 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential syntactic and semantic encoding in LLMs
Jan 08, 2026We study how syntactic and semantic information is encoded in inner layer representations of Large Language Models (LLMs), focusing on the very large DeepSeek-V3. We find that, by averaging hidden-representation vectors of sentences sharing syntactic structure or meaning, we obtain vectors that capture a significant proportion of the syntactic and semantic information contained in the representations. In particular, subtracting these syntactic and semantic ``centroids'' from sentence vectors strongly affects their similarity with syntactically and semantically matched sentences, respectively, suggesting that syntax and semantics are, at least partially, linearly encoded. We also find that the cross-layer encoding profiles of syntax and semantics are different, and that the two signals can to some extent be decoupled, suggesting differential encoding of these two types of linguistic information in LLM representations.
An approach to identify the most semantically informative deep representations of text and images
May 21, 2025Deep neural networks are known to develop similar representations for semantically related data, even when they belong to different domains, such as an image and its description, or the same text in different languages. We present a method for quantitatively investigating this phenomenon by measuring the relative information content of the representations of semantically related data and probing how it is encoded into multiple tokens of large language models (LLMs) and vision transformers. Looking first at how LLMs process pairs of translated sentences, we identify inner ``semantic'' layers containing the most language-transferable information. We find moreover that, on these layers, a larger LLM (DeepSeek-V3) extracts significantly more general information than a smaller one (Llama3.1-8B). Semantic information is spread across many tokens and it is characterized by long-distance correlations between tokens and by a causal left-to-right (i.e., past-future) asymmetry. We also identify layers encoding semantic information within visual transformers. We show that caption representations in the semantic layers of LLMs predict visual representations of the corresponding images. We observe significant and model-dependent information asymmetries between image and text representations.
Detecting Localized Density Anomalies in Multivariate Data via Coin-Flip Statistics
Mar 31, 2025



Detecting localized density differences in multivariate data is a crucial task in computational science. Such anomalies can indicate a critical system failure, lead to a groundbreaking scientific discovery, or reveal unexpected changes in data distribution. We introduce EagleEye, an anomaly detection method to compare two multivariate datasets with the aim of identifying local density anomalies, namely over- or under-densities affecting only localised regions of the feature space. Anomalies are detected by modelling, for each point, the ordered sequence of its neighbours' membership label as a coin-flipping process and monitoring deviations from the expected behaviour of such process. A unique advantage of our method is its ability to provide an accurate, entirely unsupervised estimate of the local signal purity. We demonstrate its effectiveness through experiments on both synthetic and real-world datasets. In synthetic data, EagleEye accurately detects anomalies in multiple dimensions even when they affect a tiny fraction of the data. When applied to a challenging resonant anomaly detection benchmark task in simulated Large Hadron Collider data, EagleEye successfully identifies particle decay events present in just 0.3% of the dataset. In global temperature data, EagleEye uncovers previously unidentified, geographically localised changes in temperature fields that occurred in the most recent years. Thanks to its key advantages of conceptual simplicity, computational efficiency, trivial parallelisation, and scalability, EagleEye is widely applicable across many fields.
Unsupervised detection of semantic correlations in big data
Nov 04, 2024
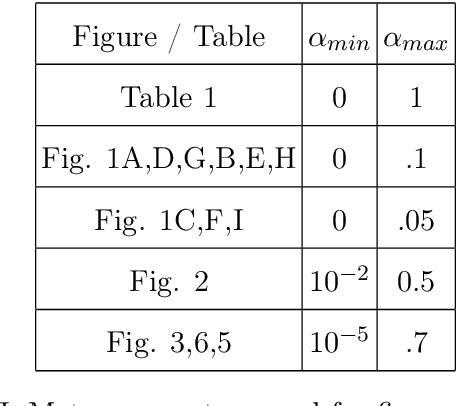
In real-world data, information is stored in extremely large feature vectors. These variables are typically correlated due to complex interactions involving many features simultaneously. Such correlations qualitatively correspond to semantic roles and are naturally recognized by both the human brain and artificial neural networks. This recognition enables, for instance, the prediction of missing parts of an image or text based on their context. We present a method to detect these correlations in high-dimensional data represented as binary numbers. We estimate the binary intrinsic dimension of a dataset, which quantifies the minimum number of independent coordinates needed to describe the data, and is therefore a proxy of semantic complexity. The proposed algorithm is largely insensitive to the so-called curse of dimensionality, and can therefore be used in big data analysis. We test this approach identifying phase transitions in model magnetic systems and we then apply it to the detection of semantic correlations of images and text inside deep neural networks.
