 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGenX: Unified Generation of Sequence and Structure with Autoregressive Diffusion
Mar 09, 2025Unified generation of sequence and structure for scientific data (e.g., materials, molecules, proteins) is a critical task. Existing approaches primarily rely on either autoregressive sequence models or diffusion models, each offering distinct advantages and facing notable limitations. Autoregressive models, such as GPT, Llama, and Phi-4, have demonstrated remarkable success in natural language generation and have been extended to multimodal tasks (e.g., image, video, and audio) using advanced encoders like VQ-VAE to represent complex modalities as discrete sequences. However, their direct application to scientific domains is challenging due to the high precision requirements and the diverse nature of scientific data. On the other hand, diffusion models excel at generating high-dimensional scientific data, such as protein, molecule, and material structures, with remarkable accuracy. Yet, their inability to effectively model sequences limits their potential as general-purpose multimodal foundation models. To address these challenges, we propose UniGenX, a unified framework that combines autoregressive next-token prediction with conditional diffusion models. This integration leverages the strengths of autoregressive models to ease the training of conditional diffusion models, while diffusion-based generative heads enhance the precision of autoregressive predictions. We validate the effectiveness of UniGenX on material and small molecule generation tasks, achieving a significant leap in state-of-the-art performance for material crystal structure prediction and establishing new state-of-the-art results for small molecule structure prediction, de novo design, and conditional generation. Notably, UniGenX demonstrates significant improvements, especially in handling long sequences for complex structures, showcasing its efficacy as a versatile tool for scientific data generation.
MatterGen: a generative model for inorganic materials design
Dec 06, 2023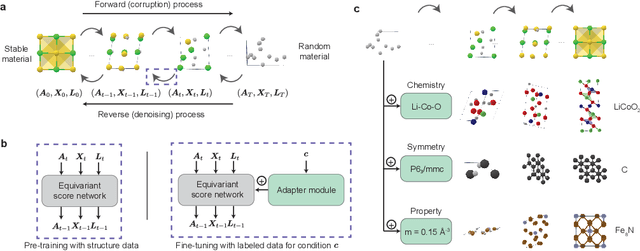
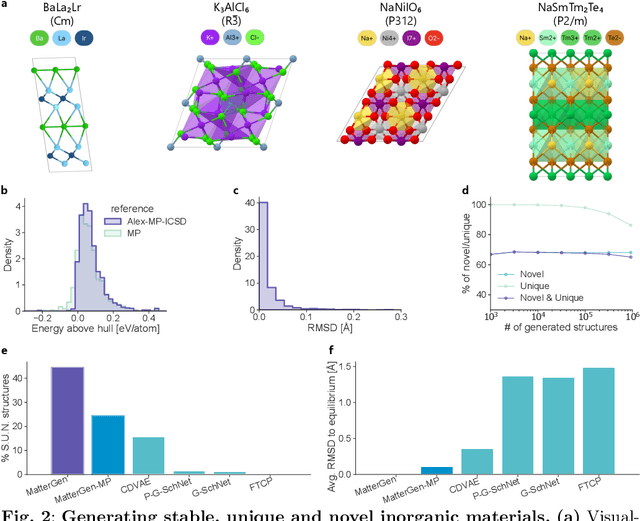
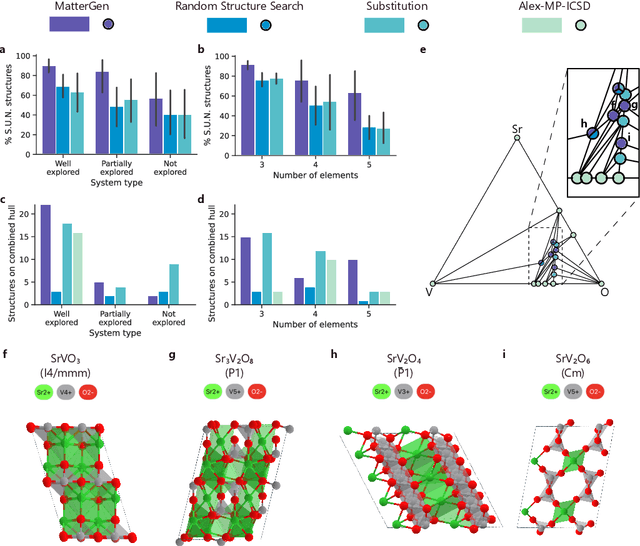
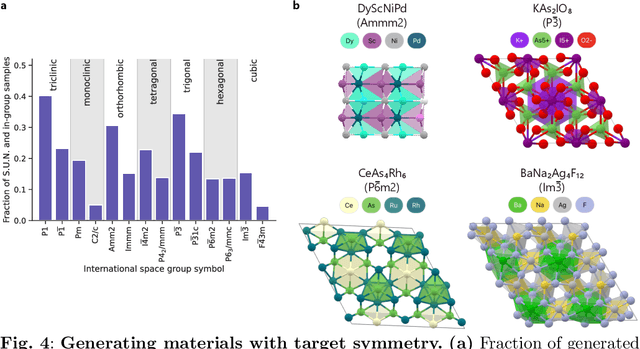
The design of functional materials with desired properties is essential in driving technological advances in areas like energy storage, catalysis, and carbon capture. Generative models provide a new paradigm for materials design by directly generating entirely novel materials given desired property constraints. Despite recent progress, current generative models have low success rate in proposing stable crystals, or can only satisfy a very limited set of property constraints. Here, we present MatterGen, a model that generates stable, diverse inorganic materials across the periodic table and can further be fine-tuned to steer the generation towards a broad range of property constraints. To enable this, we introduce a new diffusion-based generative process that produces crystalline structures by gradually refining atom types, coordinates, and the periodic lattice. We further introduce adapter modules to enable fine-tuning towards any given property constraints with a labeled dataset. Compared to prior generative models, structures produced by MatterGen are more than twice as likely to be novel and stable, and more than 15 times closer to the local energy minimum. After fine-tuning, MatterGen successfully generates stable, novel materials with desired chemistry, symmetry, as well as mechanical, electronic and magnetic properties. Finally, we demonstrate multi-property materials design capabilities by proposing structures that have both high magnetic density and a chemical composition with low supply-chain risk. We believe that the quality of generated materials and the breadth of MatterGen's capabilities represent a major advancement towards creating a universal generative model for materials design.
