 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Evidence Synthesis: A Systematic Review of the Evolution of Automated Meta-Analysis in the Age of AI
Apr 28, 2025Exponential growth in scientific literature has heightened the demand for efficient evidence-based synthesis, driving the rise of the field of Automated Meta-analysis (AMA) powered by natural language processing and machine learning. This PRISMA systematic review introduces a structured framework for assessing the current state of AMA, based on screening 978 papers from 2006 to 2024, and analyzing 54 studies across diverse domains. Findings reveal a predominant focus on automating data processing (57%), such as extraction and statistical modeling, while only 17% address advanced synthesis stages. Just one study (2%) explored preliminary full-process automation, highlighting a critical gap that limits AMA's capacity for comprehensive synthesis. Despite recent breakthroughs in large language models (LLMs) and advanced AI, their integration into statistical modeling and higher-order synthesis, such as heterogeneity assessment and bias evaluation, remains underdeveloped. This has constrained AMA's potential for fully autonomous meta-analysis. From our dataset spanning medical (67%) and non-medical (33%) applications, we found that AMA has exhibited distinct implementation patterns and varying degrees of effectiveness in actually improving efficiency, scalability, and reproducibility. While automation has enhanced specific meta-analytic tasks, achieving seamless, end-to-end automation remains an open challenge. As AI systems advance in reasoning and contextual understanding, addressing these gaps is now imperative. Future efforts must focus on bridging automation across all meta-analysis stages, refining interpretability, and ensuring methodological robustness to fully realize AMA's potential for scalable, domain-agnostic synthesis.
UniGenX: Unified Generation of Sequence and Structure with Autoregressive Diffusion
Mar 09, 2025Unified generation of sequence and structure for scientific data (e.g., materials, molecules, proteins) is a critical task. Existing approaches primarily rely on either autoregressive sequence models or diffusion models, each offering distinct advantages and facing notable limitations. Autoregressive models, such as GPT, Llama, and Phi-4, have demonstrated remarkable success in natural language generation and have been extended to multimodal tasks (e.g., image, video, and audio) using advanced encoders like VQ-VAE to represent complex modalities as discrete sequences. However, their direct application to scientific domains is challenging due to the high precision requirements and the diverse nature of scientific data. On the other hand, diffusion models excel at generating high-dimensional scientific data, such as protein, molecule, and material structures, with remarkable accuracy. Yet, their inability to effectively model sequences limits their potential as general-purpose multimodal foundation models. To address these challenges, we propose UniGenX, a unified framework that combines autoregressive next-token prediction with conditional diffusion models. This integration leverages the strengths of autoregressive models to ease the training of conditional diffusion models, while diffusion-based generative heads enhance the precision of autoregressive predictions. We validate the effectiveness of UniGenX on material and small molecule generation tasks, achieving a significant leap in state-of-the-art performance for material crystal structure prediction and establishing new state-of-the-art results for small molecule structure prediction, de novo design, and conditional generation. Notably, UniGenX demonstrates significant improvements, especially in handling long sequences for complex structures, showcasing its efficacy as a versatile tool for scientific data generation.
Comprehensive Review and Empirical Evaluation of Causal Discovery Algorithms for Numerical Data
Jul 17, 2024Causal analysis has become an essential component in understanding the underlying causes of phenomena across various fields. Despite its significance, the existing literature on causal discovery algorithms is fragmented, with inconsistent methodologies and a lack of comprehensive evaluations. This study addresses these gaps by conducting an exhaustive review and empirical evaluation of causal discovery methods for numerical data, aiming to provide a clearer and more structured understanding of the field. Our research began with a comprehensive literature review spanning over a decade, revealing that existing surveys fall short in covering the vast array of causal discovery advancements. We meticulously analyzed over 200 scholarly articles to identify 24 distinct algorithms. This extensive analysis led to the development of a novel taxonomy tailored to the complexities of causal discovery, categorizing methods into six main types. Addressing the lack of comprehensive evaluations, our study conducts an extensive empirical assessment of more than 20 causal discovery algorithms on synthetic and real-world datasets. We categorize synthetic datasets based on size, linearity, and noise distribution, employing 5 evaluation metrics, and summarized the top-3 algorithm recommendations for different data scenarios. The recommendations have been validated on 2 real-world datasets. Our results highlight the significant impact of dataset characteristics on algorithm performance. Moreover, a metadata extraction strategy was developed to assist users in algorithm selection on unknown datasets. The accuracy of estimating metadata is higher than 80%. Based on these insights, we offer professional and practical recommendations to help users choose the most suitable causal discovery methods for their specific dataset needs.
