 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Evaluation of Pretraining Paradigms for the Detection of Defects in Electroluminescence Solar Cell Images
Feb 27, 2024
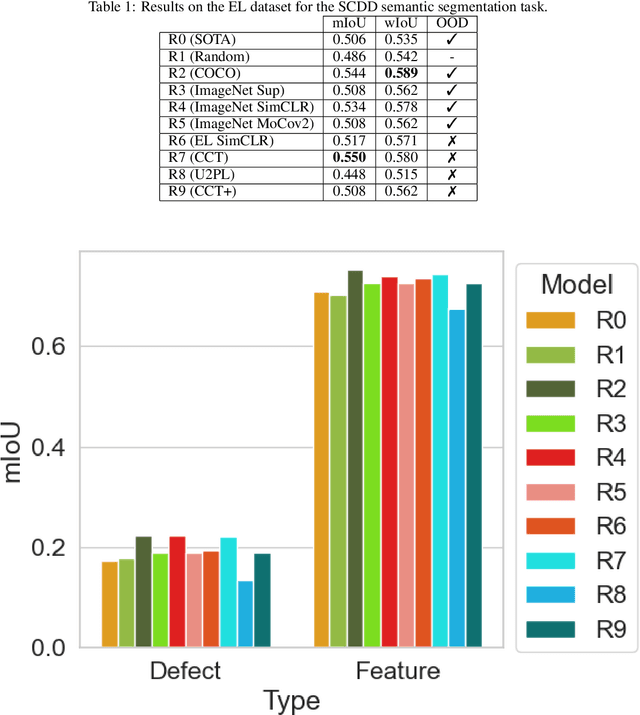
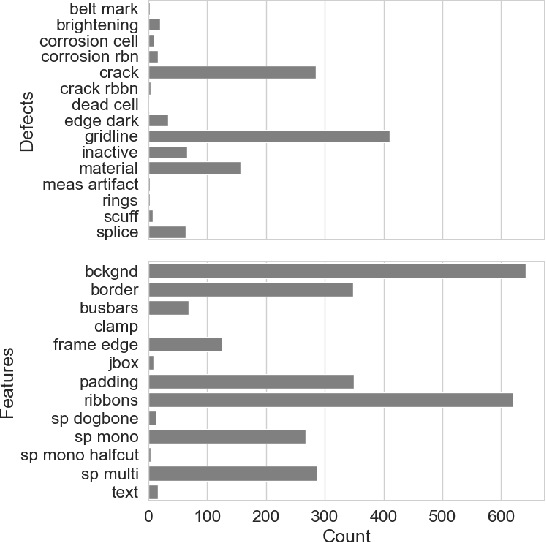

Pretraining has been shown to improve performance in many domains, including semantic segmentation, especially in domains with limited labelled data. In this work, we perform a large-scale evaluation and benchmarking of various pretraining methods for Solar Cell Defect Detection (SCDD) in electroluminescence images, a field with limited labelled datasets. We cover supervised training with semantic segmentation, semi-supervised learning, and two self-supervised techniques. We also experiment with both in-distribution and out-of-distribution (OOD) pretraining and observe how this affects downstream performance. The results suggest that supervised training on a large OOD dataset (COCO), self-supervised pretraining on a large OOD dataset (ImageNet), and semi-supervised pretraining (CCT) all yield statistically equivalent performance for mean Intersection over Union (mIoU). We achieve a new state-of-the-art for SCDD and demonstrate that certain pretraining schemes result in superior performance on underrepresented classes. Additionally, we provide a large-scale unlabelled EL image dataset of $22000$ images, and a $642$-image labelled semantic segmentation EL dataset, for further research in developing self- and semi-supervised training techniques in this domain.
