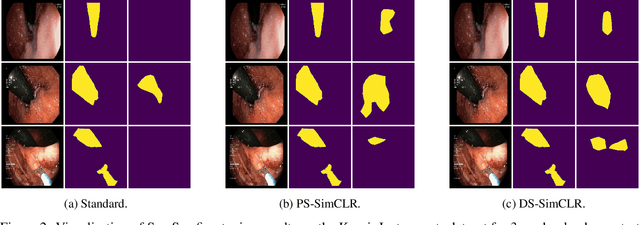
Often, applications of self-supervised learning to 3D medical data opt to use 3D variants of successful 2D network architectures. Although promising approaches, they are significantly more computationally demanding to train, and thus reduce the widespread applicability of these methods away from those with modest computational resources. Thus, in this paper, we aim to improve standard 2D SSL algorithms by modelling the inherent 3D nature of these datasets implicitly. We propose two variants that build upon a strong baseline model and show that both of these variants often outperform the baseline in a variety of downstream tasks. Importantly, in contrast to previous works in both 2D and 3D approaches for 3D medical data, both of our proposals introduce negligible additional overhead over the baseline, improving the democratisation of these approaches for medical applications.
Affine transformation estimation improves visual self-supervised learning
Feb 14, 2024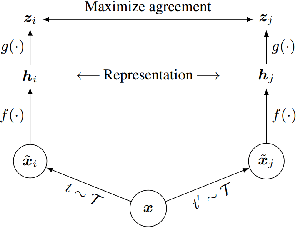
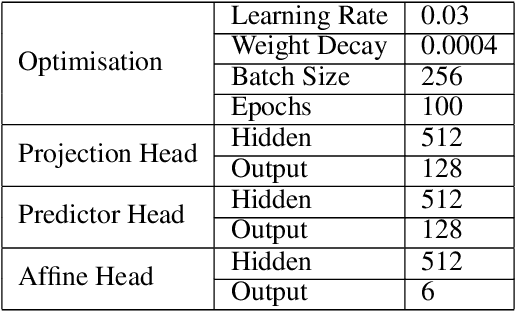
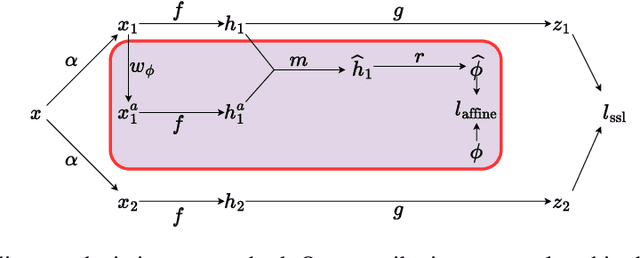
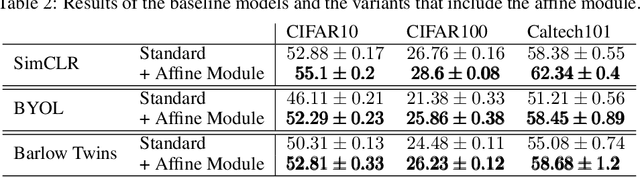
The standard approach to modern self-supervised learning is to generate random views through data augmentations and minimise a loss computed from the representations of these views. This inherently encourages invariance to the transformations that comprise the data augmentation function. In this work, we show that adding a module to constrain the representations to be predictive of an affine transformation improves the performance and efficiency of the learning process. The module is agnostic to the base self-supervised model and manifests in the form of an additional loss term that encourages an aggregation of the encoder representations to be predictive of an affine transformation applied to the input images. We perform experiments in various modern self-supervised models and see a performance improvement in all cases. Further, we perform an ablation study on the components of the affine transformation to understand which of them is affecting performance the most, as well as on key architectural design decisions.
