 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the robustness of self-supervised representations for multi-view object classification
Paper and Code

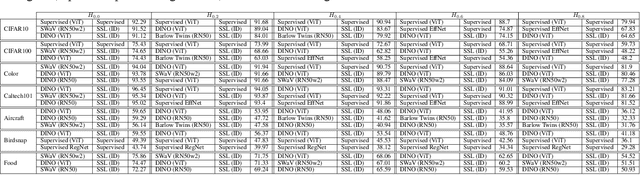
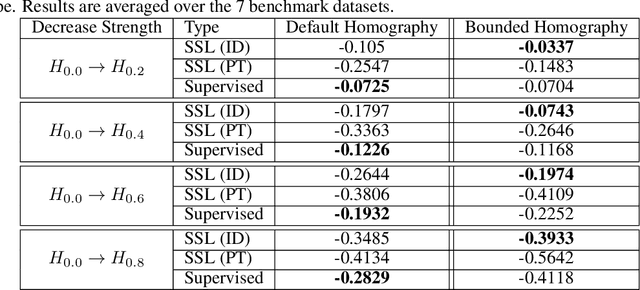
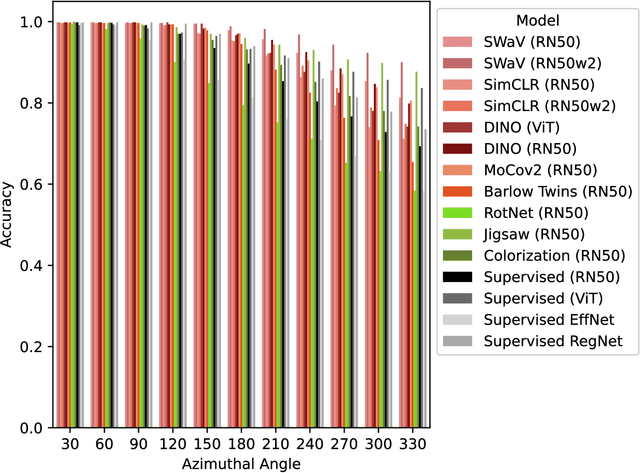
It is known that representations from self-supervised pre-training can perform on par, and often better, on various downstream tasks than representations from fully-supervised pre-training. This has been shown in a host of settings such as generic object classification and detection, semantic segmentation, and image retrieval. However, some issues have recently come to the fore that demonstrate some of the failure modes of self-supervised representations, such as performance on non-ImageNet-like data, or complex scenes. In this paper, we show that self-supervised representations based on the instance discrimination objective lead to better representations of objects that are more robust to changes in the viewpoint and perspective of the object. We perform experiments of modern self-supervised methods against multiple supervised baselines to demonstrate this, including approximating object viewpoint variation through homographies, and real-world tests based on several multi-view datasets. We find that self-supervised representations are more robust to object viewpoint and appear to encode more pertinent information about objects that facilitate the recognition of objects from novel views.