 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorisation, convergence and generalisation in generative models
May 20, 2026Generative neural networks learn how to produce highly realistic images from a large, but finite number of examples - or do they simply memorise their training set? To settle this question, Kadkhodaie, Guth, Simoncelli and Mallat (ICLR '24) trained diffusion models independently on disjoint subsets of a dataset and showed that they converge to nearly the same density when the number of training images is large enough. This result raises two basic questions: how much data do you need for convergence, and what does convergence capture about learning the data distribution? Here, we address these questions by providing an exact analytical characterisation of the transition from memorisation to generalisation in linear generative models. We find that these models memorise at small load, while convergence emerges continuously when the number of samples is linear in the input dimension. Strikingly, we find that convergence is insensitive to recovery of the principal latent factors of the data, which are recovered in a sharp transition. After extending our approach to data with power-law spectra, we find the same distinction between convergence and latent recovery in our experiments with convolutional denoisers and in the data of Kadkhodaie et al. We thus show that generalisation in generative models decomposes into at least two distinct objectives: matching the bulk of the data distribution and recovering the principal latent factors. These objectives correspond to two different distances between true and learnt data distribution, and only the first one is captured by convergence.
Factual recall in linear associative memories: sharp asymptotics and mechanistic insights
May 11, 2026Large language models demonstrate remarkable ability in factual recall, yet the fundamental limits of storing and retrieving input--output associations with neural networks remain unclear. We study these limits in a minimal setting: a linear associative memory that maps $p$ input embeddings in $\mathbb{R}^d$ to their corresponding~$d$-dimensional targets via a single layer, requiring each mapped input to be well separated from all other targets. Unlike in supervised classification, this strict separation induces~$p$ constraints per association and produces strong correlations between constraints that make a direct characterisation of the storage capacity difficult. Here, we provide a precise characterisation of this capacity in the following way. We first introduce a decoupled model in which each input has its own independent set of competing outputs, and provide numerical and analytical evidence that this decoupled model is equivalent to the original model in terms of storage capacity, spectra of the learnt weights, and storage mechanism. Using tools from statistical physics, we show that the decoupled model can store up to $p_c \log p_c / d^2 = 1 / 2$ associations, and generalise the computation of $p_c$ to linear two-layer architectures. Our analysis also gives mechanistic insight into how the optimal solution improves over a naïve Hebbian learning rule: rather than boosting input-output alignments with broad fluctuations, the optimal solution raises the correct scores just above the extreme-value threshold set by the competing outputs. These findings give a sharp statistical-physics characterisation of factual storage in linear networks and provide a baseline for understanding the memory capacity of more realistic neural architectures.
A theory of learning data statistics in diffusion models, from easy to hard
Mar 13, 2026While diffusion models have emerged as a powerful class of generative models, their learning dynamics remain poorly understood. We address this issue first by empirically showing that standard diffusion models trained on natural images exhibit a distributional simplicity bias, learning simple, pair-wise input statistics before specializing to higher-order correlations. We reproduce this behaviour in simple denoisers trained on a minimal data model, the mixed cumulant model, where we precisely control both pair-wise and higher-order correlations of the inputs. We identify a scalar invariant of the model that governs the sample complexity of learning pair-wise and higher-order correlations that we call the diffusion information exponent, in analogy to related invariants in different learning paradigms. Using this invariant, we prove that the denoiser learns simple, pair-wise statistics of the inputs at linear sample complexity, while more complex higher-order statistics, such as the fourth cumulant, require at least cubic sample complexity. We also prove that the sample complexity of learning the fourth cumulant is linear if pair-wise and higher-order statistics share a correlated latent structure. Our work describes a key mechanism for how diffusion models can learn distributions of increasing complexity.
Two failure modes of deep transformers and how to avoid them: a unified theory of signal propagation at initialisation
May 30, 2025Finding the right initialisation for neural networks is crucial to ensure smooth training and good performance. In transformers, the wrong initialisation can lead to one of two failure modes of self-attention layers: rank collapse, where all tokens collapse into similar representations, and entropy collapse, where highly concentrated attention scores lead to training instability. While the right initialisation has been extensively studied in feed-forward networks, an exact description of signal propagation through a full transformer block has so far been lacking. Here, we provide an analytical theory of signal propagation through vanilla transformer blocks with self-attention layers, layer normalisation, skip connections and ReLU MLP. To treat the self-attention layer, we draw on a formal parallel with the Random Energy Model from statistical physics. We identify and characterise two regimes governed by the variance of the query and key initialisations: a low-variance regime, where we recover the known rank collapse behaviour; and a previously unexplored high-variance regime, where signal is preserved but \textit{entropy collapse} occurs. In the low-variance regime, we calculate the critical strength for the residual connection to ensure signal propagation. Our theory yields trainability diagrams that identify the correct choice of initialisation hyper-parameters for a given architecture. Experiments with BERT-style models trained on TinyStories validate our predictions. Our theoretical framework gives a unified perspective on the two failure modes of self-attention and gives quantitative predictions on the scale of both weights and residual connections that guarantees smooth training.
