 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Generalizable Pre-training for Real-world Change Detection via Geometric Estimation
Apr 19, 2025As an essential procedure in earth observation system, change detection (CD) aims to reveal the spatial-temporal evolution of the observation regions. A key prerequisite for existing change detection algorithms is aligned geo-references between multi-temporal images by fine-grained registration. However, in the majority of real-world scenarios, a prior manual registration is required between the original images, which significantly increases the complexity of the CD workflow. In this paper, we proposed a self-supervision motivated CD framework with geometric estimation, called "MatchCD". Specifically, the proposed MatchCD framework utilizes the zero-shot capability to optimize the encoder with self-supervised contrastive representation, which is reused in the downstream image registration and change detection to simultaneously handle the bi-temporal unalignment and object change issues. Moreover, unlike the conventional change detection requiring segmenting the full-frame image into small patches, our MatchCD framework can directly process the original large-scale image (e.g., 6K*4K resolutions) with promising performance. The performance in multiple complex scenarios with significant geometric distortion demonstrates the effectiveness of our proposed framework.
SSLChange: A Self-supervised Change Detection Framework Based on Domain Adaptation
May 28, 2024



In conventional remote sensing change detection (RS CD) procedures, extensive manual labeling for bi-temporal images is first required to maintain the performance of subsequent fully supervised training. However, pixel-level labeling for CD tasks is very complex and time-consuming. In this paper, we explore a novel self-supervised contrastive framework applicable to the RS CD task, which promotes the model to accurately capture spatial, structural, and semantic information through domain adapter and hierarchical contrastive head. The proposed SSLChange framework accomplishes self-learning only by taking a single-temporal sample and can be flexibly transferred to main-stream CD baselines. With self-supervised contrastive learning, feature representation pre-training can be performed directly based on the original data even without labeling. After a certain amount of labels are subsequently obtained, the pre-trained features will be aligned with the labels for fully supervised fine-tuning. Without introducing any additional data or labels, the performance of downstream baselines will experience a significant enhancement. Experimental results on 2 entire datasets and 6 diluted datasets show that our proposed SSLChange improves the performance and stability of CD baseline in data-limited situations. The code of SSLChange will be released at \url{https://github.com/MarsZhaoYT/SSLChange}
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
May 03, 2024



Facial Expression Recognition (FER) plays a pivotal role in understanding human emotional cues. However, traditional FER methods based on visual information have some limitations, such as preprocessing, feature extraction, and multi-stage classification procedures. These not only increase computational complexity but also require a significant amount of computing resources. Considering Convolutional Neural Network (CNN)-based FER schemes frequently prove inadequate in identifying the deep, long-distance dependencies embedded within facial expression images, and the Transformer's inherent quadratic computational complexity, this paper presents the FER-YOLO-Mamba model, which integrates the principles of Mamba and YOLO technologies to facilitate efficient coordination in facial expression image recognition and localization. Within the FER-YOLO-Mamba model, we further devise a FER-YOLO-VSS dual-branch module, which combines the inherent strengths of convolutional layers in local feature extraction with the exceptional capability of State Space Models (SSMs) in revealing long-distance dependencies. To the best of our knowledge, this is the first Vision Mamba model designed for facial expression detection and classification. To evaluate the performance of the proposed FER-YOLO-Mamba model, we conducted experiments on two benchmark datasets, RAF-DB and SFEW. The experimental results indicate that the FER-YOLO-Mamba model achieved better results compared to other models. The code is available from https://github.com/SwjtuMa/FER-YOLO-Mamba.
Integrating Bidirectional Long Short-Term Memory with Subword Embedding for Authorship Attribution
Jun 26, 2023



The problem of unveiling the author of a given text document from multiple candidate authors is called authorship attribution. Manifold word-based stylistic markers have been successfully used in deep learning methods to deal with the intrinsic problem of authorship attribution. Unfortunately, the performance of word-based authorship attribution systems is limited by the vocabulary of the training corpus. Literature has recommended character-based stylistic markers as an alternative to overcome the hidden word problem. However, character-based methods often fail to capture the sequential relationship of words in texts which is a chasm for further improvement. The question addressed in this paper is whether it is possible to address the ambiguity of hidden words in text documents while preserving the sequential context of words. Consequently, a method based on bidirectional long short-term memory (BLSTM) with a 2-dimensional convolutional neural network (CNN) is proposed to capture sequential writing styles for authorship attribution. The BLSTM was used to obtain the sequential relationship among characteristics using subword information. The 2-dimensional CNN was applied to understand the local syntactical position of the style from unlabeled input text. The proposed method was experimentally evaluated against numerous state-of-the-art methods across the public corporal of CCAT50, IMDb62, Blog50, and Twitter50. Experimental results indicate accuracy improvement of 1.07\%, and 0.96\% on CCAT50 and Twitter, respectively, and produce comparable results on the remaining datasets.
