 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Representation Size: High-Dimensional Analysis of Pretraining and Linear Probing
May 19, 2026Learning to generalise from limited data is a fundamental challenge for both artificial and biological systems. A common strategy is to extract reusable structure from abundant unlabelled data, enabling efficient adaptation to new tasks from limited labelled data. This two-stage paradigm is now standard in modern training pipelines, where pretraining is followed by fine-tuning or linear probing. We provide an analytical model of this process: structure extraction is formalized as principal component analysis on unlabelled data, and downstream learning as linear regression on a separate labelled dataset. In the high-dimensional regime, we derive exact expressions for training and generalisation error showcasing their dependence on representation dimensionality, unlabelled and labelled sample sizes, and task alignment. Our results show that pretrained representations strongly influence downstream generalisation, and we characterize the optimal representation size as a function of task parameters: with abundant pretraining data but scarce downstream data, maximally compressed representations are optimal, whereas with limited pretraining data, higher-dimensional representations generalise better. Furthermore, we establish an exact trade-off between pretraining and supervision, quantifying how much unlabelled data is required to replace a single labelled sample. Beyond our idealised model, we observe similar phenomenology in autoencoders and pretrained LLMs. Altogether, we highlight that optimising representation size is critical, giving conditions for when compression during pretraining improves generalisation.
Optimal Learning Rate Schedule for Balancing Effort and Performance
Jan 12, 2026Learning how to learn efficiently is a fundamental challenge for biological agents and a growing concern for artificial ones. To learn effectively, an agent must regulate its learning speed, balancing the benefits of rapid improvement against the costs of effort, instability, or resource use. We introduce a normative framework that formalizes this problem as an optimal control process in which the agent maximizes cumulative performance while incurring a cost of learning. From this objective, we derive a closed-form solution for the optimal learning rate, which has the form of a closed-loop controller that depends only on the agent's current and expected future performance. Under mild assumptions, this solution generalizes across tasks and architectures and reproduces numerically optimized schedules in simulations. In simple learning models, we can mathematically analyze how agent and task parameters shape learning-rate scheduling as an open-loop control solution. Because the optimal policy depends on expectations of future performance, the framework predicts how overconfidence or underconfidence influence engagement and persistence, linking the control of learning speed to theories of self-regulated learning. We further show how a simple episodic memory mechanism can approximate the required performance expectations by recalling similar past learning experiences, providing a biologically plausible route to near-optimal behaviour. Together, these results provide a normative and biologically plausible account of learning speed control, linking self-regulated learning, effort allocation, and episodic memory estimation within a unified and tractable mathematical framework.
Saddle-to-Saddle Dynamics Explains A Simplicity Bias Across Neural Network Architectures
Dec 23, 2025Neural networks trained with gradient descent often learn solutions of increasing complexity over time, a phenomenon known as simplicity bias. Despite being widely observed across architectures, existing theoretical treatments lack a unifying framework. We present a theoretical framework that explains a simplicity bias arising from saddle-to-saddle learning dynamics for a general class of neural networks, incorporating fully-connected, convolutional, and attention-based architectures. Here, simple means expressible with few hidden units, i.e., hidden neurons, convolutional kernels, or attention heads. Specifically, we show that linear networks learn solutions of increasing rank, ReLU networks learn solutions with an increasing number of kinks, convolutional networks learn solutions with an increasing number of convolutional kernels, and self-attention models learn solutions with an increasing number of attention heads. By analyzing fixed points, invariant manifolds, and dynamics of gradient descent learning, we show that saddle-to-saddle dynamics operates by iteratively evolving near an invariant manifold, approaching a saddle, and switching to another invariant manifold. Our analysis also illuminates the effects of data distribution and weight initialization on the duration and number of plateaus in learning, dissociating previously confounding factors. Overall, our theory offers a framework for understanding when and why gradient descent progressively learns increasingly complex solutions.