Dynamics Generalisation in Reinforcement Learning via Adaptive Context-Aware Policies
Oct 25, 2023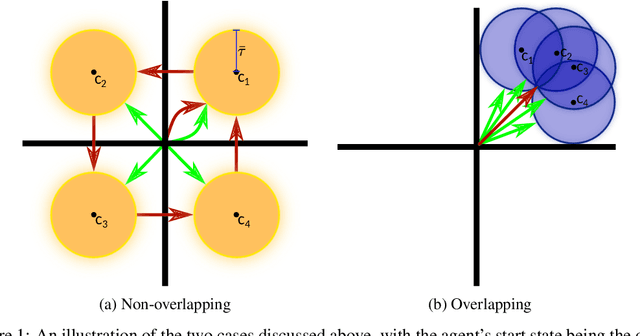
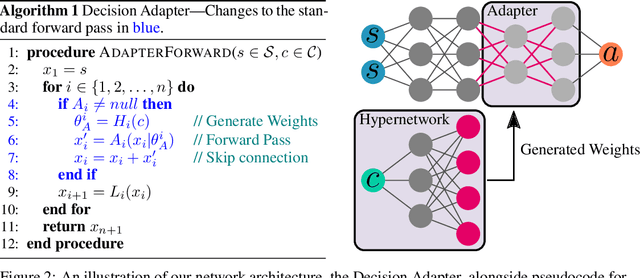
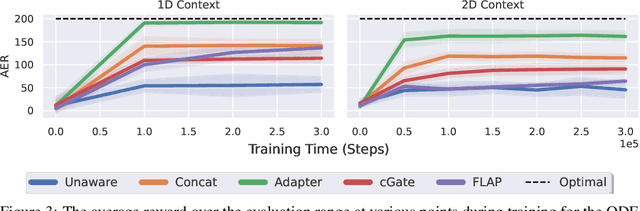
While reinforcement learning has achieved remarkable successes in several domains, its real-world application is limited due to many methods failing to generalise to unfamiliar conditions. In this work, we consider the problem of generalising to new transition dynamics, corresponding to cases in which the environment's response to the agent's actions differs. For example, the gravitational force exerted on a robot depends on its mass and changes the robot's mobility. Consequently, in such cases, it is necessary to condition an agent's actions on extrinsic state information and pertinent contextual information reflecting how the environment responds. While the need for context-sensitive policies has been established, the manner in which context is incorporated architecturally has received less attention. Thus, in this work, we present an investigation into how context information should be incorporated into behaviour learning to improve generalisation. To this end, we introduce a neural network architecture, the Decision Adapter, which generates the weights of an adapter module and conditions the behaviour of an agent on the context information. We show that the Decision Adapter is a useful generalisation of a previously proposed architecture and empirically demonstrate that it results in superior generalisation performance compared to previous approaches in several environments. Beyond this, the Decision Adapter is more robust to irrelevant distractor variables than several alternative methods.
On the robustness of self-supervised representations for multi-view object classification
Jul 27, 2022
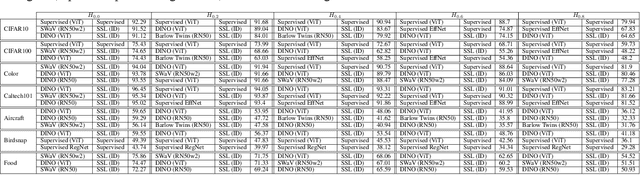
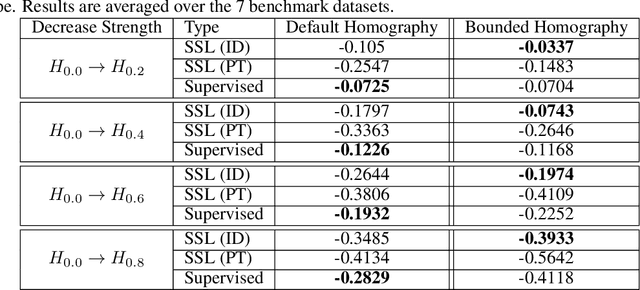
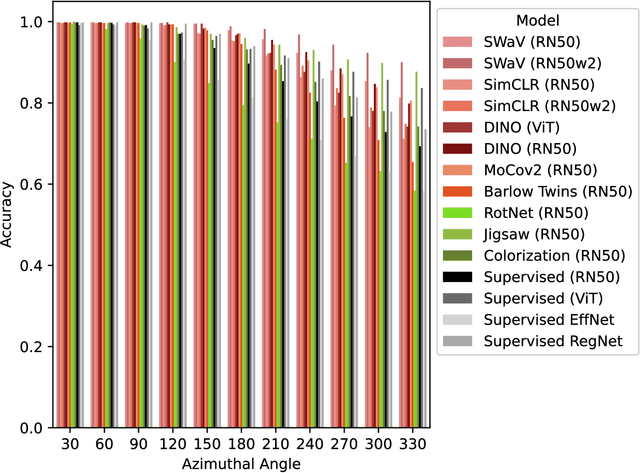
It is known that representations from self-supervised pre-training can perform on par, and often better, on various downstream tasks than representations from fully-supervised pre-training. This has been shown in a host of settings such as generic object classification and detection, semantic segmentation, and image retrieval. However, some issues have recently come to the fore that demonstrate some of the failure modes of self-supervised representations, such as performance on non-ImageNet-like data, or complex scenes. In this paper, we show that self-supervised representations based on the instance discrimination objective lead to better representations of objects that are more robust to changes in the viewpoint and perspective of the object. We perform experiments of modern self-supervised methods against multiple supervised baselines to demonstrate this, including approximating object viewpoint variation through homographies, and real-world tests based on several multi-view datasets. We find that self-supervised representations are more robust to object viewpoint and appear to encode more pertinent information about objects that facilitate the recognition of objects from novel views.