Transformation-Invariant Network for Few-Shot Object Detection in Remote Sensing Images
Mar 13, 2023
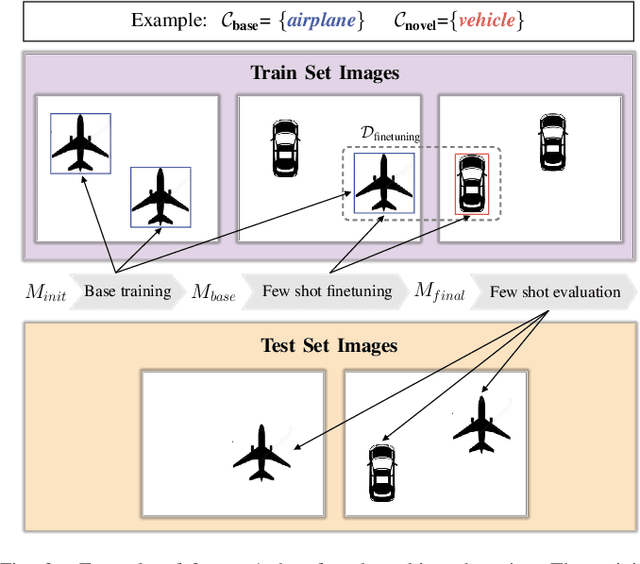
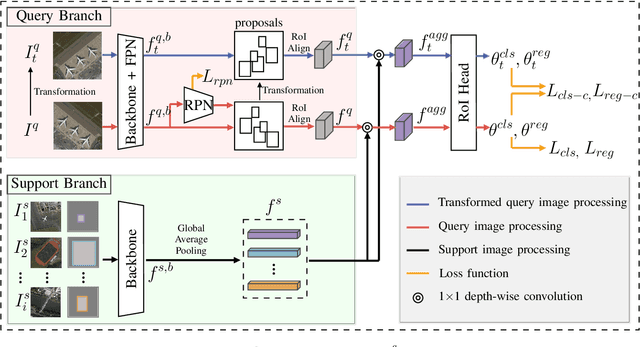
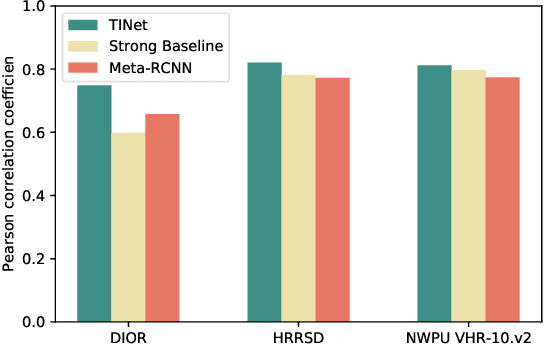
Object detection in remote sensing images relies on a large amount of labeled data for training. The growing new categories and class imbalance render exhaustive annotation non-scalable. Few-shot object detection~(FSOD) tackles this issue by meta-learning on seen base classes and then fine-tuning on novel classes with few labeled samples. However, the object's scale and orientation variations are particularly large in remote sensing images, thus posing challenges to existing few-shot object detection methods. To tackle these challenges, we first propose to integrate a feature pyramid network and use prototype features to highlight query features to improve upon existing FSOD methods. We refer to the modified FSOD as a Strong Baseline which is demonstrated to perform significantly better than the original baselines. To improve the robustness of orientation variation, we further propose a transformation-invariant network (TINet) to allow the network to be invariant to geometric transformations. Extensive experiments on three widely used remote sensing object detection datasets, i.e., NWPU VHR-10.v2, DIOR, and HRRSD demonstrated the effectiveness of the proposed method. Finally, we reproduced multiple FSOD methods for remote sensing images to create an extensive benchmark for follow-up works.