Revisiting the Role of Relearning in Semantic Dementia
Mar 05, 2025Patients with semantic dementia (SD) present with remarkably consistent atrophy of neurons in the anterior temporal lobe and behavioural impairments, such as graded loss of category knowledge. While relearning of lost knowledge has been shown in acute brain injuries such as stroke, it has not been widely supported in chronic cognitive diseases such as SD. Previous research has shown that deep linear artificial neural networks exhibit stages of semantic learning akin to humans. Here, we use a deep linear network to test the hypothesis that relearning during disease progression rather than particular atrophy cause the specific behavioural patterns associated with SD. After training the network to generate the common semantic features of various hierarchically organised objects, neurons are successively deleted to mimic atrophy while retraining the model. The model with relearning and deleted neurons reproduced errors specific to SD, including prototyping errors and cross-category confusions. This suggests that relearning is necessary for artificial neural networks to reproduce the behavioural patterns associated with SD in the absence of \textit{output} non-linearities. Our results support a theory of SD progression that results from continuous relearning of lost information. Future research should revisit the role of relearning as a contributing factor to cognitive diseases.
Training Dynamics of In-Context Learning in Linear Attention
Jan 27, 2025While attention-based models have demonstrated the remarkable ability of in-context learning, the theoretical understanding of how these models acquired this ability through gradient descent training is still preliminary. Towards answering this question, we study the gradient descent dynamics of multi-head linear self-attention trained for in-context linear regression. We examine two parametrizations of linear self-attention: one with the key and query weights merged as a single matrix (common in theoretical studies), and one with separate key and query matrices (closer to practical settings). For the merged parametrization, we show the training dynamics has two fixed points and the loss trajectory exhibits a single, abrupt drop. We derive an analytical time-course solution for a certain class of datasets and initialization. For the separate parametrization, we show the training dynamics has exponentially many fixed points and the loss exhibits saddle-to-saddle dynamics, which we reduce to scalar ordinary differential equations. During training, the model implements principal component regression in context with the number of principal components increasing over training time. Overall, we characterize how in-context learning abilities evolve during gradient descent training of linear attention, revealing dynamics of abrupt acquisition versus progressive improvements in models with different parametrizations.
Early learning of the optimal constant solution in neural networks and humans
Jun 25, 2024



Deep neural networks learn increasingly complex functions over the course of training. Here, we show both empirically and theoretically that learning of the target function is preceded by an early phase in which networks learn the optimal constant solution (OCS) - that is, initial model responses mirror the distribution of target labels, while entirely ignoring information provided in the input. Using a hierarchical category learning task, we derive exact solutions for learning dynamics in deep linear networks trained with bias terms. Even when initialized to zero, this simple architectural feature induces substantial changes in early dynamics. We identify hallmarks of this early OCS phase and illustrate how these signatures are observed in deep linear networks and larger, more complex (and nonlinear) convolutional neural networks solving a hierarchical learning task based on MNIST and CIFAR10. We explain these observations by proving that deep linear networks necessarily learn the OCS during early learning. To further probe the generality of our results, we train human learners over the course of three days on the category learning task. We then identify qualitative signatures of this early OCS phase in terms of the dynamics of true negative (correct-rejection) rates. Surprisingly, we find the same early reliance on the OCS in the behaviour of human learners. Finally, we show that learning of the OCS can emerge even in the absence of bias terms and is equivalently driven by generic correlations in the input data. Overall, our work suggests the OCS as a universal learning principle in supervised, error-corrective learning, and the mechanistic reasons for its prevalence.
When Are Bias-Free ReLU Networks Like Linear Networks?
Jun 18, 2024We investigate the expressivity and learning dynamics of bias-free ReLU networks. We firstly show that two-layer bias-free ReLU networks have limited expressivity: the only odd function two-layer bias-free ReLU networks can express is a linear one. We then show that, under symmetry conditions on the data, these networks have the same learning dynamics as linear networks. This allows us to give closed-form time-course solutions to certain two-layer bias-free ReLU networks, which has not been done for nonlinear networks outside the lazy learning regime. While deep bias-free ReLU networks are more expressive than their two-layer counterparts, they still share a number of similarities with deep linear networks. These similarities enable us to leverage insights from linear networks, leading to a novel understanding of bias-free ReLU networks. Overall, our results show that some properties established for bias-free ReLU networks arise due to equivalence to linear networks, and suggest that including bias or considering asymmetric data are avenues to engage with nonlinear behaviors.
Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning
Jun 10, 2024



While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this rich feature learning regime remain elusive, with much of our theoretical understanding stemming from the opposing lazy regime. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced layer-specific initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs with balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of learning hierarchical data, and decreases the time to grokking in modular arithmetic. Our theory motivates further exploration of unbalanced initializations to enhance efficient feature learning.