DeepSet SimCLR: Self-supervised deep sets for improved pathology representation learning
Feb 23, 2024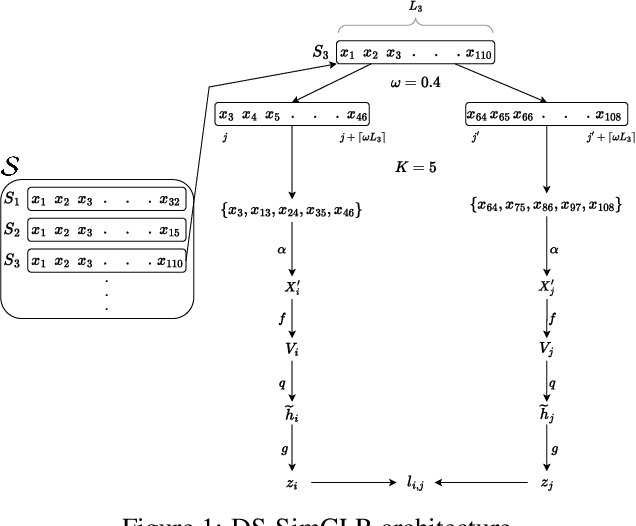

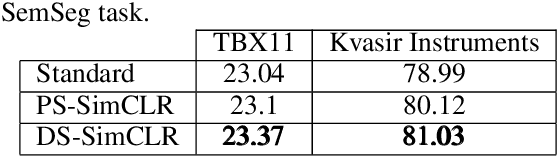
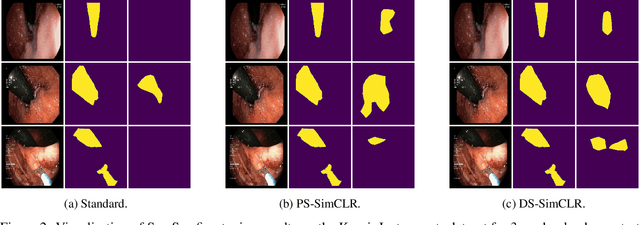
Often, applications of self-supervised learning to 3D medical data opt to use 3D variants of successful 2D network architectures. Although promising approaches, they are significantly more computationally demanding to train, and thus reduce the widespread applicability of these methods away from those with modest computational resources. Thus, in this paper, we aim to improve standard 2D SSL algorithms by modelling the inherent 3D nature of these datasets implicitly. We propose two variants that build upon a strong baseline model and show that both of these variants often outperform the baseline in a variety of downstream tasks. Importantly, in contrast to previous works in both 2D and 3D approaches for 3D medical data, both of our proposals introduce negligible additional overhead over the baseline, improving the democratisation of these approaches for medical applications.
Affine transformation estimation improves visual self-supervised learning
Feb 14, 2024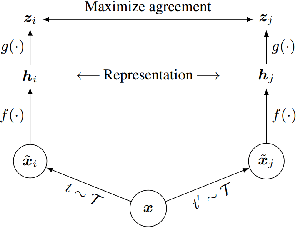
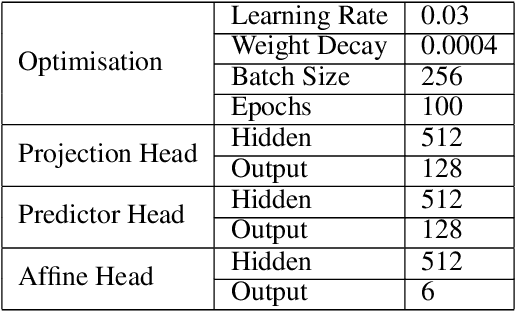
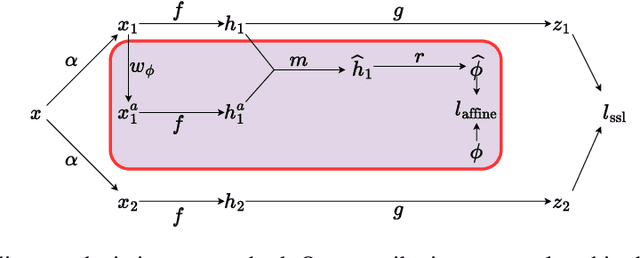
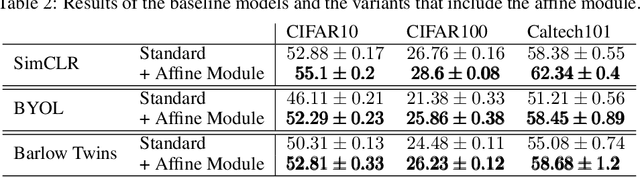
The standard approach to modern self-supervised learning is to generate random views through data augmentations and minimise a loss computed from the representations of these views. This inherently encourages invariance to the transformations that comprise the data augmentation function. In this work, we show that adding a module to constrain the representations to be predictive of an affine transformation improves the performance and efficiency of the learning process. The module is agnostic to the base self-supervised model and manifests in the form of an additional loss term that encourages an aggregation of the encoder representations to be predictive of an affine transformation applied to the input images. We perform experiments in various modern self-supervised models and see a performance improvement in all cases. Further, we perform an ablation study on the components of the affine transformation to understand which of them is affecting performance the most, as well as on key architectural design decisions.