Data Augmentation for Time-Series Classification: An Extensive Empirical Study and Comprehensive Survey
Oct 19, 2023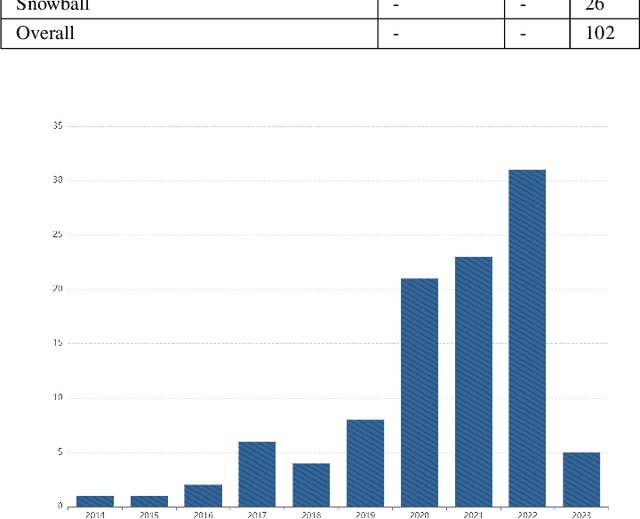
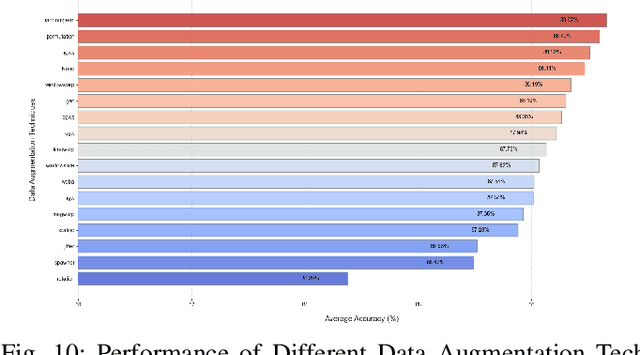
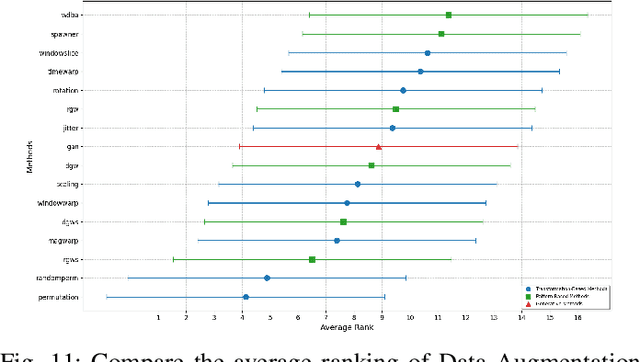
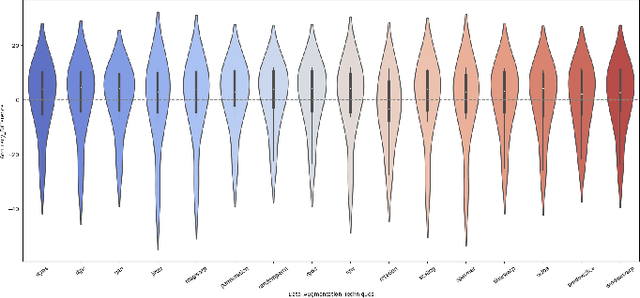
Data Augmentation (DA) has emerged as an indispensable strategy in Time Series Classification (TSC), primarily due to its capacity to amplify training samples, thereby bolstering model robustness, diversifying datasets, and curtailing overfitting. However, the current landscape of DA in TSC is plagued with fragmented literature reviews, nebulous methodological taxonomies, inadequate evaluative measures, and a dearth of accessible, user-oriented tools. In light of these challenges, this study embarks on an exhaustive dissection of DA methodologies within the TSC realm. Our initial approach involved an extensive literature review spanning a decade, revealing that contemporary surveys scarcely capture the breadth of advancements in DA for TSC, prompting us to meticulously analyze over 100 scholarly articles to distill more than 60 unique DA techniques. This rigorous analysis precipitated the formulation of a novel taxonomy, purpose-built for the intricacies of DA in TSC, categorizing techniques into five principal echelons: Transformation-Based, Pattern-Based, Generative, Decomposition-Based, and Automated Data Augmentation. Our taxonomy promises to serve as a robust navigational aid for scholars, offering clarity and direction in method selection. Addressing the conspicuous absence of holistic evaluations for prevalent DA techniques, we executed an all-encompassing empirical assessment, wherein upwards of 15 DA strategies were subjected to scrutiny across 8 UCR time-series datasets, employing ResNet and a multi-faceted evaluation paradigm encompassing Accuracy, Method Ranking, and Residual Analysis, yielding a benchmark accuracy of 88.94 +- 11.83%. Our investigation underscored the inconsistent efficacies of DA techniques, with...