DADApy: Distance-based Analysis of DAta-manifolds in Python
May 04, 2022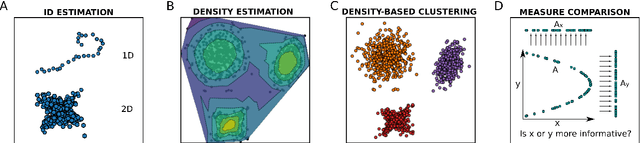
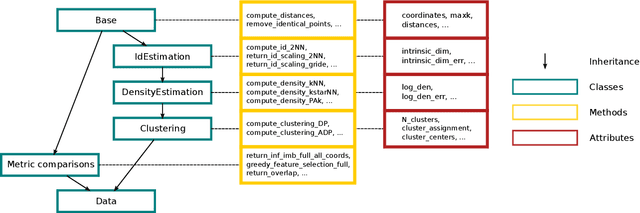

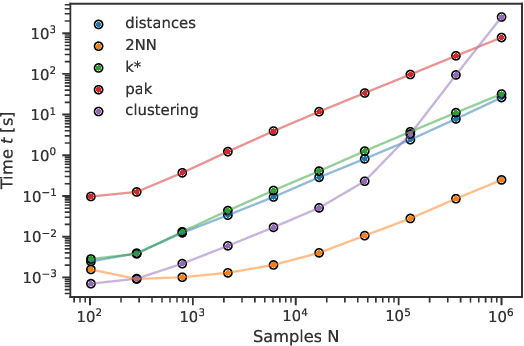
DADApy is a python software package for analysing and characterising high-dimensional data manifolds. It provides methods for estimating the intrinsic dimension and the probability density, for performing density-based clustering and for comparing different distance metrics. We review the main functionalities of the package and exemplify its usage in toy cases and in a real-world application. The package is freely available under the open-source Apache 2.0 license and can be downloaded from the Github page https://github.com/sissa-data-science/DADApy.
Ranking the information content of distance measures
Apr 30, 2021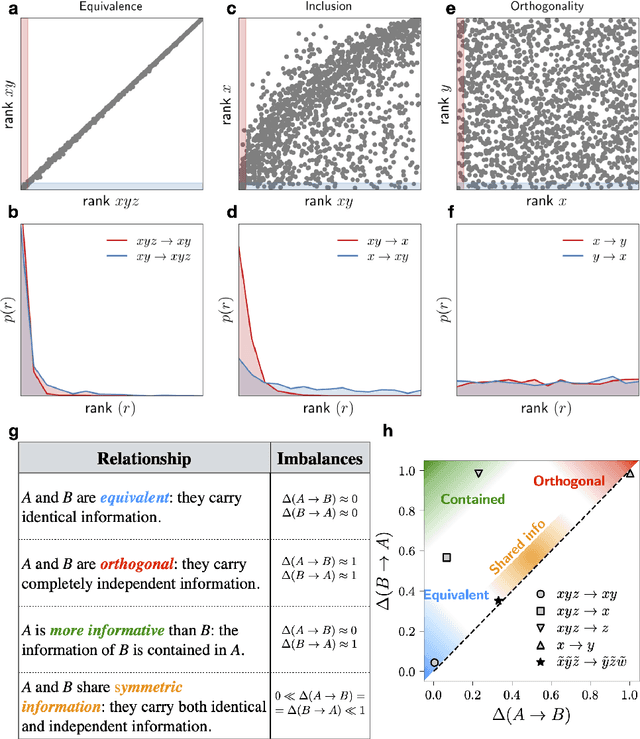
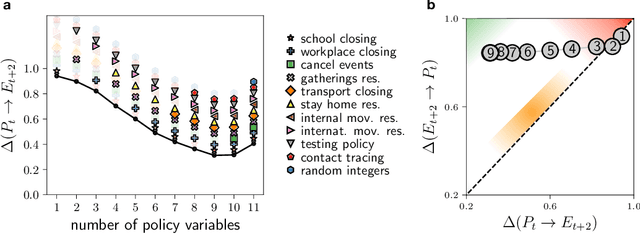
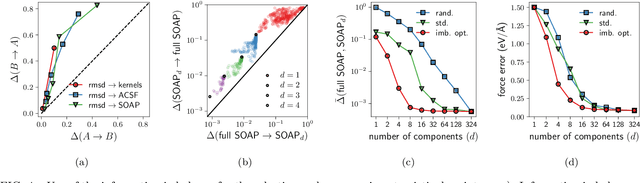
Real-world data typically contain a large number of features that are often heterogeneous in nature, relevance, and also units of measure. When assessing the similarity between data points, one can build various distance measures using subsets of these features. Using the fewest features but still retaining sufficient information about the system is crucial in many statistical learning approaches, particularly when data are sparse. We introduce a statistical test that can assess the relative information retained when using two different distance measures, and determine if they are equivalent, independent, or if one is more informative than the other. This in turn allows finding the most informative distance measure out of a pool of candidates. The approach is applied to find the most relevant policy variables for controlling the Covid-19 epidemic and to find compact yet informative representations of atomic structures, but its potential applications are wide ranging in many branches of science.