 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Induced Representational Invariances Depend on Learning Objective in Deep RL
Jun 01, 2026Reinforcement Learning (RL) has long served as a model for goal-directed animal behavior in neuroscience. Modern deep RL has shown remarkable success across many domains, further strengthening this connection. The ability to learn abstract representations of high-dimensional state spaces underlies much of this success. However, theoretical understanding of these learned representations remains limited, hindering direct comparisons between models and animal learning. We address this gap by analyzing deep RL representations through the lens of MDP reduction theory. Investigating canonical RL algorithms in a navigation task, we find that even when performance is comparable, the value-based method (DQN) learns representations that are invariant to MDP homomorphism symmetries, while the policy-gradient method (PPO) learns representations invariant to action symmetries. These differences emerge consistently across domains, have downstream consequences for transfer learning, and appear in LLMs in a prompt-dependent manner. Our findings provide a principled approach to comparing learned representations across RL algorithms, with demonstrated practical implications and possible insights for neural coding in the brain.
Uncertainty Prioritized Experience Replay
Jun 10, 2025



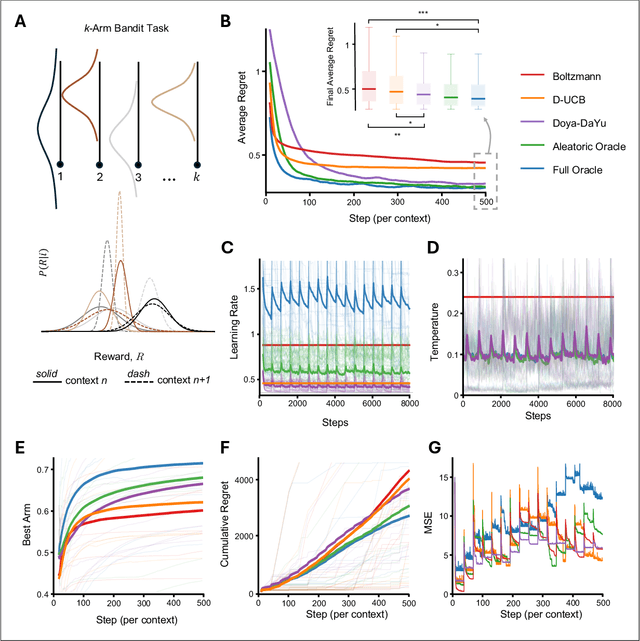
Prioritized experience replay, which improves sample efficiency by selecting relevant transitions to update parameter estimates, is a crucial component of contemporary value-based deep reinforcement learning models. Typically, transitions are prioritized based on their temporal difference error. However, this approach is prone to favoring noisy transitions, even when the value estimation closely approximates the target mean. This phenomenon resembles the noisy TV problem postulated in the exploration literature, in which exploration-guided agents get stuck by mistaking noise for novelty. To mitigate the disruptive effects of noise in value estimation, we propose using epistemic uncertainty estimation to guide the prioritization of transitions from the replay buffer. Epistemic uncertainty quantifies the uncertainty that can be reduced by learning, hence reducing transitions sampled from the buffer generated by unpredictable random processes. We first illustrate the benefits of epistemic uncertainty prioritized replay in two tabular toy models: a simple multi-arm bandit task, and a noisy gridworld. Subsequently, we evaluate our prioritization scheme on the Atari suite, outperforming quantile regression deep Q-learning benchmarks; thus forging a path for the use of uncertainty prioritized replay in reinforcement learning agents.
A Theory of Initialisation's Impact on Specialisation
Mar 04, 2025



Prior work has demonstrated a consistent tendency in neural networks engaged in continual learning tasks, wherein intermediate task similarity results in the highest levels of catastrophic interference. This phenomenon is attributed to the network's tendency to reuse learned features across tasks. However, this explanation heavily relies on the premise that neuron specialisation occurs, i.e. the emergence of localised representations. Our investigation challenges the validity of this assumption. Using theoretical frameworks for the analysis of neural networks, we show a strong dependence of specialisation on the initial condition. More precisely, we show that weight imbalance and high weight entropy can favour specialised solutions. We then apply these insights in the context of continual learning, first showing the emergence of a monotonic relation between task-similarity and forgetting in non-specialised networks. {Finally, we show that specialization by weight imbalance is beneficial on the commonly employed elastic weight consolidation regularisation technique.
