 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummaryNet: A Multi-Stage Deep Learning Model for Automatic Video Summarisation
Feb 19, 2020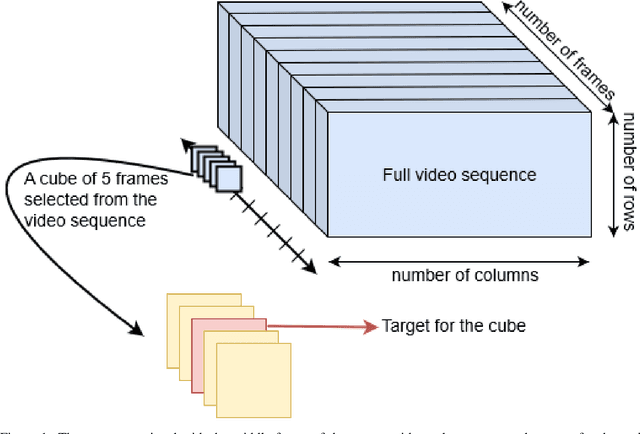
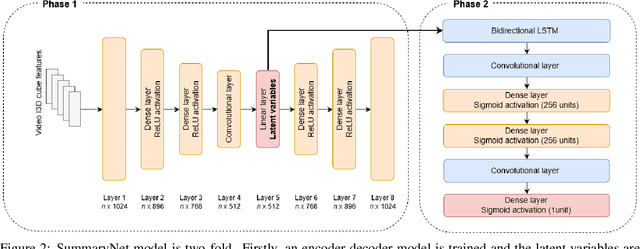
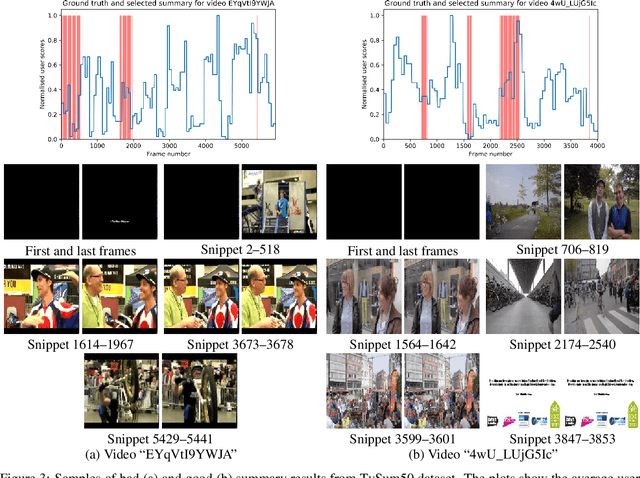
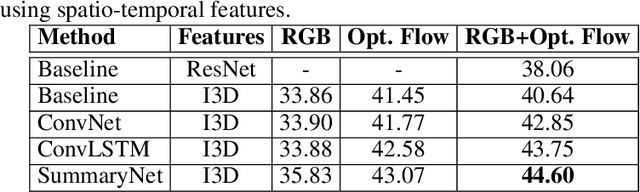
Video summarisation can be posed as the task of extracting important parts of a video in order to create an informative summary of what occurred in the video. In this paper we introduce SummaryNet as a supervised learning framework for automated video summarisation. SummaryNet employs a two-stream convolutional network to learn spatial (appearance) and temporal (motion) representations. It utilizes an encoder-decoder model to extract the most salient features from the learned video representations. Lastly, it uses a sigmoid regression network with bidirectional long short-term memory cells to predict the probability of a frame being a summary frame. Experimental results on benchmark datasets show that the proposed method achieves comparable or significantly better results than the state-of-the-art video summarisation methods.