 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Bidirectional Long Short-Term Memory with Subword Embedding for Authorship Attribution
Jun 26, 2023



The problem of unveiling the author of a given text document from multiple candidate authors is called authorship attribution. Manifold word-based stylistic markers have been successfully used in deep learning methods to deal with the intrinsic problem of authorship attribution. Unfortunately, the performance of word-based authorship attribution systems is limited by the vocabulary of the training corpus. Literature has recommended character-based stylistic markers as an alternative to overcome the hidden word problem. However, character-based methods often fail to capture the sequential relationship of words in texts which is a chasm for further improvement. The question addressed in this paper is whether it is possible to address the ambiguity of hidden words in text documents while preserving the sequential context of words. Consequently, a method based on bidirectional long short-term memory (BLSTM) with a 2-dimensional convolutional neural network (CNN) is proposed to capture sequential writing styles for authorship attribution. The BLSTM was used to obtain the sequential relationship among characteristics using subword information. The 2-dimensional CNN was applied to understand the local syntactical position of the style from unlabeled input text. The proposed method was experimentally evaluated against numerous state-of-the-art methods across the public corporal of CCAT50, IMDb62, Blog50, and Twitter50. Experimental results indicate accuracy improvement of 1.07\%, and 0.96\% on CCAT50 and Twitter, respectively, and produce comparable results on the remaining datasets.
Automated Matchmaking to Improve Accuracy of Applicant Selection for University Education System
Jul 09, 2015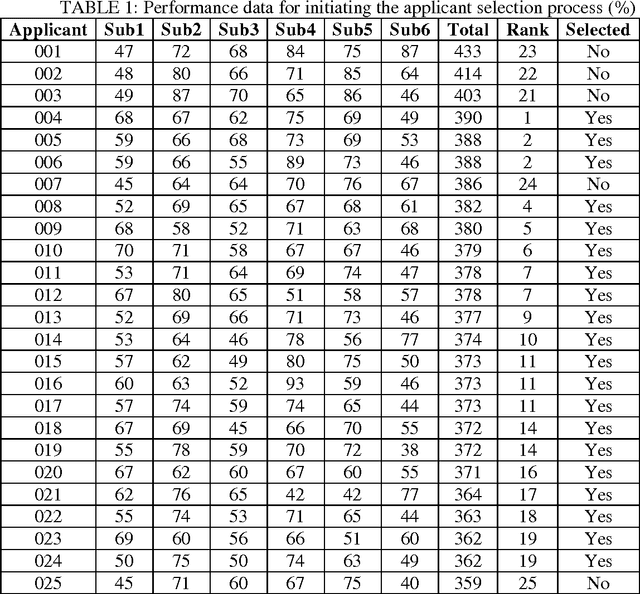
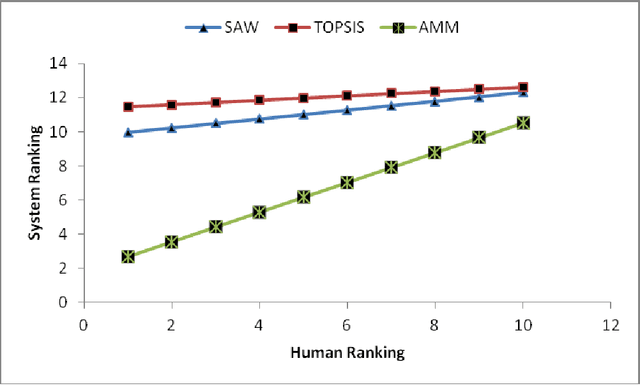
The accurate applicant selection for university education is imperative to ensure fairness and optimal use of institutional resources. Although various approaches are operational in tertiary educational institutions for selecting applicants, a novel method of automated matchmaking is explored in the current study. The method functions by matching a prospective students skills profile to a programmes requisites profile. Empirical comparisons of the results, calculated by automated matchmaking and two other selection methods, show matchmaking to be a viable alternative for accurate selection of applicants. Matchmaking offers a unique advantage that it neither requires data from other applicants nor compares applicants with each other. Instead, it emphasises norms that define admissibility to a programme. We have proposed the use of technology to minimize the gap between students aspirations, skill sets and course requirements. It is a solution to minimize the number of students who get frustrated because of mismatched course selection.
Kernel Density Feature Points Estimator for Content-Based Image Retrieval
Mar 22, 2012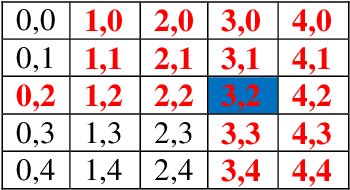

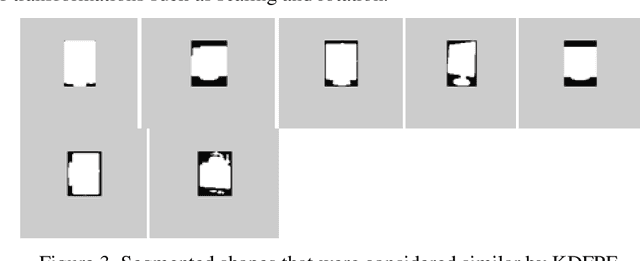

Research is taking place to find effective algorithms for content-based image representation and description. There is a substantial amount of algorithms available that use visual features (color, shape, texture). Shape feature has attracted much attention from researchers that there are many shape representation and description algorithms in literature. These shape image representation and description algorithms are usually not application independent or robust, making them undesirable for generic shape description. This paper presents an object shape representation using Kernel Density Feature Points Estimator (KDFPE). In this method, the density of feature points within defined rings around the centroid of the image is obtained. The KDFPE is then applied to the vector of the image. KDFPE is invariant to translation, scale and rotation. This method of image representation shows improved retrieval rate when compared to Density Histogram Feature Points (DHFP) method. Analytic analysis is done to justify our method, which was compared with the DHFP to prove its robustness.
* ISSN 0975-5578 (Online) 0975-5934 (Print)