On the robustness of self-supervised representations for multi-view object classification
Jul 27, 2022
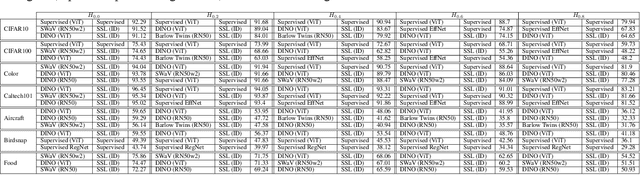
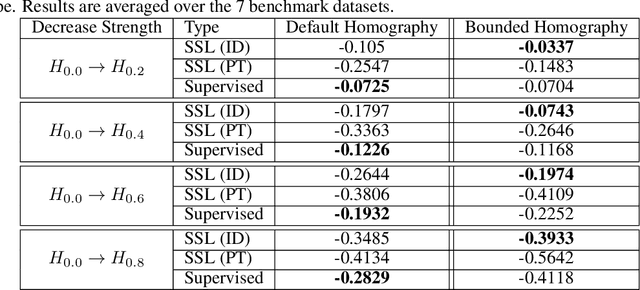
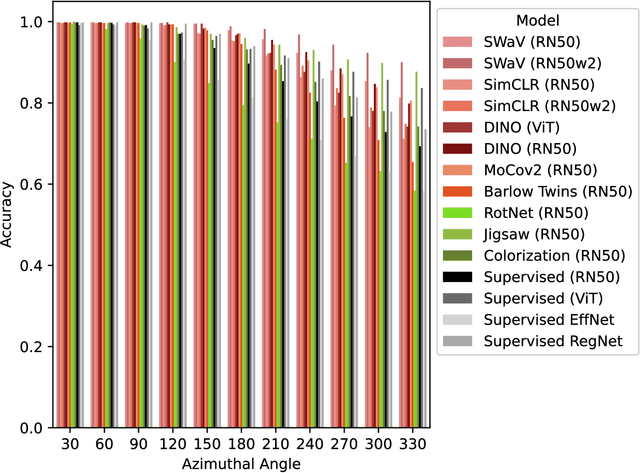
It is known that representations from self-supervised pre-training can perform on par, and often better, on various downstream tasks than representations from fully-supervised pre-training. This has been shown in a host of settings such as generic object classification and detection, semantic segmentation, and image retrieval. However, some issues have recently come to the fore that demonstrate some of the failure modes of self-supervised representations, such as performance on non-ImageNet-like data, or complex scenes. In this paper, we show that self-supervised representations based on the instance discrimination objective lead to better representations of objects that are more robust to changes in the viewpoint and perspective of the object. We perform experiments of modern self-supervised methods against multiple supervised baselines to demonstrate this, including approximating object viewpoint variation through homographies, and real-world tests based on several multi-view datasets. We find that self-supervised representations are more robust to object viewpoint and appear to encode more pertinent information about objects that facilitate the recognition of objects from novel views.