The Wits Intelligent Teaching System: Detecting Student Engagement During Lectures Using Convolutional Neural Networks
May 28, 2021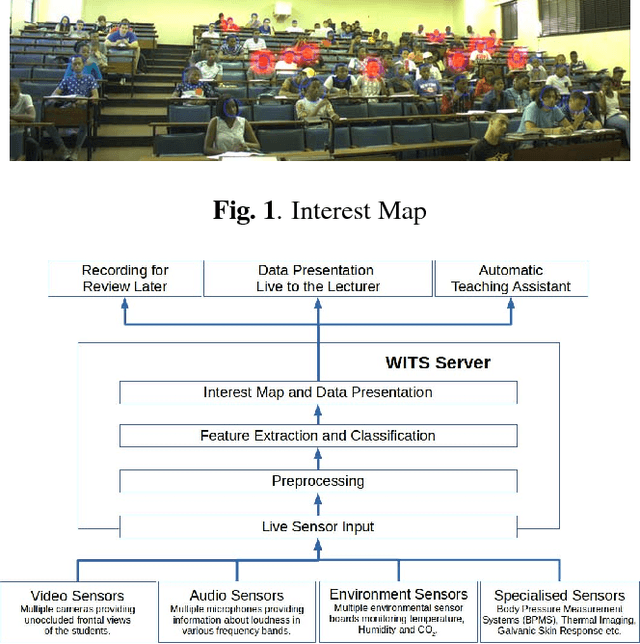
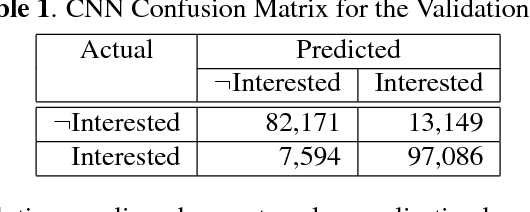
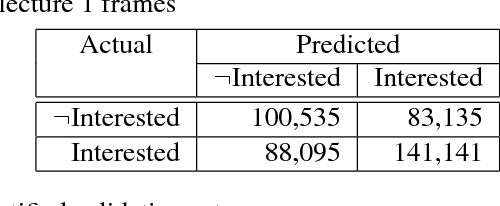

To perform contingent teaching and be responsive to students' needs during class, lecturers must be able to quickly assess the state of their audience. While effective teachers are able to gauge easily the affective state of the students, as class sizes grow this becomes increasingly difficult and less precise. The Wits Intelligent Teaching System (WITS) aims to assist lecturers with real-time feedback regarding student affect. The focus is primarily on recognising engagement or lack thereof. Student engagement is labelled based on behaviour and postures that are common to classroom settings. These proxies are then used in an observational checklist to construct a dataset of engagement upon which a CNN based on AlexNet is successfully trained and which significantly outperforms a Support Vector Machine approach. The deep learning approach provides satisfactory results on a challenging, real-world dataset with significant occlusion, lighting and resolution constraints.
SummaryNet: A Multi-Stage Deep Learning Model for Automatic Video Summarisation
Feb 19, 2020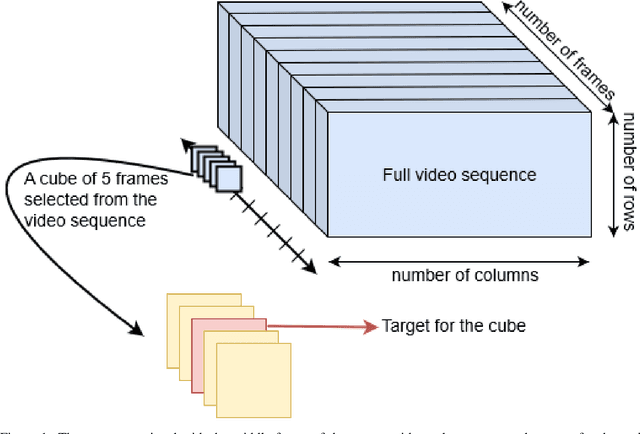
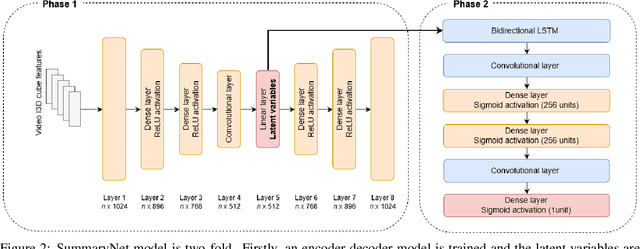
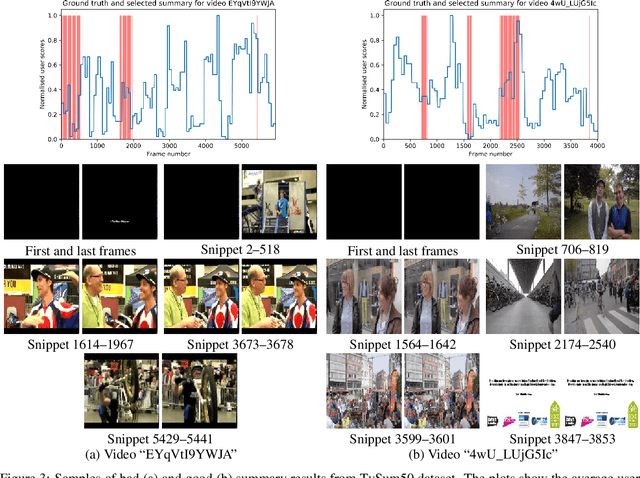
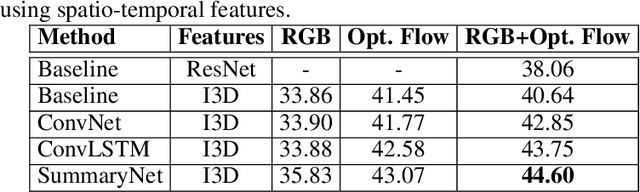