Accounting for the Sequential Nature of States to Learn Features for Reinforcement Learning
May 12, 2022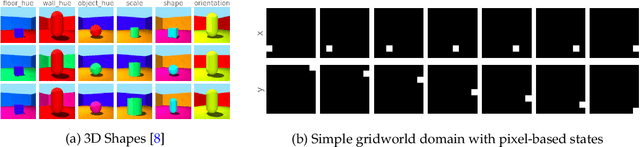
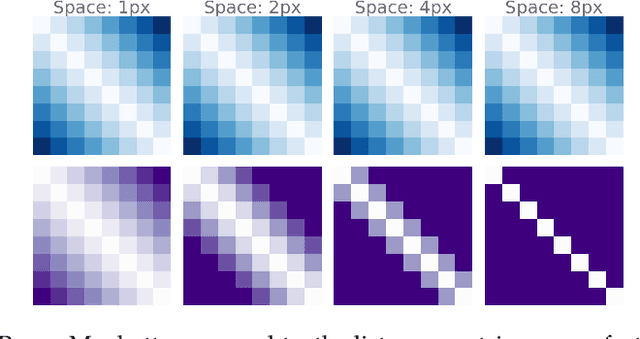
In this work, we investigate the properties of data that cause popular representation learning approaches to fail. In particular, we find that in environments where states do not significantly overlap, variational autoencoders (VAEs) fail to learn useful features. We demonstrate this failure in a simple gridworld domain, and then provide a solution in the form of metric learning. However, metric learning requires supervision in the form of a distance function, which is absent in reinforcement learning. To overcome this, we leverage the sequential nature of states in a replay buffer to approximate a distance metric and provide a weak supervision signal, under the assumption that temporally close states are also semantically similar. We modify a VAE with triplet loss and demonstrate that this approach is able to learn useful features for downstream tasks, without additional supervision, in environments where standard VAEs fail.
Data Overlap: A Prerequisite For Disentanglement
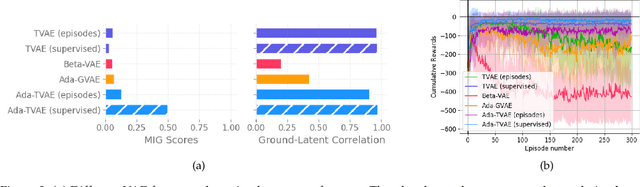
Feb 27, 2022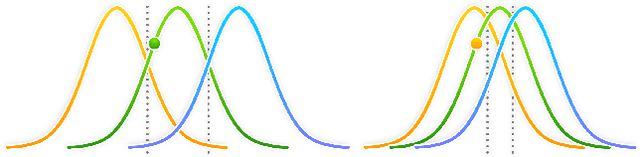
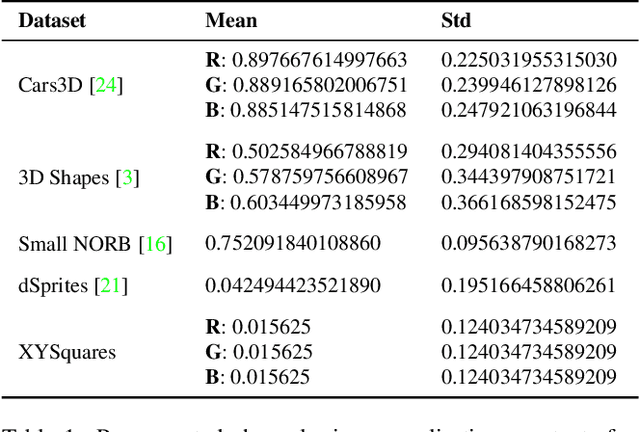


Learning disentangled representations with variational autoencoders (VAEs) is often attributed to the regularisation component of the loss. In this work, we highlight the interaction between data and the reconstruction term of the loss as the main contributor to disentanglement in VAEs. We note that standardised benchmark datasets are constructed in a way that is conducive to learning what appear to be disentangled representations. We design an intuitive adversarial dataset that exploits this mechanism to break existing state-of-the-art disentanglement frameworks. Finally, we provide solutions in the form of a modified reconstruction loss suggesting that VAEs are accidental distance learners.