evoML Yellow Paper: Evolutionary AI and Optimisation Studio
Dec 20, 2022
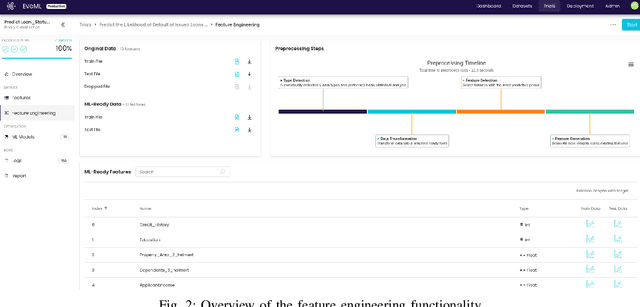
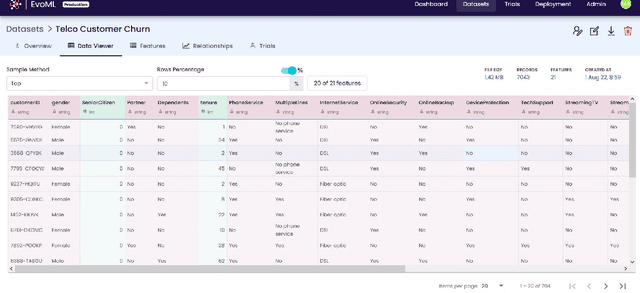
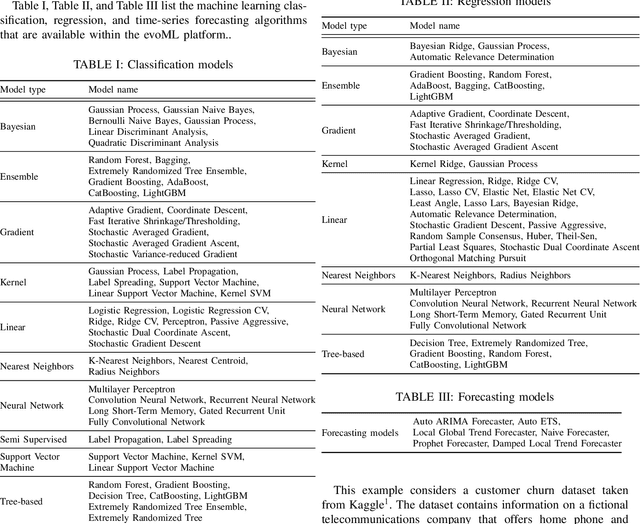
Machine learning model development and optimisation can be a rather cumbersome and resource-intensive process. Custom models are often more difficult to build and deploy, and they require infrastructure and expertise which are often costly to acquire and maintain. Machine learning product development lifecycle must take into account the need to navigate the difficulties of developing and deploying machine learning models. evoML is an AI-powered tool that provides automated functionalities in machine learning model development, optimisation, and model code optimisation. Core functionalities of evoML include data cleaning, exploratory analysis, feature analysis and generation, model optimisation, model evaluation, model code optimisation, and model deployment. Additionally, a key feature of evoML is that it embeds code and model optimisation into the model development process, and includes multi-objective optimisation capabilities.