Generalization Dynamics of Linear Diffusion Models
May 30, 2025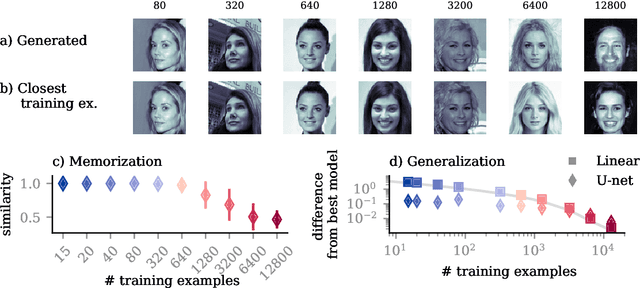
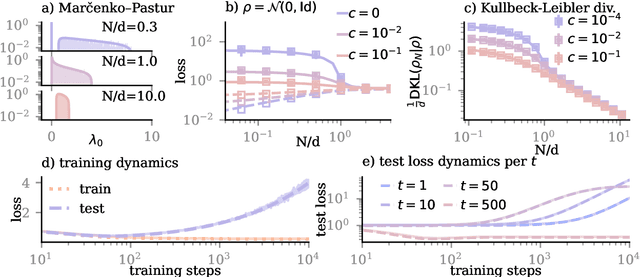
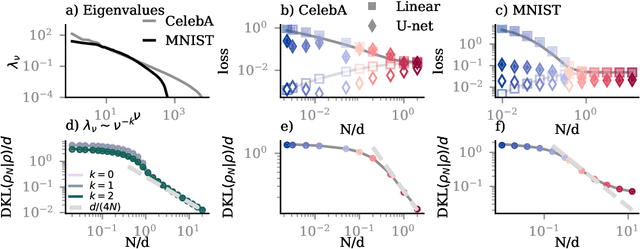
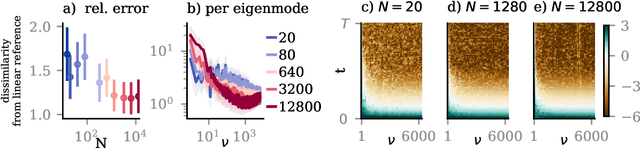
Diffusion models trained on finite datasets with $N$ samples from a target distribution exhibit a transition from memorisation, where the model reproduces training examples, to generalisation, where it produces novel samples that reflect the underlying data distribution. Understanding this transition is key to characterising the sample efficiency and reliability of generative models, but our theoretical understanding of this transition is incomplete. Here, we analytically study the memorisation-to-generalisation transition in a simple model using linear denoisers, which allow explicit computation of test errors, sampling distributions, and Kullback-Leibler divergences between samples and target distribution. Using these measures, we predict that this transition occurs roughly when $N \asymp d$, the dimension of the inputs. When $N$ is smaller than the dimension of the inputs $d$, so that only a fraction of relevant directions of variation are present in the training data, we demonstrate how both regularization and early stopping help to prevent overfitting. For $N > d$, we find that the sampling distributions of linear diffusion models approach their optimum (measured by the Kullback-Leibler divergence) linearly with $d/N$, independent of the specifics of the data distribution. Our work clarifies how sample complexity governs generalisation in a simple model of diffusion-based generative models and provides insight into the training dynamics of linear denoisers.
Feature learning from non-Gaussian inputs: the case of Independent Component Analysis in high dimensions
Mar 31, 2025



Deep neural networks learn structured features from complex, non-Gaussian inputs, but the mechanisms behind this process remain poorly understood. Our work is motivated by the observation that the first-layer filters learnt by deep convolutional neural networks from natural images resemble those learnt by independent component analysis (ICA), a simple unsupervised method that seeks the most non-Gaussian projections of its inputs. This similarity suggests that ICA provides a simple, yet principled model for studying feature learning. Here, we leverage this connection to investigate the interplay between data structure and optimisation in feature learning for the most popular ICA algorithm, FastICA, and stochastic gradient descent (SGD), which is used to train deep networks. We rigorously establish that FastICA requires at least $n\gtrsim d^4$ samples to recover a single non-Gaussian direction from $d$-dimensional inputs on a simple synthetic data model. We show that vanilla online SGD outperforms FastICA, and prove that the optimal sample complexity $n \gtrsim d^2$ can be reached by smoothing the loss, albeit in a data-dependent way. We finally demonstrate the existence of a search phase for FastICA on ImageNet, and discuss how the strong non-Gaussianity of said images compensates for the poor sample complexity of FastICA.
