 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Haste Slowly: A Theory of Emergent Structured Mixed Selectivity in Feature Learning ReLU Networks
Mar 08, 2025In spite of finite dimension ReLU neural networks being a consistent factor behind recent deep learning successes, a theory of feature learning in these models remains elusive. Currently, insightful theories still rely on assumptions including the linearity of the network computations, unstructured input data and architectural constraints such as infinite width or a single hidden layer. To begin to address this gap we establish an equivalence between ReLU networks and Gated Deep Linear Networks, and use their greater tractability to derive dynamics of learning. We then consider multiple variants of a core task reminiscent of multi-task learning or contextual control which requires both feature learning and nonlinearity. We make explicit that, for these tasks, the ReLU networks possess an inductive bias towards latent representations which are not strictly modular or disentangled but are still highly structured and reusable between contexts. This effect is amplified with the addition of more contexts and hidden layers. Thus, we take a step towards a theory of feature learning in finite ReLU networks and shed light on how structured mixed-selective latent representations can emerge due to a bias for node-reuse and learning speed.
Revisiting the Role of Relearning in Semantic Dementia
Mar 05, 2025Patients with semantic dementia (SD) present with remarkably consistent atrophy of neurons in the anterior temporal lobe and behavioural impairments, such as graded loss of category knowledge. While relearning of lost knowledge has been shown in acute brain injuries such as stroke, it has not been widely supported in chronic cognitive diseases such as SD. Previous research has shown that deep linear artificial neural networks exhibit stages of semantic learning akin to humans. Here, we use a deep linear network to test the hypothesis that relearning during disease progression rather than particular atrophy cause the specific behavioural patterns associated with SD. After training the network to generate the common semantic features of various hierarchically organised objects, neurons are successively deleted to mimic atrophy while retraining the model. The model with relearning and deleted neurons reproduced errors specific to SD, including prototyping errors and cross-category confusions. This suggests that relearning is necessary for artificial neural networks to reproduce the behavioural patterns associated with SD in the absence of \textit{output} non-linearities. Our results support a theory of SD progression that results from continuous relearning of lost information. Future research should revisit the role of relearning as a contributing factor to cognitive diseases.
A Theory of Initialisation's Impact on Specialisation
Mar 04, 2025



Prior work has demonstrated a consistent tendency in neural networks engaged in continual learning tasks, wherein intermediate task similarity results in the highest levels of catastrophic interference. This phenomenon is attributed to the network's tendency to reuse learned features across tasks. However, this explanation heavily relies on the premise that neuron specialisation occurs, i.e. the emergence of localised representations. Our investigation challenges the validity of this assumption. Using theoretical frameworks for the analysis of neural networks, we show a strong dependence of specialisation on the initial condition. More precisely, we show that weight imbalance and high weight entropy can favour specialised solutions. We then apply these insights in the context of continual learning, first showing the emergence of a monotonic relation between task-similarity and forgetting in non-specialised networks. {Finally, we show that specialization by weight imbalance is beneficial on the commonly employed elastic weight consolidation regularisation technique.