ASTA: Learning Analytical Semantics over Tables for Intelligent Data Analysis and Visualization
Aug 08, 2022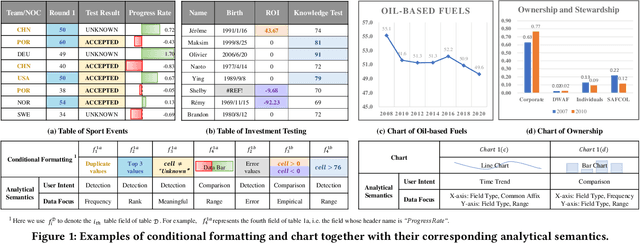

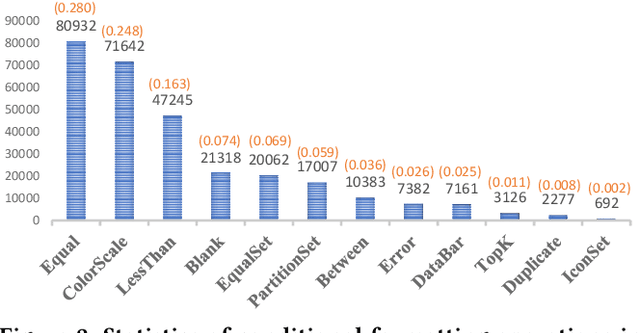
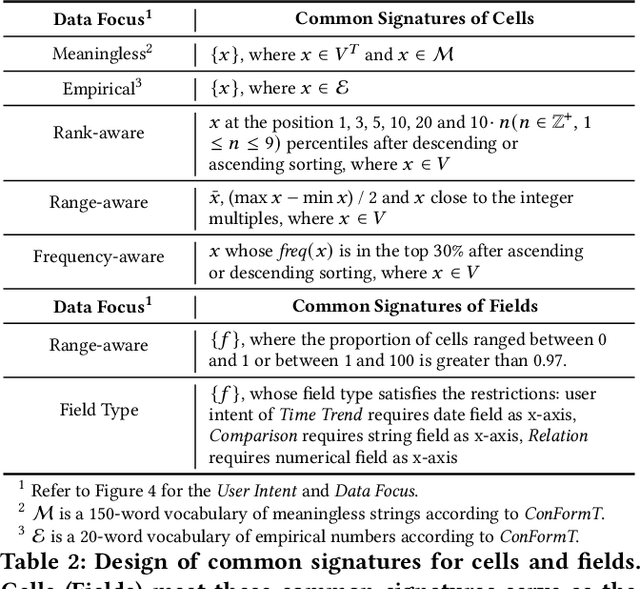
Intelligent analysis and visualization of tables use techniques to automatically recommend useful knowledge from data, thus freeing users from tedious multi-dimension data mining. While many studies have succeeded in automating recommendations through rules or machine learning, it is difficult to generalize expert knowledge and provide explainable recommendations. In this paper, we present the recommendation of conditional formatting for the first time, together with chart recommendation, to exemplify intelligent table analysis. We propose analytical semantics over tables to uncover common analysis pattern behind user-created analyses. Here, we design analytical semantics by separating data focus from user intent, which extract the user motivation from data and human perspective respectively. Furthermore, the ASTA framework is designed by us to apply analytical semantics to multiple automated recommendations. ASTA framework extracts data features by designing signatures based on expert knowledge, and enables data referencing at field- (chart) or cell-level (conditional formatting) with pre-trained models. Experiments show that our framework achieves recall at top 1 of 62.86% on public chart corpora, outperforming the best baseline about 14%, and achieves 72.31% on the collected corpus ConFormT, validating that ASTA framework is effective in providing accurate and explainable recommendations.
Better Model Selection with a new Definition of Feature Importance
Sep 16, 2020
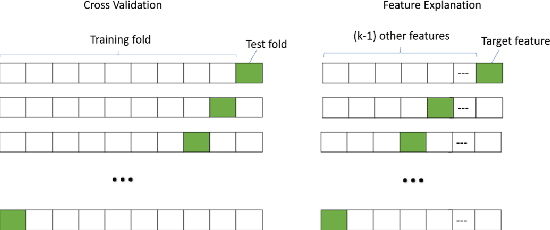
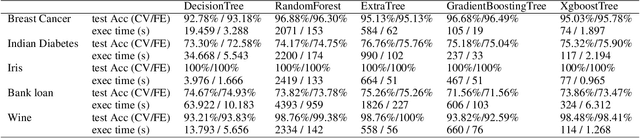
Feature importance aims at measuring how crucial each input feature is for model prediction. It is widely used in feature engineering, model selection and explainable artificial intelligence (XAI). In this paper, we propose a new tree-model explanation approach for model selection. Our novel concept leverages the Coefficient of Variation of a feature weight (measured in terms of the contribution of the feature to the prediction) to capture the dispersion of importance over samples. Extensive experimental results show that our novel feature explanation performs better than general cross validation method in model selection both in terms of time efficiency and accuracy performance.
