 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine transformation estimation improves visual self-supervised learning
Paper and Code
Feb 14, 2024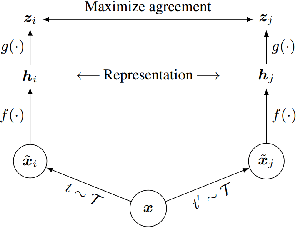
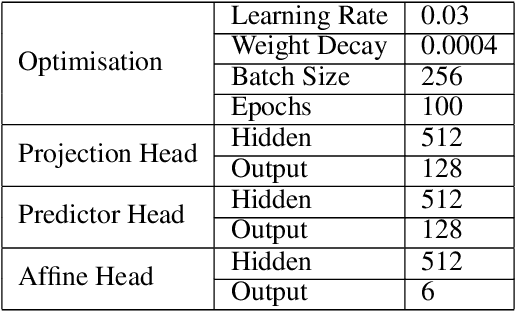
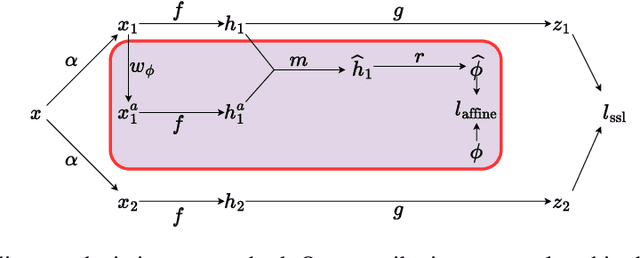
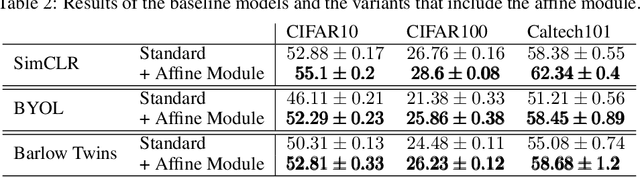
The standard approach to modern self-supervised learning is to generate random views through data augmentations and minimise a loss computed from the representations of these views. This inherently encourages invariance to the transformations that comprise the data augmentation function. In this work, we show that adding a module to constrain the representations to be predictive of an affine transformation improves the performance and efficiency of the learning process. The module is agnostic to the base self-supervised model and manifests in the form of an additional loss term that encourages an aggregation of the encoder representations to be predictive of an affine transformation applied to the input images. We perform experiments in various modern self-supervised models and see a performance improvement in all cases. Further, we perform an ablation study on the components of the affine transformation to understand which of them is affecting performance the most, as well as on key architectural design decisions.