 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffLOB: Diffusion Models for Counterfactual Generation in Limit Order Books
Feb 03, 2026Modern generative models for limit order books (LOBs) can reproduce realistic market dynamics, but remain fundamentally passive: they either model what typically happens without accounting for hypothetical future market conditions, or they require interaction with another agent to explore alternative outcomes. This limits their usefulness for stress testing, scenario analysis, and decision-making. We propose \textbf{DiffLOB}, a regime-conditioned \textbf{Diff}usion model for controllable and counterfactual generation of \textbf{LOB} trajectories. DiffLOB explicitly conditions the generative process on future market regimes--including trend, volatility, liquidity, and order-flow imbalance, which enables the model to answer counterfactual queries of the form: ``If the future market regime were X instead of Y, how would the limit order book evolve?'' Our systematic evaluation framework for counterfactual LOB generation consists of three criteria: (1) \textit{Controllable Realism}, measuring how well generated trajectories can reproduce marginal distributions, temporal dependence structure and regime variables; (2) \textit{Counterfactual validity}, testing whether interventions on future regimes induce consistent changes in the generated LOB dynamics; (3) \textit{Counterfactual usefulness}, assessing whether synthetic counterfactual trajectories improve downstream prediction of future market regimes.
Multi-Agent Reinforcement Learning for Market Making: Competition without Collusion
Oct 29, 2025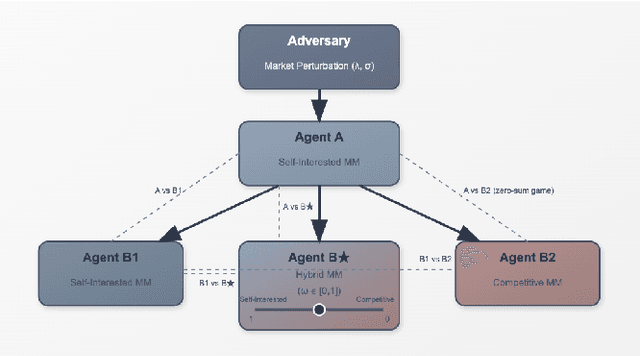



Algorithmic collusion has emerged as a central question in AI: Will the interaction between different AI agents deployed in markets lead to collusion? More generally, understanding how emergent behavior, be it a cartel or market dominance from more advanced bots, affects the market overall is an important research question. We propose a hierarchical multi-agent reinforcement learning framework to study algorithmic collusion in market making. The framework includes a self-interested market maker (Agent~A), which is trained in an uncertain environment shaped by an adversary, and three bottom-layer competitors: the self-interested Agent~B1 (whose objective is to maximize its own PnL), the competitive Agent~B2 (whose objective is to minimize the PnL of its opponent), and the hybrid Agent~B$^\star$, which can modulate between the behavior of the other two. To analyze how these agents shape the behavior of each other and affect market outcomes, we propose interaction-level metrics that quantify behavioral asymmetry and system-level dynamics, while providing signals potentially indicative of emergent interaction patterns. Experimental results show that Agent~B2 secures dominant performance in a zero-sum setting against B1, aggressively capturing order flow while tightening average spreads, thus improving market execution efficiency. In contrast, Agent~B$^\star$ exhibits a self-interested inclination when co-existing with other profit-seeking agents, securing dominant market share through adaptive quoting, yet exerting a milder adverse impact on the rewards of Agents~A and B1 compared to B2. These findings suggest that adaptive incentive control supports more sustainable strategic co-existence in heterogeneous agent environments and offers a structured lens for evaluating behavioral design in algorithmic trading systems.