On How Iterative Magnitude Pruning Discovers Local Receptive Fields in Fully Connected Neural Networks
Dec 09, 2024



Since its use in the Lottery Ticket Hypothesis, iterative magnitude pruning (IMP) has become a popular method for extracting sparse subnetworks that can be trained to high performance. Despite this, the underlying nature of IMP's general success remains unclear. One possibility is that IMP is especially capable of extracting and maintaining strong inductive biases. In support of this, recent work has shown that applying IMP to fully connected neural networks (FCNs) leads to the emergence of local receptive fields (RFs), an architectural feature present in mammalian visual cortex and convolutional neural networks. The question of how IMP is able to do this remains unanswered. Inspired by results showing that training FCNs on synthetic images with highly non-Gaussian statistics (e.g., sharp edges) is sufficient to drive the formation of local RFs, we hypothesize that IMP iteratively maximizes the non-Gaussian statistics present in the representations of FCNs, creating a feedback loop that enhances localization. We develop a new method for measuring the effect of individual weights on the statistics of the FCN representations ("cavity method"), which allows us to find evidence in support of this hypothesis. Our work, which is the first to study the effect IMP has on the representations of neural networks, sheds parsimonious light one way in which IMP can drive the formation of strong inductive biases.
A distributional simplicity bias in the learning dynamics of transformers
Oct 25, 2024



The remarkable capability of over-parameterised neural networks to generalise effectively has been explained by invoking a ``simplicity bias'': neural networks prevent overfitting by initially learning simple classifiers before progressing to more complex, non-linear functions. While simplicity biases have been described theoretically and experimentally in feed-forward networks for supervised learning, the extent to which they also explain the remarkable success of transformers trained with self-supervised techniques remains unclear. In our study, we demonstrate that transformers, trained on natural language data, also display a simplicity bias. Specifically, they sequentially learn many-body interactions among input tokens, reaching a saturation point in the prediction error for low-degree interactions while continuing to learn high-degree interactions. To conduct this analysis, we develop a procedure to generate \textit{clones} of a given natural language data set, which rigorously capture the interactions between tokens up to a specified order. This approach opens up the possibilities of studying how interactions of different orders in the data affect learning, in natural language processing and beyond.
Sliding down the stairs: how correlated latent variables accelerate learning with neural networks
Apr 12, 2024

Neural networks extract features from data using stochastic gradient descent (SGD). In particular, higher-order input cumulants (HOCs) are crucial for their performance. However, extracting information from the $p$th cumulant of $d$-dimensional inputs is computationally hard: the number of samples required to recover a single direction from an order-$p$ tensor (tensor PCA) using online SGD grows as $d^{p-1}$, which is prohibitive for high-dimensional inputs. This result raises the question of how neural networks extract relevant directions from the HOCs of their inputs efficiently. Here, we show that correlations between latent variables along the directions encoded in different input cumulants speed up learning from higher-order correlations. We show this effect analytically by deriving nearly sharp thresholds for the number of samples required by a single neuron to weakly-recover these directions using online SGD from a random start in high dimensions. Our analytical results are confirmed in simulations of two-layer neural networks and unveil a new mechanism for hierarchical learning in neural networks.
Learning from higher-order statistics, efficiently: hypothesis tests, random features, and neural networks
Dec 22, 2023Neural networks excel at discovering statistical patterns in high-dimensional data sets. In practice, higher-order cumulants, which quantify the non-Gaussian correlations between three or more variables, are particularly important for the performance of neural networks. But how efficient are neural networks at extracting features from higher-order cumulants? We study this question in the spiked cumulant model, where the statistician needs to recover a privileged direction or "spike" from the order-$p\ge 4$ cumulants of~$d$-dimensional inputs. We first characterise the fundamental statistical and computational limits of recovering the spike by analysing the number of samples~$n$ required to strongly distinguish between inputs from the spiked cumulant model and isotropic Gaussian inputs. We find that statistical distinguishability requires $n\gtrsim d$ samples, while distinguishing the two distributions in polynomial time requires $n \gtrsim d^2$ samples for a wide class of algorithms, i.e. those covered by the low-degree conjecture. These results suggest the existence of a wide statistical-to-computational gap in this problem. Numerical experiments show that neural networks learn to distinguish the two distributions with quadratic sample complexity, while "lazy" methods like random features are not better than random guessing in this regime. Our results show that neural networks extract information from higher-order correlations in the spiked cumulant model efficiently, and reveal a large gap in the amount of data required by neural networks and random features to learn from higher-order cumulants.