Lifelong Reinforcement Learning via Neuromodulation
Aug 15, 2024


Navigating multiple tasks$\unicode{x2014}$for instance in succession as in continual or lifelong learning, or in distributions as in meta or multi-task learning$\unicode{x2014}$requires some notion of adaptation. Evolution over timescales of millennia has imbued humans and other animals with highly effective adaptive learning and decision-making strategies. Central to these functions are so-called neuromodulatory systems. In this work we introduce an abstract framework for integrating theories and evidence from neuroscience and the cognitive sciences into the design of adaptive artificial reinforcement learning algorithms. We give a concrete instance of this framework built on literature surrounding the neuromodulators Acetylcholine (ACh) and Noradrenaline (NA), and empirically validate the effectiveness of the resulting adaptive algorithm in a non-stationary multi-armed bandit problem. We conclude with a theory-based experiment proposal providing an avenue to link our framework back to efforts in experimental neuroscience.
The RL Perceptron: Generalisation Dynamics of Policy Learning in High Dimensions
Jun 27, 2023



Reinforcement learning (RL) algorithms have proven transformative in a range of domains. To tackle real-world domains, these systems often use neural networks to learn policies directly from pixels or other high-dimensional sensory input. By contrast, much theory of RL has focused on discrete state spaces or worst-case analysis, and fundamental questions remain about the dynamics of policy learning in high-dimensional settings. Here, we propose a solvable high-dimensional model of RL that can capture a variety of learning protocols, and derive its typical dynamics as a set of closed-form ordinary differential equations (ODEs). We derive optimal schedules for the learning rates and task difficulty - analogous to annealing schemes and curricula during training in RL - and show that the model exhibits rich behaviour, including delayed learning under sparse rewards; a variety of learning regimes depending on reward baselines; and a speed-accuracy trade-off driven by reward stringency. Experiments on variants of the Procgen game "Bossfight" and Arcade Learning Environment game "Pong" also show such a speed-accuracy trade-off in practice. Together, these results take a step towards closing the gap between theory and practice in high-dimensional RL.
Maslow's Hammer for Catastrophic Forgetting: Node Re-Use vs Node Activation
May 18, 2022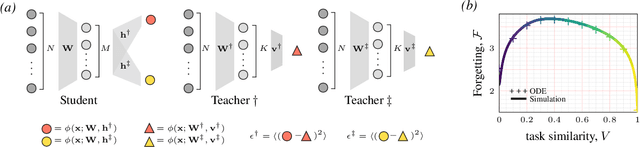
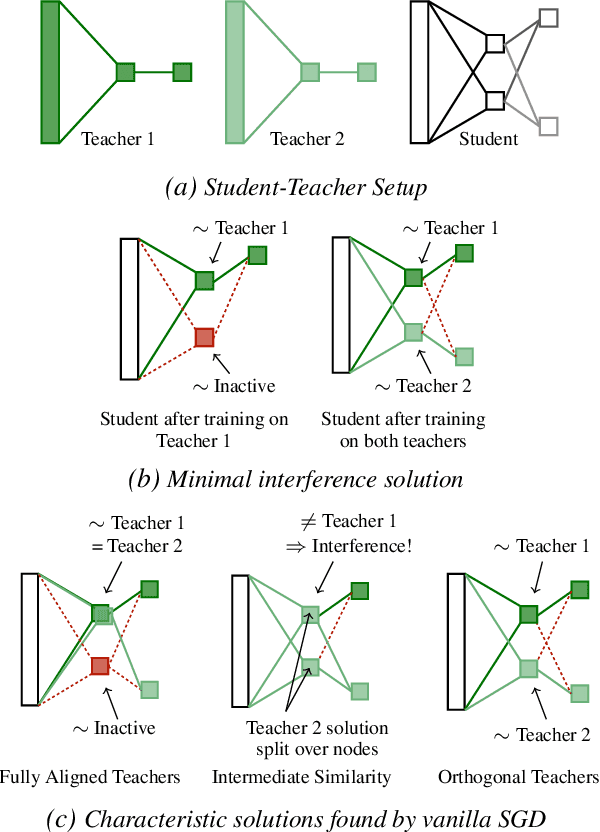
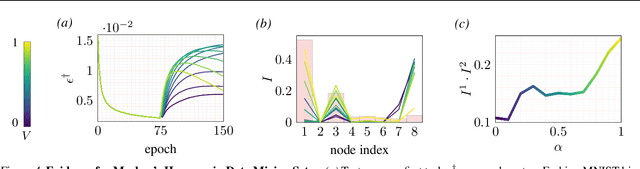
Continual learning - learning new tasks in sequence while maintaining performance on old tasks - remains particularly challenging for artificial neural networks. Surprisingly, the amount of forgetting does not increase with the dissimilarity between the learned tasks, but appears to be worst in an intermediate similarity regime. In this paper we theoretically analyse both a synthetic teacher-student framework and a real data setup to provide an explanation of this phenomenon that we name Maslow's hammer hypothesis. Our analysis reveals the presence of a trade-off between node activation and node re-use that results in worst forgetting in the intermediate regime. Using this understanding we reinterpret popular algorithmic interventions for catastrophic interference in terms of this trade-off, and identify the regimes in which they are most effective.
