 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPO: Towards Accurate GUI Agent Interaction via Location Preference Optimization
Jun 11, 2025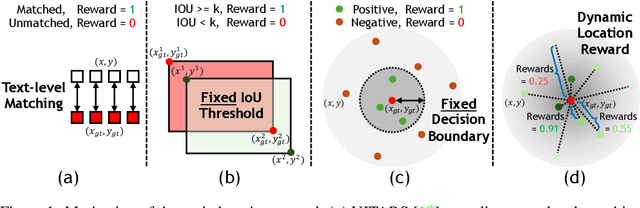
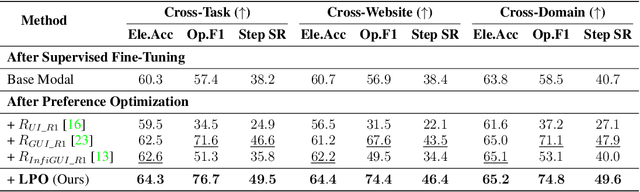
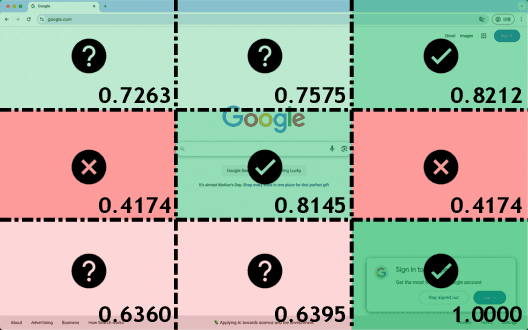
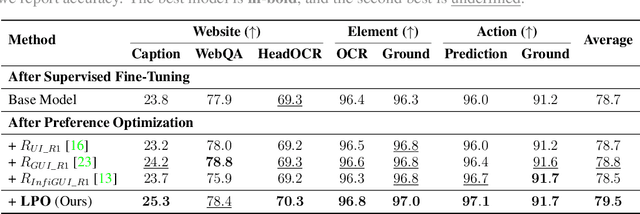
The advent of autonomous agents is transforming interactions with Graphical User Interfaces (GUIs) by employing natural language as a powerful intermediary. Despite the predominance of Supervised Fine-Tuning (SFT) methods in current GUI agents for achieving spatial localization, these methods face substantial challenges due to their limited capacity to accurately perceive positional data. Existing strategies, such as reinforcement learning, often fail to assess positional accuracy effectively, thereby restricting their utility. In response, we introduce Location Preference Optimization (LPO), a novel approach that leverages locational data to optimize interaction preferences. LPO uses information entropy to predict interaction positions by focusing on zones rich in information. Besides, it further introduces a dynamic location reward function based on physical distance, reflecting the varying importance of interaction positions. Supported by Group Relative Preference Optimization (GRPO), LPO facilitates an extensive exploration of GUI environments and significantly enhances interaction precision. Comprehensive experiments demonstrate LPO's superior performance, achieving SOTA results across both offline benchmarks and real-world online evaluations. Our code will be made publicly available soon, at https://github.com/AIDC-AI/LPO.
