 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic feature selection and weighting using Differentiable Information Imbalance
Oct 30, 2024Feature selection is a common process in many applications, but it is accompanied by uncertainties such as: What is the optimal dimensionality of an interpretable, reduced feature space to retain a maximum amount of information? How to account for different units of measure in features? How to weight different features according to their importance? To address these challenges, we introduce the Differentiable Information Imbalance (DII), an automatic data analysis method to rank information content between sets of features. Based on the nearest neighbors according to distances in the ground truth feature space, the method finds a low-dimensional subset of the input features, within which the pairwise distance relations are most similar to the ground truth. By employing the Differentiable Information Imbalance as a loss function, the relative feature weights of the inputs are optimized, simultaneously performing unit alignment and relative importance scaling, while preserving interpretability. Furthermore, this method can generate sparse solutions and determine the optimal size of the reduced feature space. We illustrate the usefulness of this approach on two prototypical benchmark problems: (1) Identifying a small set of collective variables capable of describing the conformational space of a biomolecule, and (2) selecting a subset of features for training a machine-learning force field. The results highlight the potential of the Differentiable Information Imbalance in addressing feature selection challenges and optimizing dimensionality in various applications. The method is implemented in the Python library DADApy.
DADApy: Distance-based Analysis of DAta-manifolds in Python
May 04, 2022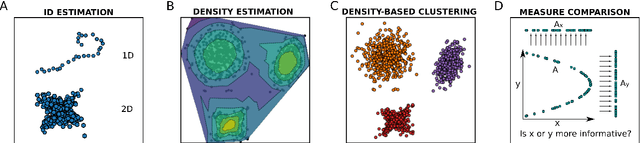
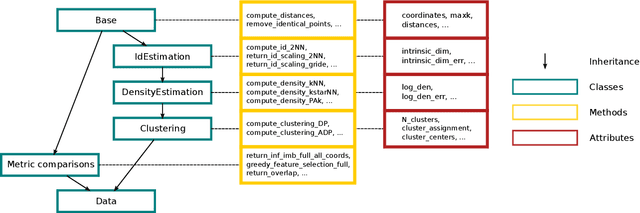

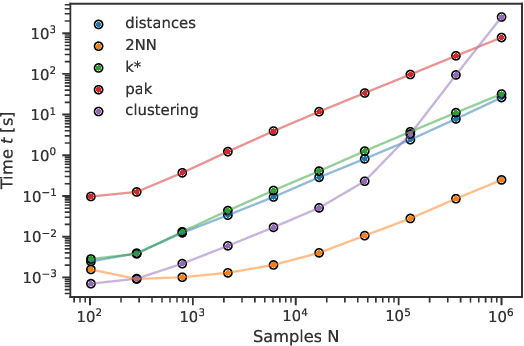
DADApy is a python software package for analysing and characterising high-dimensional data manifolds. It provides methods for estimating the intrinsic dimension and the probability density, for performing density-based clustering and for comparing different distance metrics. We review the main functionalities of the package and exemplify its usage in toy cases and in a real-world application. The package is freely available under the open-source Apache 2.0 license and can be downloaded from the Github page https://github.com/sissa-data-science/DADApy.