 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Bidirectional Long Short-Term Memory with Subword Embedding for Authorship Attribution
Jun 26, 2023



The problem of unveiling the author of a given text document from multiple candidate authors is called authorship attribution. Manifold word-based stylistic markers have been successfully used in deep learning methods to deal with the intrinsic problem of authorship attribution. Unfortunately, the performance of word-based authorship attribution systems is limited by the vocabulary of the training corpus. Literature has recommended character-based stylistic markers as an alternative to overcome the hidden word problem. However, character-based methods often fail to capture the sequential relationship of words in texts which is a chasm for further improvement. The question addressed in this paper is whether it is possible to address the ambiguity of hidden words in text documents while preserving the sequential context of words. Consequently, a method based on bidirectional long short-term memory (BLSTM) with a 2-dimensional convolutional neural network (CNN) is proposed to capture sequential writing styles for authorship attribution. The BLSTM was used to obtain the sequential relationship among characteristics using subword information. The 2-dimensional CNN was applied to understand the local syntactical position of the style from unlabeled input text. The proposed method was experimentally evaluated against numerous state-of-the-art methods across the public corporal of CCAT50, IMDb62, Blog50, and Twitter50. Experimental results indicate accuracy improvement of 1.07\%, and 0.96\% on CCAT50 and Twitter, respectively, and produce comparable results on the remaining datasets.
Low resource language dataset creation, curation and classification: Setswana and Sepedi -- Extended Abstract
Mar 30, 2020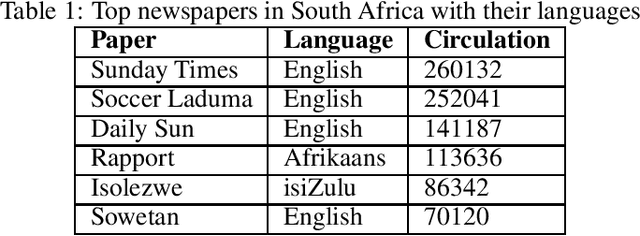
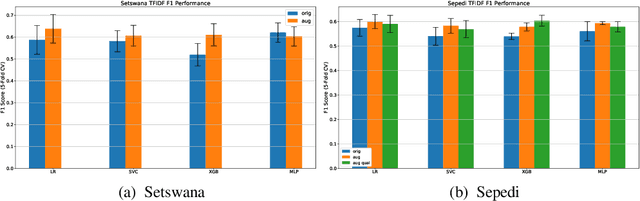
The recent advances in Natural Language Processing have only been a boon for well represented languages, negating research in lesser known global languages. This is in part due to the availability of curated data and research resources. One of the current challenges concerning low-resourced languages are clear guidelines on the collection, curation and preparation of datasets for different use-cases. In this work, we take on the task of creating two datasets that are focused on news headlines (i.e short text) for Setswana and Sepedi and the creation of a news topic classification task from these datasets. In this study, we document our work, propose baselines for classification, and investigate an approach on data augmentation better suited to low-resourced languages in order to improve the performance of the classifiers.
Investigating an approach for low resource language dataset creation, curation and classification: Setswana and Sepedi
Feb 18, 2020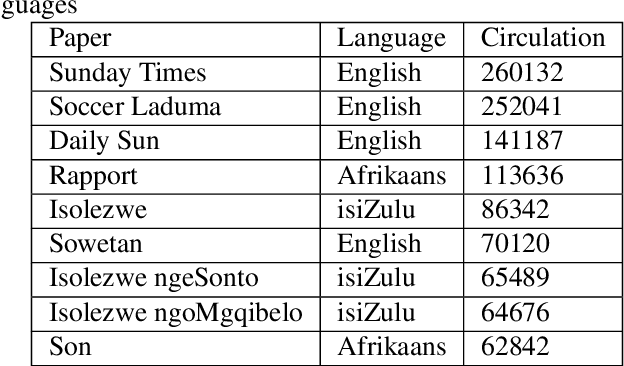



The recent advances in Natural Language Processing have been a boon for well-represented languages in terms of available curated data and research resources. One of the challenges for low-resourced languages is clear guidelines on the collection, curation and preparation of datasets for different use-cases. In this work, we take on the task of creation of two datasets that are focused on news headlines (i.e short text) for Setswana and Sepedi and creation of a news topic classification task. We document our work and also present baselines for classification. We investigate an approach on data augmentation, better suited to low resource languages, to improve the performance of the classifiers