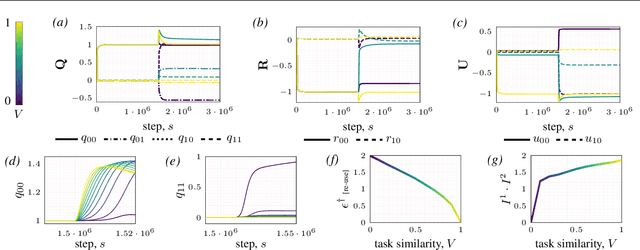
Continual Learning in the Teacher-Student Setup: Impact of Task Similarity
Jul 09, 2021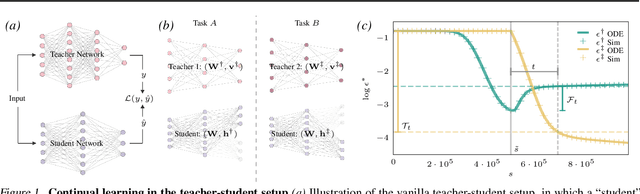
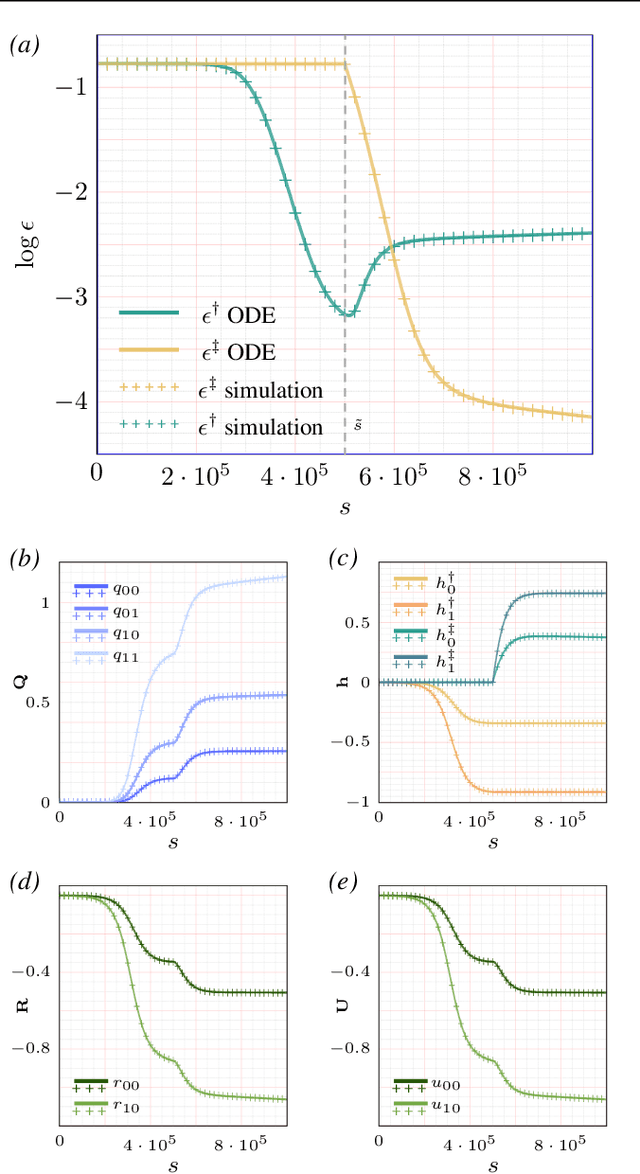
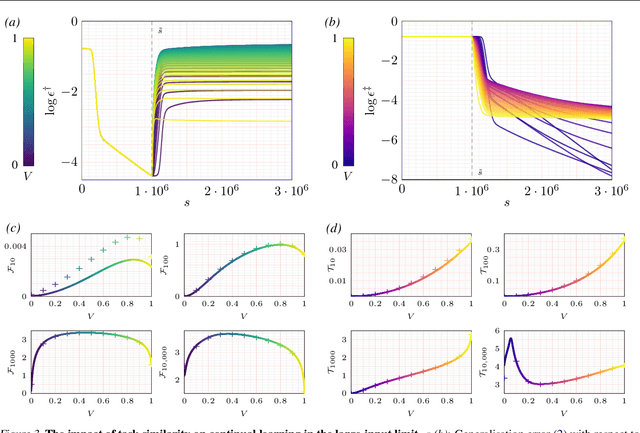
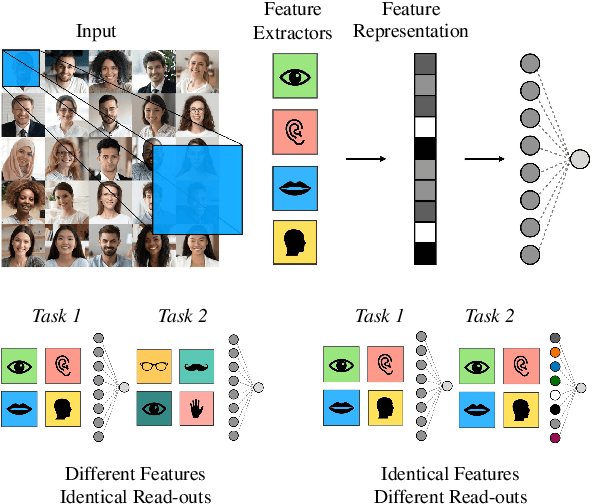
Continual learning-the ability to learn many tasks in sequence-is critical for artificial learning systems. Yet standard training methods for deep networks often suffer from catastrophic forgetting, where learning new tasks erases knowledge of earlier tasks. While catastrophic forgetting labels the problem, the theoretical reasons for interference between tasks remain unclear. Here, we attempt to narrow this gap between theory and practice by studying continual learning in the teacher-student setup. We extend previous analytical work on two-layer networks in the teacher-student setup to multiple teachers. Using each teacher to represent a different task, we investigate how the relationship between teachers affects the amount of forgetting and transfer exhibited by the student when the task switches. In line with recent work, we find that when tasks depend on similar features, intermediate task similarity leads to greatest forgetting. However, feature similarity is only one way in which tasks may be related. The teacher-student approach allows us to disentangle task similarity at the level of readouts (hidden-to-output weights) and features (input-to-hidden weights). We find a complex