IEO: Intelligent Evolutionary Optimisation for Hyperparameter Tuning
Sep 10, 2020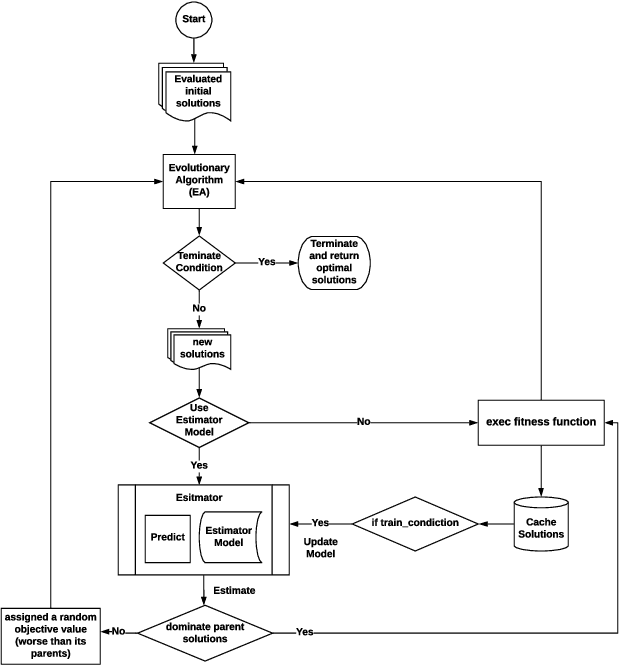
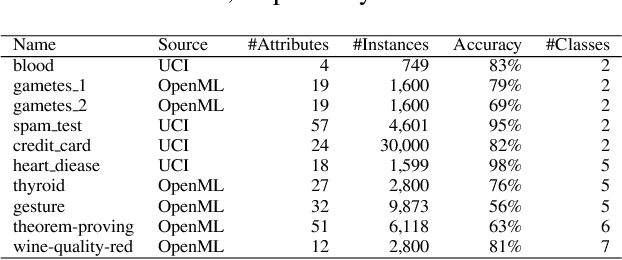
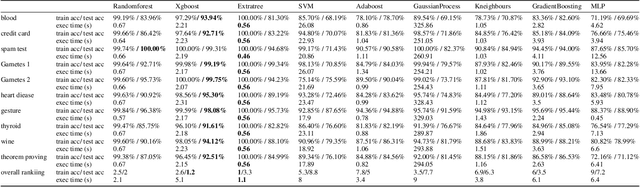
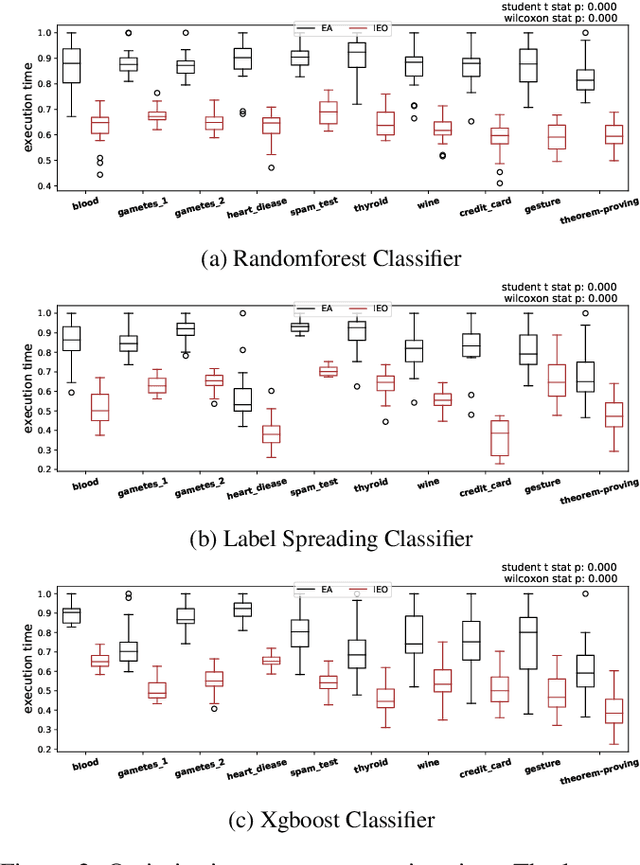
Hyperparameter optimisation is a crucial process in searching the optimal machine learning model. The efficiency of finding the optimal hyperparameter settings has been a big concern in recent researches since the optimisation process could be time-consuming, especially when the objective functions are highly expensive to evaluate. In this paper, we introduce an intelligent evolutionary optimisation algorithm which applies machine learning technique to the traditional evolutionary algorithm to accelerate the overall optimisation process of tuning machine learning models in classification problems. We demonstrate our Intelligent Evolutionary Optimisation (IEO)in a series of controlled experiments, comparing with traditional evolutionary optimisation in hyperparameter tuning. The empirical study shows that our approach accelerates the optimisation speed by 30.40% on average and up to 77.06% in the best scenarios.