DiffVolume: Diffusion Models for Volume Generation in Limit Order Books
Aug 12, 2025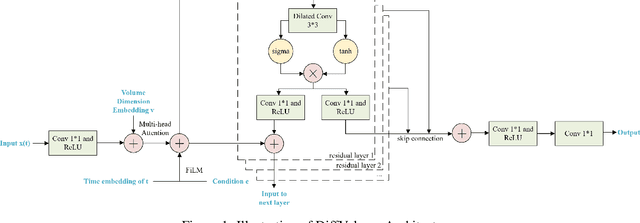


Modeling limit order books (LOBs) dynamics is a fundamental problem in market microstructure research. In particular, generating high-dimensional volume snapshots with strong temporal and liquidity-dependent patterns remains a challenging task, despite recent work exploring the application of Generative Adversarial Networks to LOBs. In this work, we propose a conditional \textbf{Diff}usion model for the generation of future LOB \textbf{Volume} snapshots (\textbf{DiffVolume}). We evaluate our model across three axes: (1) \textit{Realism}, where we show that DiffVolume, conditioned on past volume history and time of day, better reproduces statistical properties such as marginal distribution, spatial correlation, and autocorrelation decay; (2) \textit{Counterfactual generation}, allowing for controllable generation under hypothetical liquidity scenarios by additionally conditioning on a target future liquidity profile; and (3) \textit{Downstream prediction}, where we show that the synthetic counterfactual data from our model improves the performance of future liquidity forecasting models. Together, these results suggest that DiffVolume provides a powerful and flexible framework for realistic and controllable LOB volume generation.
Bitcoin's Edge: Embedded Sentiment in Blockchain Transactional Data
Apr 18, 2025



Cryptocurrency blockchains, beyond their primary role as distributed payment systems, are increasingly used to store and share arbitrary content, such as text messages and files. Although often non-financial, this hidden content can impact price movements by conveying private information, shaping sentiment, and influencing public opinion. However, current analyses of such data are limited in scope and scalability, primarily relying on manual classification or hand-crafted heuristics. In this work, we address these limitations by employing Natural Language Processing techniques to analyze, detect patterns, and extract public sentiment encoded within blockchain transactional data. Using a variety of Machine Learning techniques, we showcase for the first time the predictive power of blockchain-embedded sentiment in forecasting cryptocurrency price movements on the Bitcoin and Ethereum blockchains. Our findings shed light on a previously underexplored source of freely available, transparent, and immutable data and introduce blockchain sentiment analysis as a novel and robust framework for enhancing financial predictions in cryptocurrency markets. Incidentally, we discover an asymmetry between cryptocurrencies; Bitcoin has an informational advantage over Ethereum in that the sentiment embedded into transactional data is sufficient to predict its price movement.
Scalable Signature-Based Distribution Regression via Reference Sets
Oct 11, 2024Distribution Regression (DR) on stochastic processes describes the learning task of regression on collections of time series. Path signatures, a technique prevalent in stochastic analysis, have been used to solve the DR problem. Recent works have demonstrated the ability of such solutions to leverage the information encoded in paths via signature-based features. However, current state of the art DR solutions are memory intensive and incur a high computation cost. This leads to a trade-off between path length and the number of paths considered. This computational bottleneck limits the application to small sample sizes which consequently introduces estimation uncertainty. In this paper, we present a methodology for addressing the above issues; resolving estimation uncertainties whilst also proposing a pipeline that enables us to use DR for a wide variety of learning tasks. Integral to our approach is our novel distance approximator. This allows us to seamlessly apply our methodology across different application domains, sampling rates, and stochastic process dimensions. We show that our model performs well in applications related to estimation theory, quantitative finance, and physical sciences. We demonstrate that our model generalises well, not only to unseen data within a given distribution, but also under unseen regimes (unseen classes of stochastic models).
