 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action Recognition using Local Two-Stream Convolution Neural Network Features and Support Vector Machines
Paper and Code
Feb 19, 2020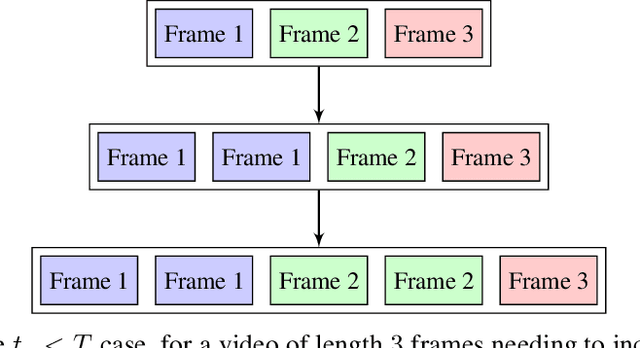
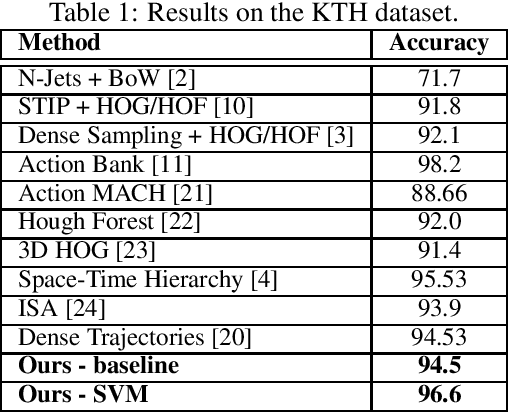

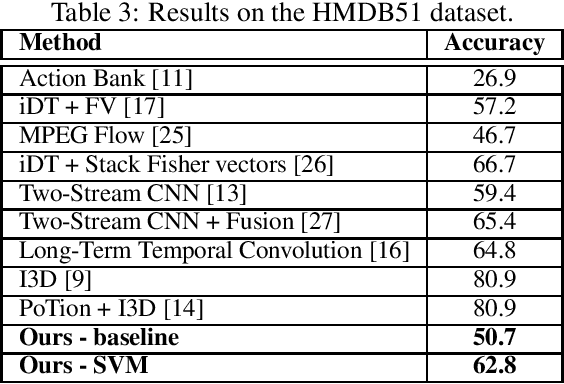
This paper proposes a simple yet effective method for human action recognition in video. The proposed method separately extracts local appearance and motion features using state-of-the-art three-dimensional convolutional neural networks from sampled snippets of a video. These local features are then concatenated to form global representations which are then used to train a linear SVM to perform the action classification using full context of the video, as partial context as used in previous works. The videos undergo two simple proposed preprocessing techniques, optical flow scaling and crop filling. We perform an extensive evaluation on three common benchmark dataset to empirically show the benefit of the SVM, and the two preprocessing steps.