Ascertaining price formation in cryptocurrency markets with DeepLearning
Feb 09, 2020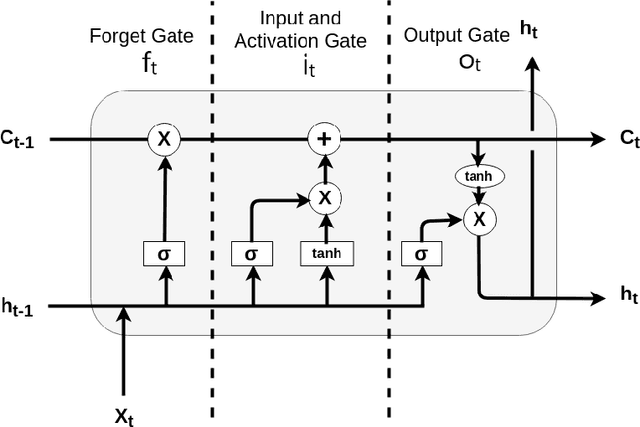

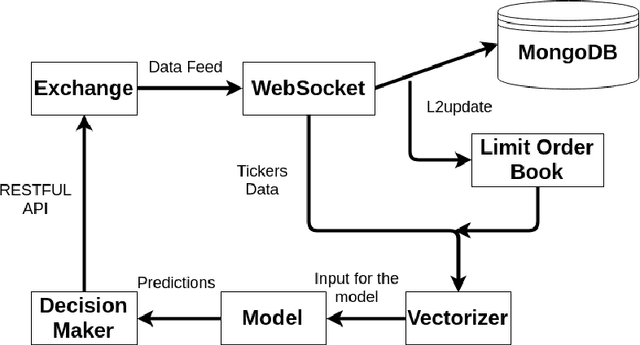
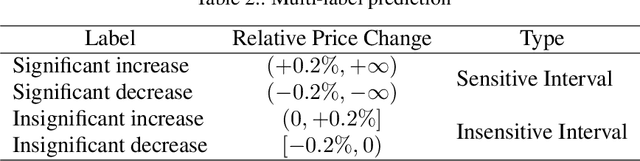
The cryptocurrency market is amongst the fastest-growing of all the financial markets in the world. Unlike traditional markets, such as equities, foreign exchange and commodities, cryptocurrency market is considered to have larger volatility and illiquidity. This paper is inspired by the recent success of using deep learning for stock market prediction. In this work, we analyze and present the characteristics of the cryptocurrency market in a high-frequency setting. In particular, we applied a deep learning approach to predict the direction of the mid-price changes on the upcoming tick. We monitored live tick-level data from $8$ cryptocurrency pairs and applied both statistical and machine learning techniques to provide a live prediction. We reveal that promising results are possible for cryptocurrencies, and in particular, we achieve a consistent $78\%$ accuracy on the prediction of the mid-price movement on live exchange rate of Bitcoins vs US dollars.