A Financial Time Series Denoiser Based on Diffusion Model
Sep 02, 2024


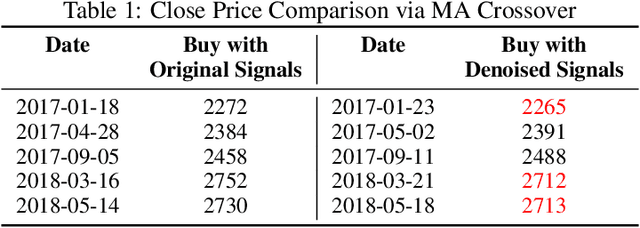
Financial time series often exhibit low signal-to-noise ratio, posing significant challenges for accurate data interpretation and prediction and ultimately decision making. Generative models have gained attention as powerful tools for simulating and predicting intricate data patterns, with the diffusion model emerging as a particularly effective method. This paper introduces a novel approach utilizing the diffusion model as a denoiser for financial time series in order to improve data predictability and trading performance. By leveraging the forward and reverse processes of the conditional diffusion model to add and remove noise progressively, we reconstruct original data from noisy inputs. Our extensive experiments demonstrate that diffusion model-based denoised time series significantly enhance the performance on downstream future return classification tasks. Moreover, trading signals derived from the denoised data yield more profitable trades with fewer transactions, thereby minimizing transaction costs and increasing overall trading efficiency. Finally, we show that by using classifiers trained on denoised time series, we can recognize the noising state of the market and obtain excess return.
Information Loss in Euclidean Preference Models
Aug 17, 2022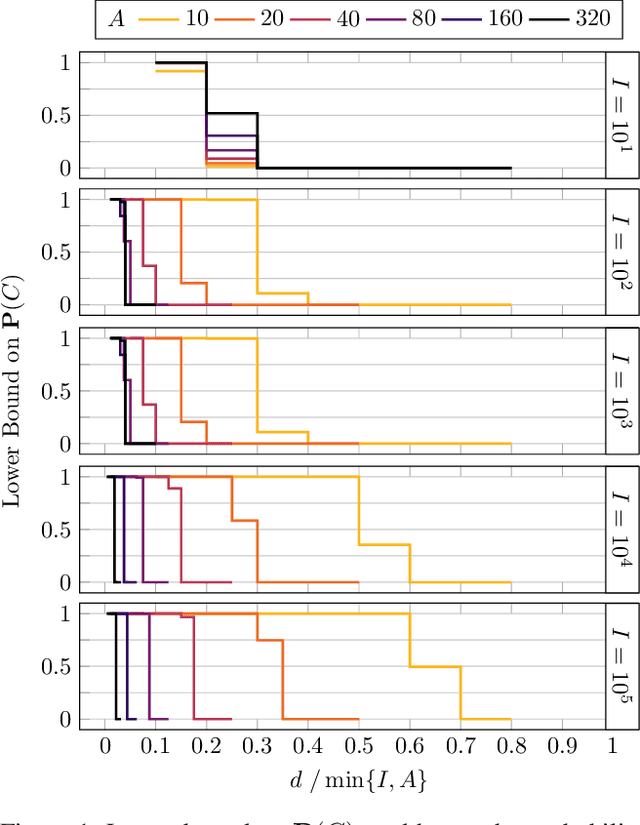
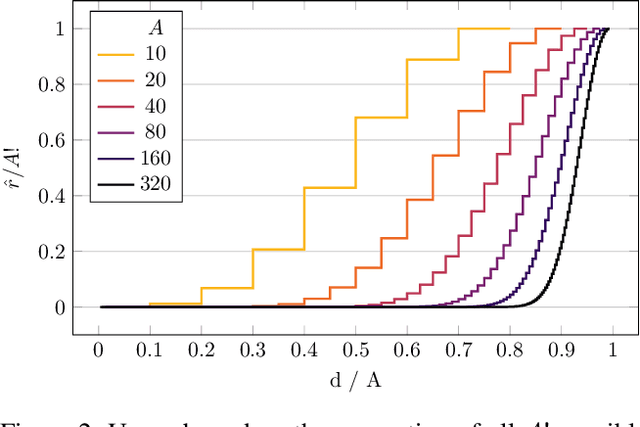
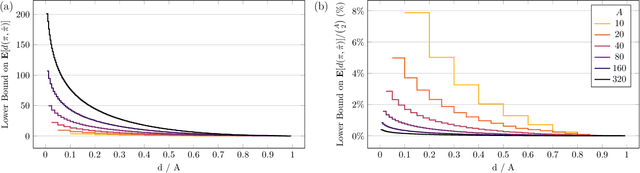
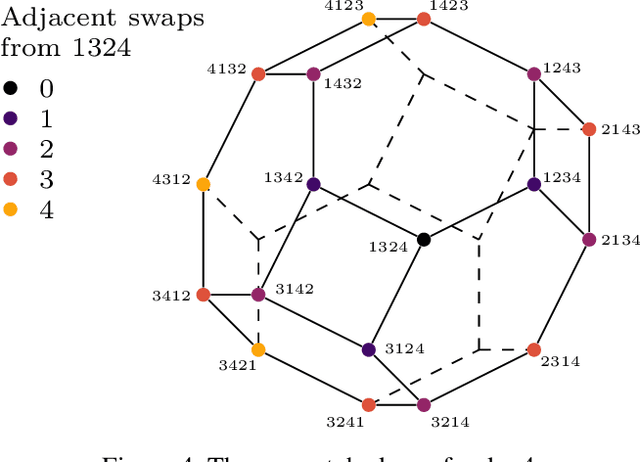
Spatial models of preference, in the form of vector embeddings, are learned by many deep learning systems including recommender systems. Often these models are assumed to approximate a Euclidean structure, where an individual prefers alternatives positioned closer to their "ideal point", as measured by the Euclidean metric. However, Bogomolnaia and Laslier (2007) showed that there exist ordinal preference profiles that cannot be represented with this structure if the Euclidean space has two fewer dimensions than there are individuals or alternatives. We extend this result, showing that there are realistic situations in which almost all preference profiles cannot be represented with the Euclidean model, and derive a theoretical lower bound on the information lost when approximating non-representable preferences with the Euclidean model. Our results have implications for the interpretation and use of vector embeddings, because in some cases close approximation of arbitrary, true preferences is possible only if the dimensionality of the embeddings is a substantial fraction of the number of individuals or alternatives.