Investigating the Impact of Language-Adaptive Fine-Tuning on Sentiment Analysis in Hausa Language Using AfriBERTa
Jan 19, 2025



Sentiment analysis (SA) plays a vital role in Natural Language Processing (NLP) by ~identifying sentiments expressed in text. Although significant advances have been made in SA for widely spoken languages, low-resource languages such as Hausa face unique challenges, primarily due to a lack of digital resources. This study investigates the effectiveness of Language-Adaptive Fine-Tuning (LAFT) to improve SA performance in Hausa. We first curate a diverse, unlabeled corpus to expand the model's linguistic capabilities, followed by applying LAFT to adapt AfriBERTa specifically to the nuances of the Hausa language. The adapted model is then fine-tuned on the labeled NaijaSenti sentiment dataset to evaluate its performance. Our findings demonstrate that LAFT gives modest improvements, which may be attributed to the use of formal Hausa text rather than informal social media data. Nevertheless, the pre-trained AfriBERTa model significantly outperformed models not specifically trained on Hausa, highlighting the importance of using pre-trained models in low-resource contexts. This research emphasizes the necessity for diverse data sources to advance NLP applications for low-resource African languages. We published the code and the dataset to encourage further research and facilitate reproducibility in low-resource NLP here: https://github.com/Sani-Abdullahi-Sani/Natural-Language-Processing/blob/main/Sentiment%20Analysis%20for%20Low%20Resource%20African%20Languages
Dynamics Generalisation in Reinforcement Learning via Adaptive Context-Aware Policies
Oct 25, 2023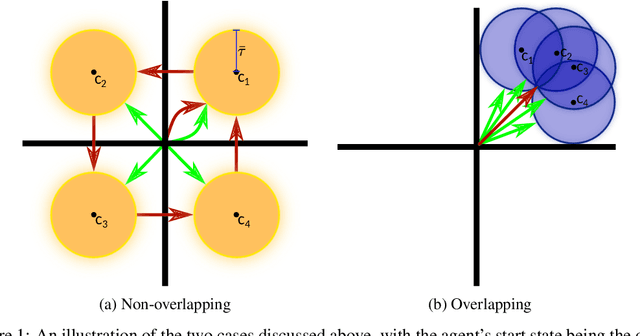
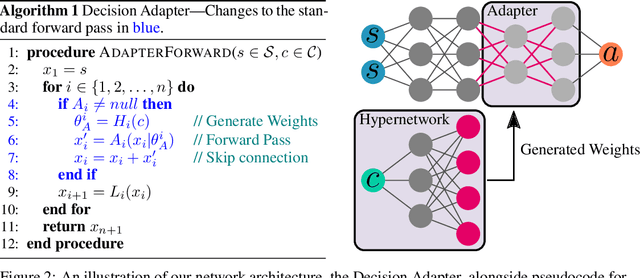
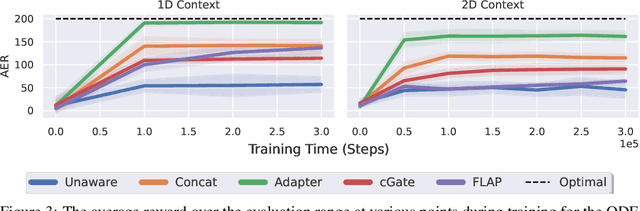
While reinforcement learning has achieved remarkable successes in several domains, its real-world application is limited due to many methods failing to generalise to unfamiliar conditions. In this work, we consider the problem of generalising to new transition dynamics, corresponding to cases in which the environment's response to the agent's actions differs. For example, the gravitational force exerted on a robot depends on its mass and changes the robot's mobility. Consequently, in such cases, it is necessary to condition an agent's actions on extrinsic state information and pertinent contextual information reflecting how the environment responds. While the need for context-sensitive policies has been established, the manner in which context is incorporated architecturally has received less attention. Thus, in this work, we present an investigation into how context information should be incorporated into behaviour learning to improve generalisation. To this end, we introduce a neural network architecture, the Decision Adapter, which generates the weights of an adapter module and conditions the behaviour of an agent on the context information. We show that the Decision Adapter is a useful generalisation of a previously proposed architecture and empirically demonstrate that it results in superior generalisation performance compared to previous approaches in several environments. Beyond this, the Decision Adapter is more robust to irrelevant distractor variables than several alternative methods.