interplay between both types of similarity, initial transfer/forgetting rates, maximum transfer/forgetting, and long-term transfer/forgetting. Together, these results help illuminate the diverse factors contributing to catastrophic forgetting.
Fast and Memory-Efficient Neural Code Completion
Apr 29, 2020


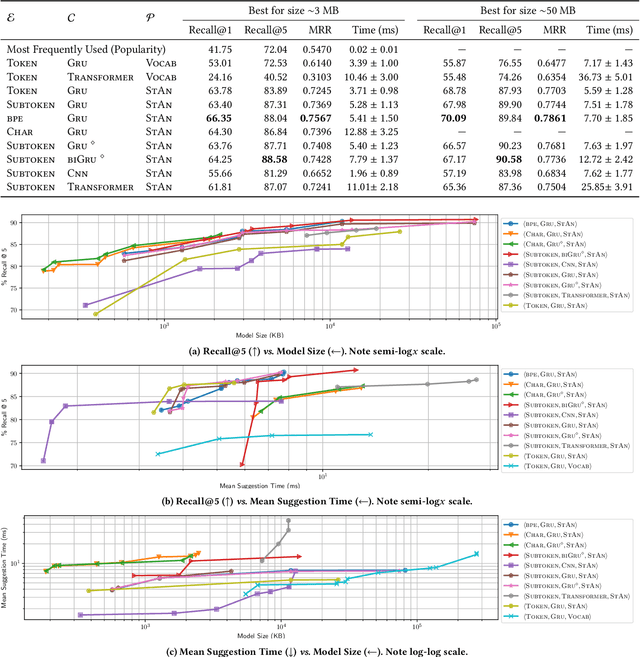
Code completion is one of the most widely used features of modern integrated development environments (IDEs). Deep learning has recently made significant progress in the statistical prediction of source code. However, state-of-the-art neural network models consume prohibitively large amounts of memory, causing computational burden to the development environment, especially when deployed in lightweight client devices. In this work, we reframe neural code completion from a generation task to a task of learning to rank the valid completion suggestions computed from static analyses. By doing so, we are able to design and test a variety of deep neural network model configurations. One of our best models consumes 6 MB of RAM, computes a single suggestion in 8 ms, and achieves 90% recall in its top five suggestions. Our models outperform standard language modeling code completion techniques in terms of predictive performance, computational speed, and memory efficiency. Furthermore, they learn about code semantics from the natural language aspects of the code (e.g. identifier names) and can generalize better to previously unseen code.