Video summarisation can be posed as the task of extracting important parts of a video in order to create an informative summary of what occurred in the video. In this paper we introduce SummaryNet as a supervised learning framework for automated video summarisation. SummaryNet employs a two-stream convolutional network to learn spatial (appearance) and temporal (motion) representations. It utilizes an encoder-decoder model to extract the most salient features from the learned video representations. Lastly, it uses a sigmoid regression network with bidirectional long short-term memory cells to predict the probability of a frame being a summary frame. Experimental results on benchmark datasets show that the proposed method achieves comparable or significantly better results than the state-of-the-art video summarisation methods.
Human Action Recognition using Local Two-Stream Convolution Neural Network Features and Support Vector Machines
Feb 19, 2020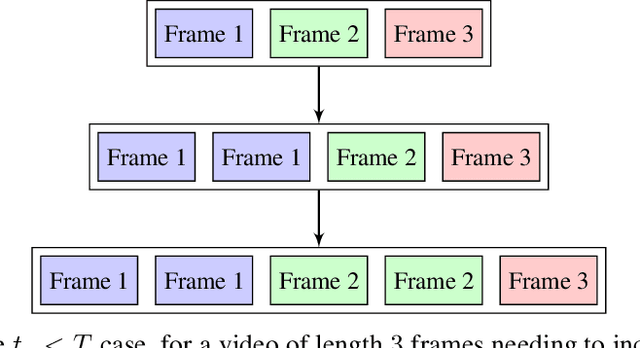
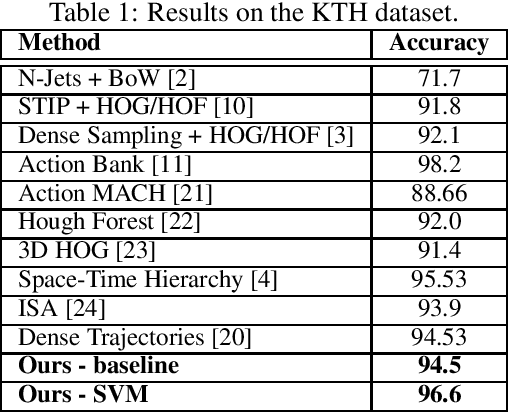

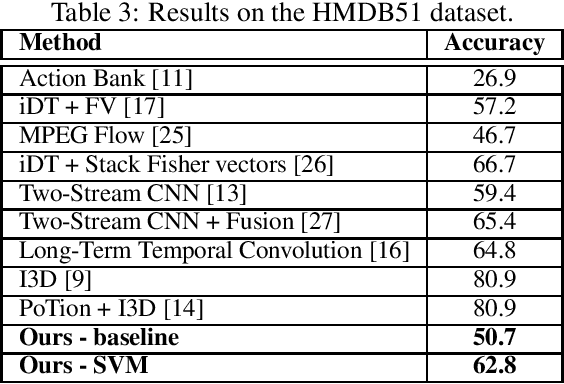
This paper proposes a simple yet effective method for human action recognition in video. The proposed method separately extracts local appearance and motion features using state-of-the-art three-dimensional convolutional neural networks from sampled snippets of a video. These local features are then concatenated to form global representations which are then used to train a linear SVM to perform the action classification using full context of the video, as partial context as used in previous works. The videos undergo two simple proposed preprocessing techniques, optical flow scaling and crop filling. We perform an extensive evaluation on three common benchmark dataset to empirically show the benefit of the SVM, and the two preprocessing steps.