Skill Machines: Temporal Logic Composition in Reinforcement Learning
May 25, 2022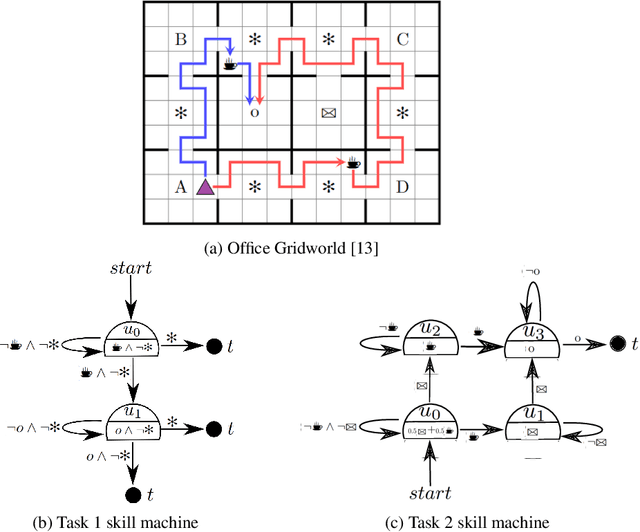

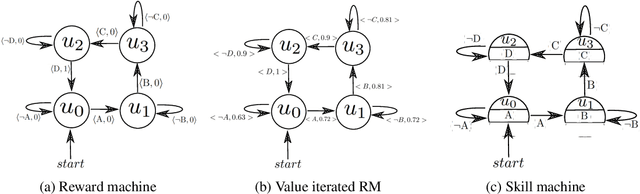

A major challenge in reinforcement learning is specifying tasks in a manner that is both interpretable and verifiable. One common approach is to specify tasks through reward machines -- finite state machines that encode the task to be solved. We introduce skill machines, a representation that can be learned directly from these reward machines that encode the solution to such tasks. We propose a framework where an agent first learns a set of base skills in a reward-free setting, and then combines these skills with the learned skill machine to produce composite behaviours specified by any regular language, such as linear temporal logics. This provides the agent with the ability to map from complex logical task specifications to near-optimal behaviours zero-shot. We demonstrate our approach in both a tabular and high-dimensional video game environment, where an agent is faced with several of these complex, long-horizon tasks. Our results indicate that the agent is capable of satisfying extremely complex task specifications, producing near optimal performance with no further learning. Finally, we demonstrate that the performance of skill machines can be improved with regular offline reinforcement learning algorithms when optimal behaviours are desired.
Accounting for the Sequential Nature of States to Learn Features for Reinforcement Learning
May 12, 2022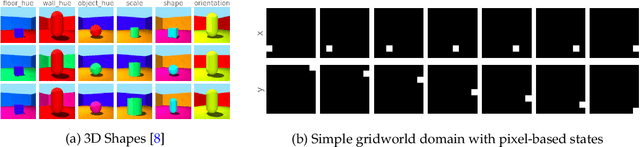
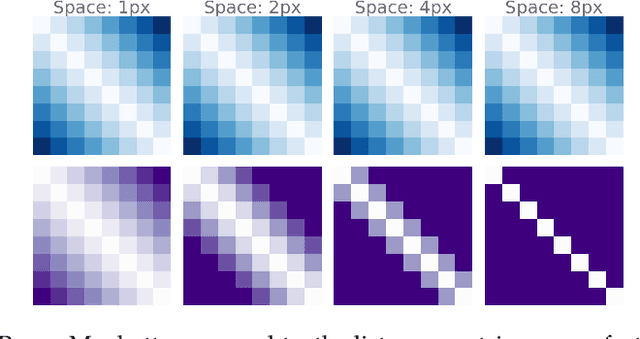
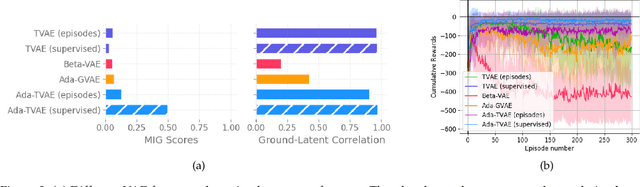
In this work, we investigate the properties of data that cause popular representation learning approaches to fail. In particular, we find that in environments where states do not significantly overlap, variational autoencoders (VAEs) fail to learn useful features. We demonstrate this failure in a simple gridworld domain, and then provide a solution in the form of metric learning. However, metric learning requires supervision in the form of a distance function, which is absent in reinforcement learning. To overcome this, we leverage the sequential nature of states in a replay buffer to approximate a distance metric and provide a weak supervision signal, under the assumption that temporally close states are also semantically similar. We modify a VAE with triplet loss and demonstrate that this approach is able to learn useful features for downstream tasks, without additional supervision, in environments where standard VAEs fail.