Automatic feature selection and weighting using Differentiable Information Imbalance
Oct 30, 2024Feature selection is a common process in many applications, but it is accompanied by uncertainties such as: What is the optimal dimensionality of an interpretable, reduced feature space to retain a maximum amount of information? How to account for different units of measure in features? How to weight different features according to their importance? To address these challenges, we introduce the Differentiable Information Imbalance (DII), an automatic data analysis method to rank information content between sets of features. Based on the nearest neighbors according to distances in the ground truth feature space, the method finds a low-dimensional subset of the input features, within which the pairwise distance relations are most similar to the ground truth. By employing the Differentiable Information Imbalance as a loss function, the relative feature weights of the inputs are optimized, simultaneously performing unit alignment and relative importance scaling, while preserving interpretability. Furthermore, this method can generate sparse solutions and determine the optimal size of the reduced feature space. We illustrate the usefulness of this approach on two prototypical benchmark problems: (1) Identifying a small set of collective variables capable of describing the conformational space of a biomolecule, and (2) selecting a subset of features for training a machine-learning force field. The results highlight the potential of the Differentiable Information Imbalance in addressing feature selection challenges and optimizing dimensionality in various applications. The method is implemented in the Python library DADApy.
A distributional simplicity bias in the learning dynamics of transformers
Oct 25, 2024



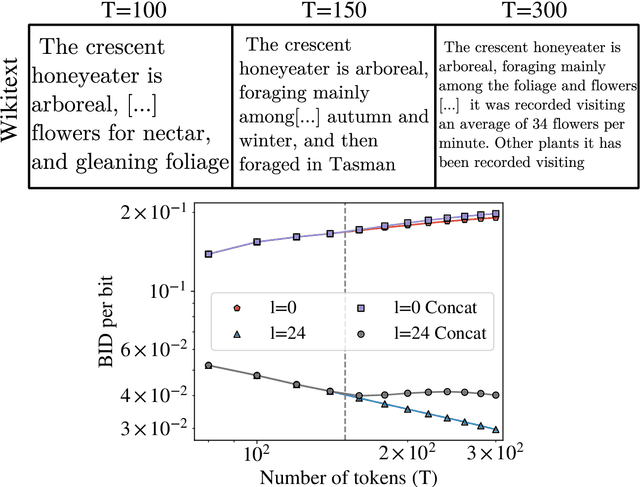
The remarkable capability of over-parameterised neural networks to generalise effectively has been explained by invoking a ``simplicity bias'': neural networks prevent overfitting by initially learning simple classifiers before progressing to more complex, non-linear functions. While simplicity biases have been described theoretically and experimentally in feed-forward networks for supervised learning, the extent to which they also explain the remarkable success of transformers trained with self-supervised techniques remains unclear. In our study, we demonstrate that transformers, trained on natural language data, also display a simplicity bias. Specifically, they sequentially learn many-body interactions among input tokens, reaching a saturation point in the prediction error for low-degree interactions while continuing to learn high-degree interactions. To conduct this analysis, we develop a procedure to generate \textit{clones} of a given natural language data set, which rigorously capture the interactions between tokens up to a specified order. This approach opens up the possibilities of studying how interactions of different orders in the data affect learning, in natural language processing and beyond.
Density Estimation via Binless Multidimensional Integration
Jul 10, 2024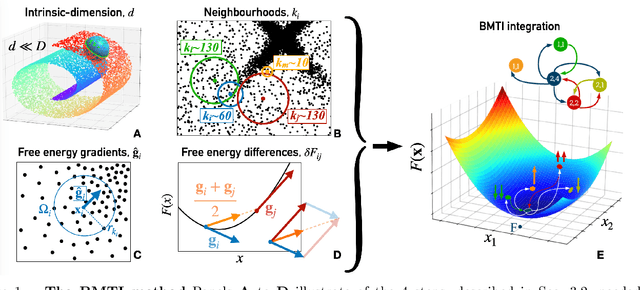
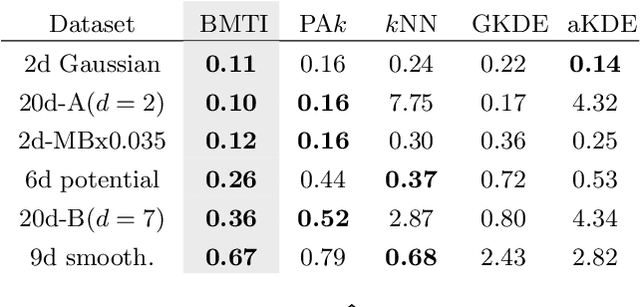
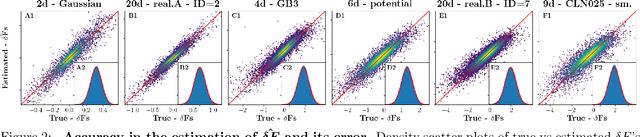
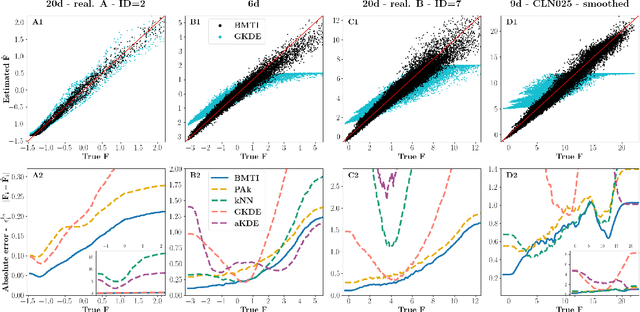
We introduce the Binless Multidimensional Thermodynamic Integration (BMTI) method for nonparametric, robust, and data-efficient density estimation. BMTI estimates the logarithm of the density by initially computing log-density differences between neighbouring data points. Subsequently, such differences are integrated, weighted by their associated uncertainties, using a maximum-likelihood formulation. This procedure can be seen as an extension to a multidimensional setting of the thermodynamic integration, a technique developed in statistical physics. The method leverages the manifold hypothesis, estimating quantities within the intrinsic data manifold