Nested Dictionary Learning for Hierarchical Organization of Imagery and Text
Oct 16, 2012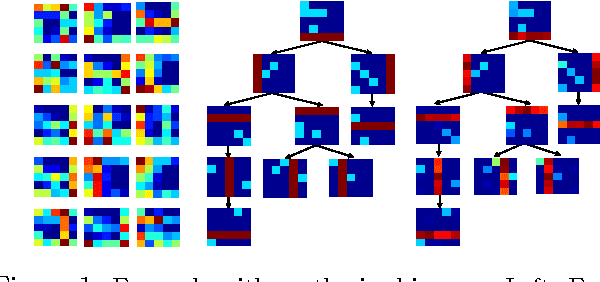
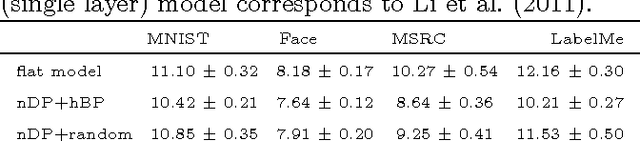
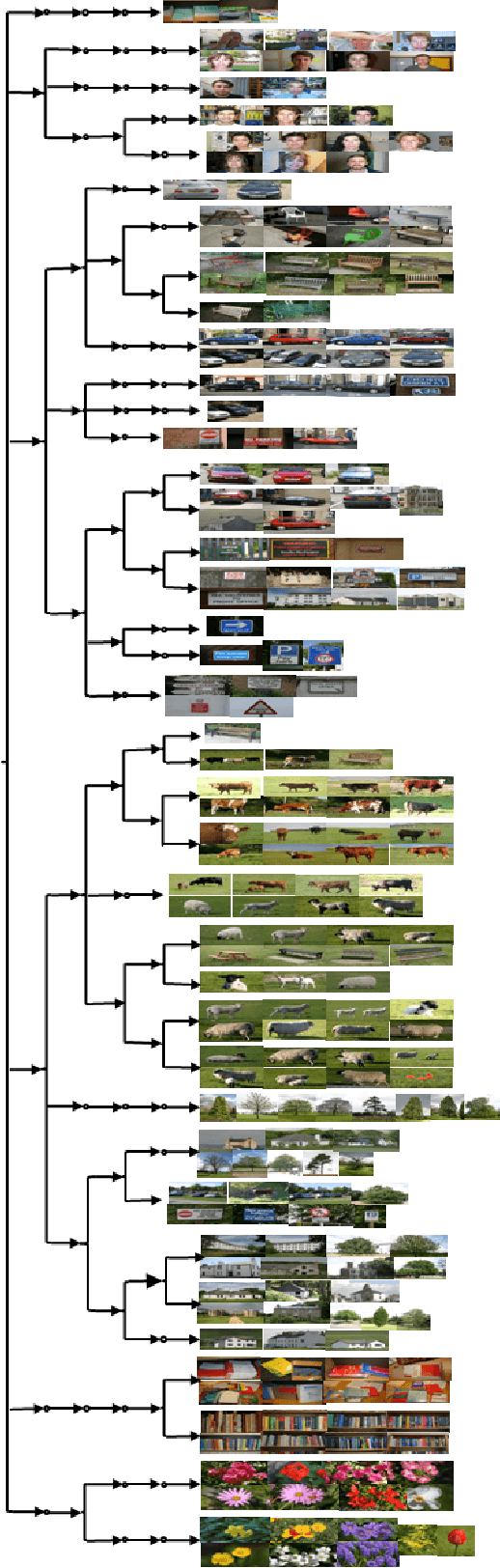
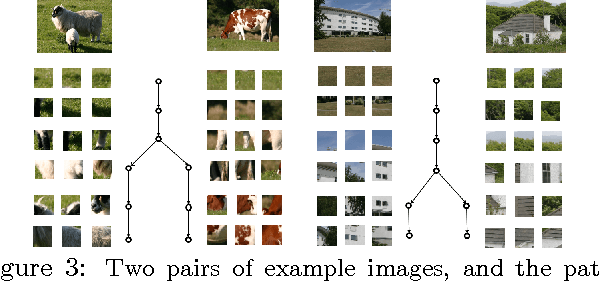
A tree-based dictionary learning model is developed for joint analysis of imagery and associated text. The dictionary learning may be applied directly to the imagery from patches, or to general feature vectors extracted from patches or superpixels (using any existing method for image feature extraction). Each image is associated with a path through the tree (from root to a leaf), and each of the multiple patches in a given image is associated with one node in that path. Nodes near the tree root are shared between multiple paths, representing image characteristics that are common among different types of images. Moving toward the leaves, nodes become specialized, representing details in image classes. If available, words (text) are also jointly modeled, with a path-dependent probability over words. The tree structure is inferred via a nested Dirichlet process, and a retrospective stick-breaking sampler is used to infer the tree depth and width.