Denoised Labels for Financial Time-Series Data via Self-Supervised Learning
Dec 19, 2021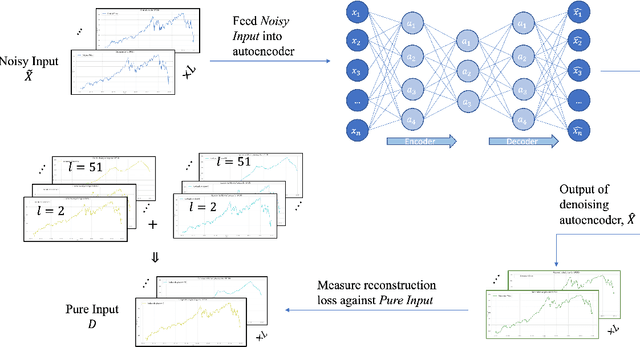
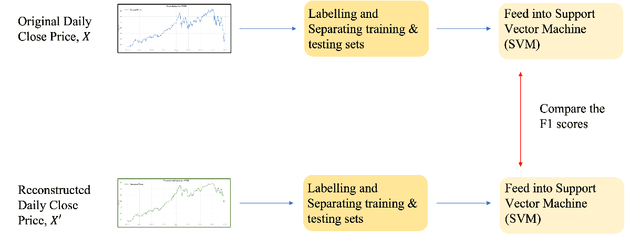

The introduction of electronic trading platforms effectively changed the organisation of traditional systemic trading from quote-driven markets into order-driven markets. Its convenience led to an exponentially increasing amount of financial data, which is however hard to use for the prediction of future prices, due to the low signal-to-noise ratio and the non-stationarity of financial time series. Simpler classification tasks -- where the goal is to predict the directions of future price movement -- via supervised learning algorithms, need sufficiently reliable labels to generalise well. Labelling financial data is however less well defined than other domains: did the price go up because of noise or because of signal? The existing labelling methods have limited countermeasures against noise and limited effects in improving learning algorithms. This work takes inspiration from image classification in trading and success in self-supervised learning. We investigate the idea of applying computer vision techniques to financial time-series to reduce the noise exposure and hence generate correct labels. We look at the label generation as the pretext task of a self-supervised learning approach and compare the naive (and noisy) labels, commonly used in the literature, with the labels generated by a denoising autoencoder for the same downstream classification task. Our results show that our denoised labels improve the performances of the downstream learning algorithm, for both small and large datasets. We further show that the signals we obtain can be used to effectively trade with binary strategies. We suggest that with proposed techniques, self-supervised learning constitutes a powerful framework for generating "better" financial labels that are useful for studying the underlying patterns of the market.