Explicit homography estimation improves contrastive self-supervised learning
Jan 12, 2021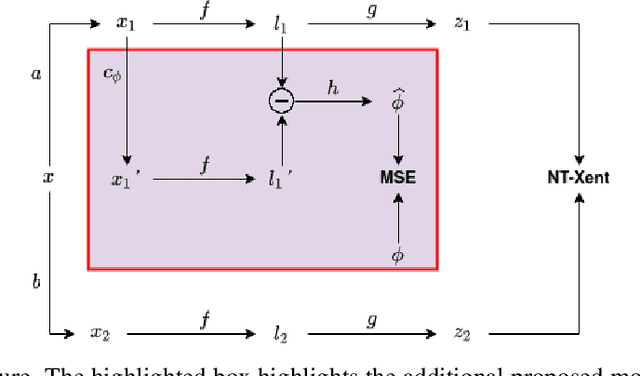

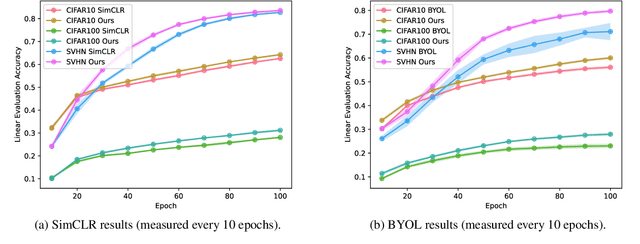
The typical contrastive self-supervised algorithm uses a similarity measure in latent space as the supervision signal by contrasting positive and negative images directly or indirectly. Although the utility of self-supervised algorithms has improved recently, there are still bottlenecks hindering their widespread use, such as the compute needed. In this paper, we propose a module that serves as an additional objective in the self-supervised contrastive learning paradigm. We show how the inclusion of this module to regress the parameters of an affine transformation or homography, in addition to the original contrastive objective, improves both performance and learning speed. Importantly, we ensure that this module does not enforce invariance to the various components of the affine transform, as this is not always ideal. We demonstrate the effectiveness of the additional objective on two recent, popular self-supervised algorithms. We perform an extensive experimental analysis of the proposed method and show an improvement in performance for all considered datasets. Further, we find that although both the general homography and affine transformation are sufficient to improve performance and convergence, the affine transformation performs better in all cases.
SummaryNet: A Multi-Stage Deep Learning Model for Automatic Video Summarisation
Feb 19, 2020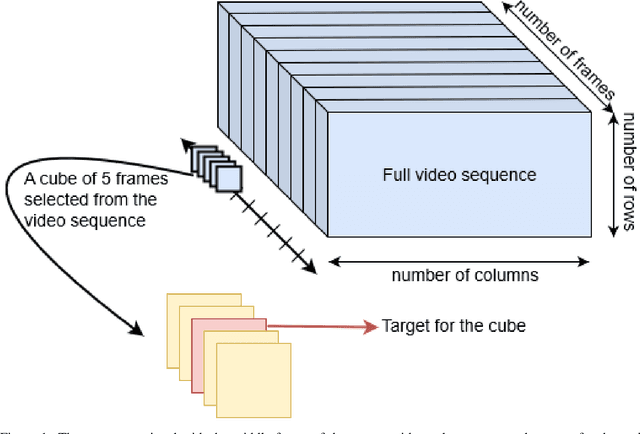
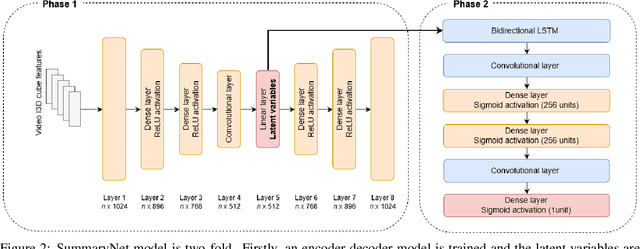
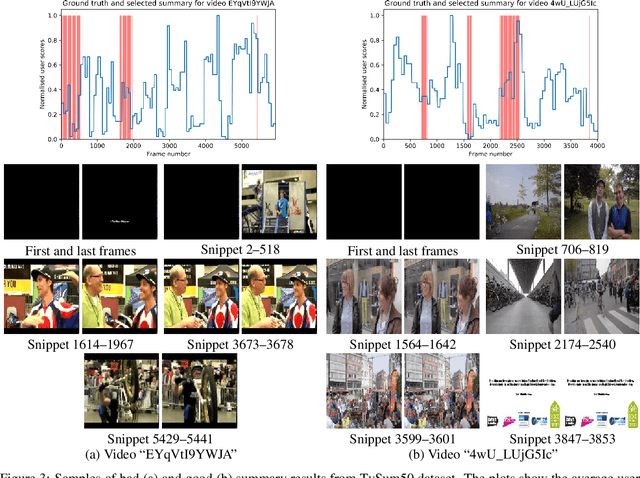
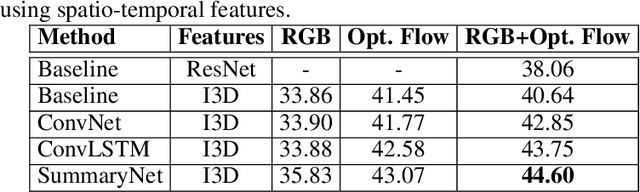