without defining an explicit coordinate map. It does not rely on any binning or space partitioning, but rather on the construction of a neighbourhood graph based on an adaptive bandwidth selection procedure. BMTI mitigates the limitations commonly associated with traditional nonparametric density estimators, effectively reconstructing smooth profiles even in high-dimensional embedding spaces. The method is tested on a variety of complex synthetic high-dimensional datasets, where it is shown to outperform traditional estimators, and is benchmarked on realistic datasets from the chemical physics literature.
Beyond the noise: intrinsic dimension estimation with optimal neighbourhood identification
May 24, 2024



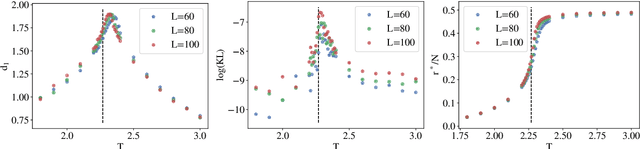
The Intrinsic Dimension (ID) is a key concept in unsupervised learning and feature selection, as it is a lower bound to the number of variables which are necessary to describe a system. However, in almost any real-world dataset the ID depends on the scale at which the data are analysed. Quite typically at a small scale, the ID is very large, as the data are affected by measurement errors. At large scale, the ID can also be erroneously large, due to the curvature and the topology of the manifold containing the data. In this work, we introduce an automatic protocol to select the sweet spot, namely the correct range of scales in which the ID is meaningful and useful. This protocol is based on imposing that for distances smaller than the correct scale the density of the data is constant. Since to estimate the density it is necessary to know the ID, this condition is imposed self-consistently. We illustrate the usefulness and robustness of this procedure by benchmarks on artificial and real-world datasets.
Emergence of a High-Dimensional Abstraction Phase in Language Transformers
May 24, 2024



A language model (LM) is a mapping from a linguistic context to an output token. However, much remains to be known about this mapping, including how its geometric properties relate to its function. We take a high-level geometric approach to its analysis, observing, across five pre-trained transformer-based LMs and three input datasets, a distinct phase characterized by high intrinsic dimensionality. During this phase, representations (1) correspond to the first full linguistic abstraction of the input; (2) are the first to viably transfer to downstream tasks; (3) predict each other across different LMs. Moreover, we find that an earlier onset of the phase strongly predicts better language modelling performance. In short, our results suggest that a central high-dimensionality phase underlies core linguistic processing in many common LM architectures.
Optimal inference of a generalised Potts model by single-layer transformers with factored attention
Apr 14, 2023Transformers are the type of neural networks that has revolutionised natural language processing and protein science. Their key building block is a mechanism called self-attention which is trained to predict missing words in sentences. Despite the practical success of transformers in applications it remains unclear what self-attention learns from data, and how. Here, we give a precise analytical and numerical characterisation of transformers trained on data drawn from a generalised Potts model with interactions between sites and Potts colours. While an off-the-shelf transformer requires several layers to learn this distribution, we show analytically that a single layer of self-attention with a small modification can learn the Potts model exactly in the limit of infinite sampling. We show that this modified self-attention, that we call ``factored'', has the same functional form as the conditional probability of a Potts spin given the other spins, compute its generalisation error using the replica method from statistical physics, and derive an exact mapping to pseudo-likelihood methods for solving the inverse Ising and Potts problem.