Tilting the Odds at the Lottery: the Interplay of Overparameterisation and Curricula in Neural Networks
Jun 03, 2024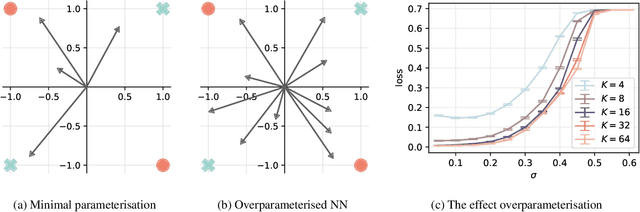
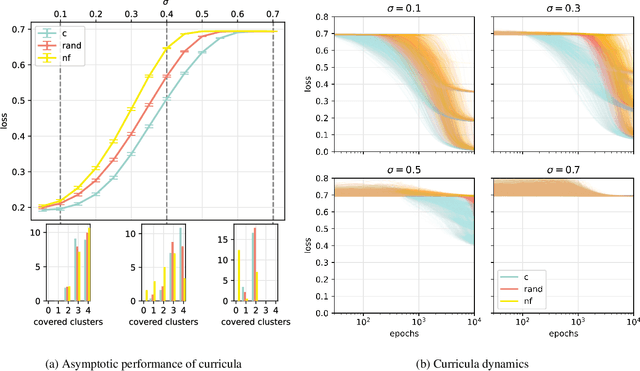
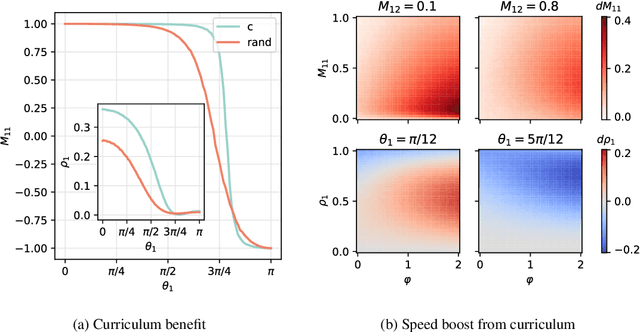
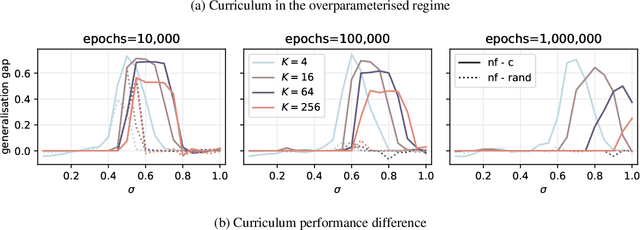
A wide range of empirical and theoretical works have shown that overparameterisation can amplify the performance of neural networks. According to the lottery ticket hypothesis, overparameterised networks have an increased chance of containing a sub-network that is well-initialised to solve the task at hand. A more parsimonious approach, inspired by animal learning, consists in guiding the learner towards solving the task by curating the order of the examples, i.e. providing a curriculum. However, this learning strategy seems to be hardly beneficial in deep learning applications. In this work, we undertake an analytical study that connects curriculum learning and overparameterisation. In particular, we investigate their interplay in the online learning setting for a 2-layer network in the XOR-like Gaussian Mixture problem. Our results show that a high degree of overparameterisation -- while simplifying the problem -- can limit the benefit from curricula, providing a theoretical account of the ineffectiveness of curricula in deep learning.
A Theory of Unimodal Bias in Multimodal Learning
Dec 01, 2023Using multiple input streams simultaneously in training multimodal neural networks is intuitively advantageous, but practically challenging. A key challenge is unimodal bias, where a network overly relies on one modality and ignores others during joint training. While unimodal bias is well-documented empirically, our theoretical understanding of how architecture and data statistics influence this bias remains incomplete. Here we develop a theory of unimodal bias with deep multimodal linear networks. We calculate the duration of the unimodal phase in learning as a function of the depth at which modalities are fused within the network, dataset statistics, and initialization. We find that the deeper the layer at which fusion occurs, the longer the unimodal phase. A long unimodal phase can lead to a generalization deficit and permanent unimodal bias in the overparametrized regime. In addition, our theory reveals the modality learned first is not necessarily the modality that contributes more to the output. Our results, derived for multimodal linear networks, extend to ReLU networks in certain settings. Taken together, this work illuminates pathologies of multimodal learning under joint training, showing that late and intermediate fusion architectures can give rise to long unimodal phases and permanent unimodal bias.