Video summarisation can be posed as the task of extracting important parts of a video in order to create an informative summary of what occurred in the video. In this paper we introduce SummaryNet as a supervised learning framework for automated video summarisation. SummaryNet employs a two-stream convolutional network to learn spatial (appearance) and temporal (motion) representations. It utilizes an encoder-decoder model to extract the most salient features from the learned video representations. Lastly, it uses a sigmoid regression network with bidirectional long short-term memory cells to predict the probability of a frame being a summary frame. Experimental results on benchmark datasets show that the proposed method achieves comparable or significantly better results than the state-of-the-art video summarisation methods.
Human Action Recognition using Local Two-Stream Convolution Neural Network Features and Support Vector Machines
Feb 19, 2020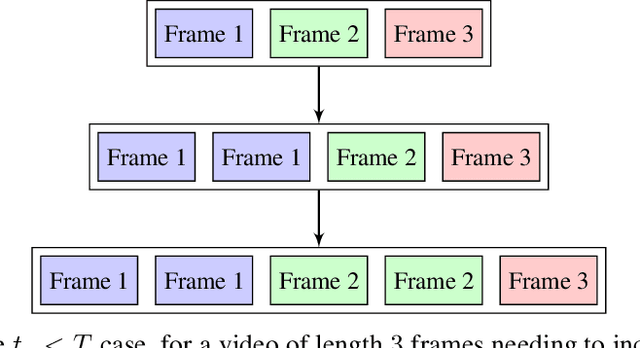
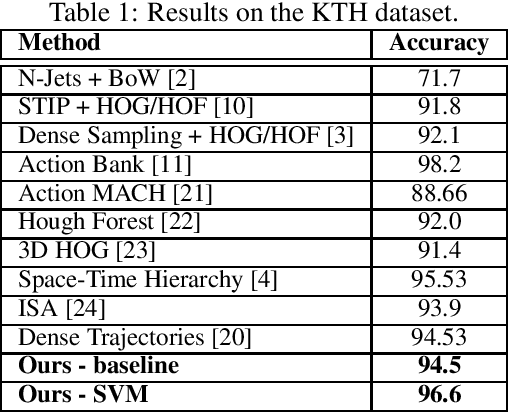

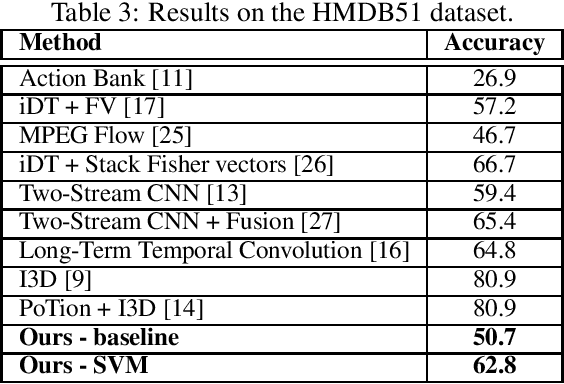
This paper proposes a simple yet effective method for human action recognition in video. The proposed method separately extracts local appearance and motion features using state-of-the-art three-dimensional convolutional neural networks from sampled snippets of a video. These local features are then concatenated to form global representations which are then used to train a linear SVM to perform the action classification using full context of the video, as partial context as used in previous works. The videos undergo two simple proposed preprocessing techniques, optical flow scaling and crop filling. We perform an extensive evaluation on three common benchmark dataset to empirically show the benefit of the SVM, and the two preprocessing steps.