Better Model Selection with a new Definition of Feature Importance
Sep 16, 2020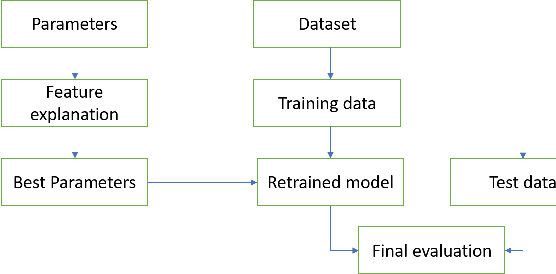
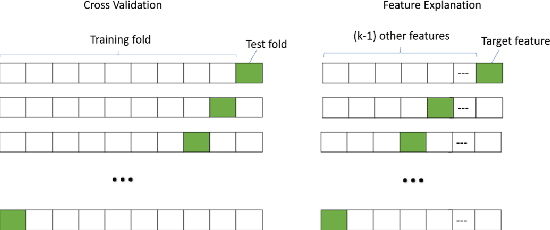
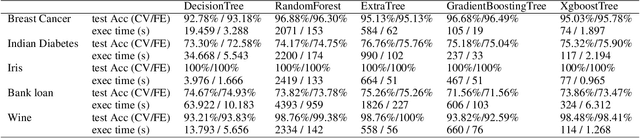
Feature importance aims at measuring how crucial each input feature is for model prediction. It is widely used in feature engineering, model selection and explainable artificial intelligence (XAI). In this paper, we propose a new tree-model explanation approach for model selection. Our novel concept leverages the Coefficient of Variation of a feature weight (measured in terms of the contribution of the feature to the prediction) to capture the dispersion of importance over samples. Extensive experimental results show that our novel feature explanation performs better than general cross validation method in model selection both in terms of time efficiency and accuracy performance.
Ascertaining price formation in cryptocurrency markets with DeepLearning
Feb 09, 2020

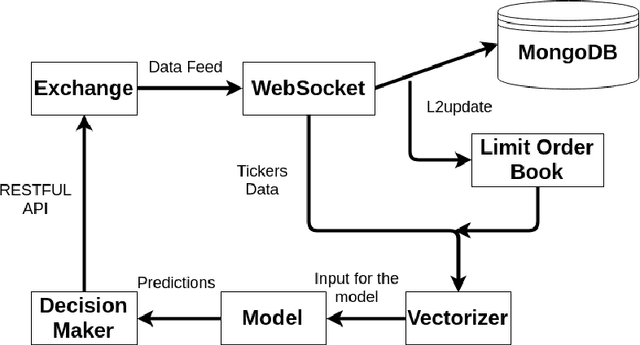
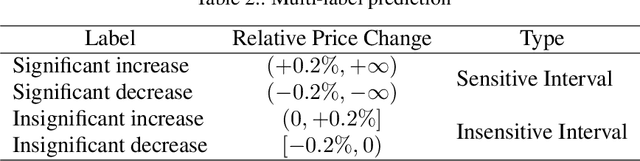
The cryptocurrency market is amongst the fastest-growing of all the financial markets in the world. Unlike traditional markets, such as equities, foreign exchange and commodities, cryptocurrency market is considered to have larger volatility and illiquidity. This paper is inspired by the recent success of using deep learning for stock market prediction. In this work, we analyze and present the characteristics of the cryptocurrency market in a high-frequency setting. In particular, we applied a deep learning approach to predict the direction of the mid-price changes on the upcoming tick. We monitored live tick-level data from $8$ cryptocurrency pairs and applied both statistical and machine learning techniques to provide a live prediction. We reveal that promising results are possible for cryptocurrencies, and in particular, we achieve a consistent $78\%$ accuracy on the prediction of the mid-price movement on live exchange rate of Bitcoins vs US dollars.