Wings: Learning Multimodal LLMs without Text-only Forgetting
Jun 05, 2024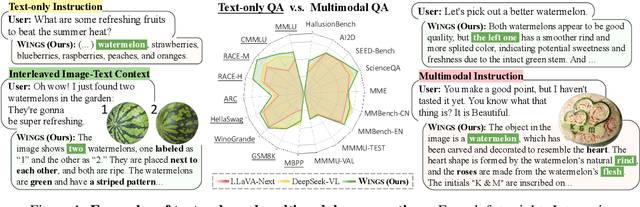
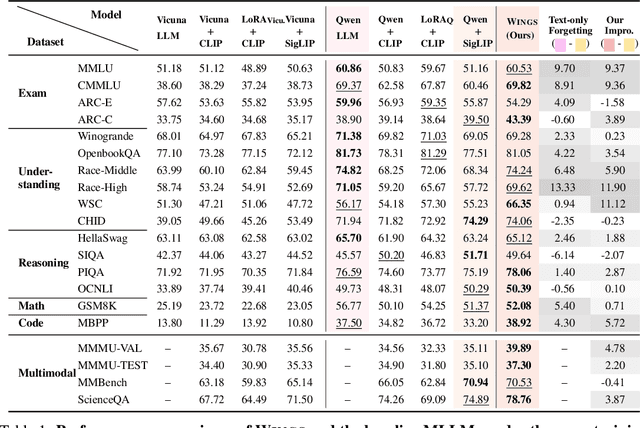
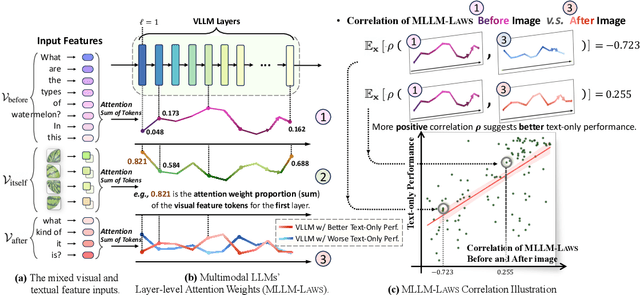
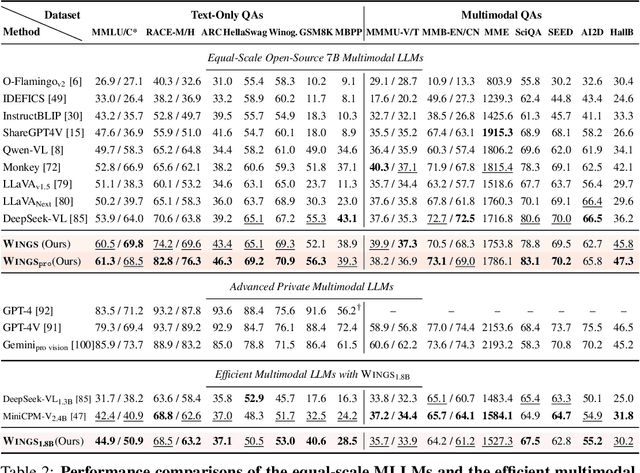
Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, the MLLM catastrophically forgets the text-only instructions, which do not include images and can be addressed within the initial LLM. In this paper, we present Wings, a novel MLLM that excels in both text-only dialogues and multimodal comprehension. Analyzing MLLM attention in multimodal instructions reveals that text-only forgetting is related to the attention shifts from pre-image to post-image text. From that, we construct extra modules that act as the boosted learner to compensate for the attention shift. The complementary visual and textual learners, like "wings" on either side, are connected in parallel within each layer's attention block. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Textual learners are later collaboratively integrated with attention-based routing to blend the outputs of the visual and textual learners. We design the Low-Rank Residual Attention (LoRRA) to guarantee high efficiency for learners. Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. On a newly constructed Interleaved Image-Text (IIT) benchmark, Wings exhibits superior performance from text-only-rich to multimodal-rich question-answering tasks.
Denoised Labels for Financial Time-Series Data via Self-Supervised Learning
Dec 19, 2021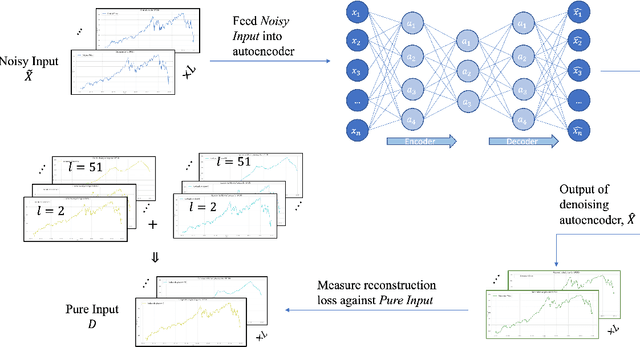
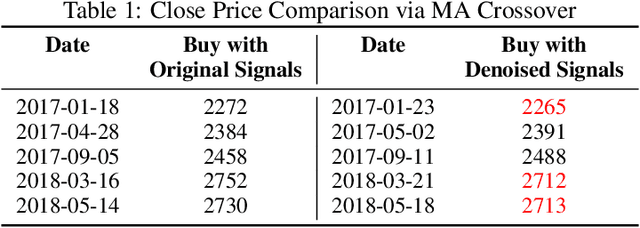
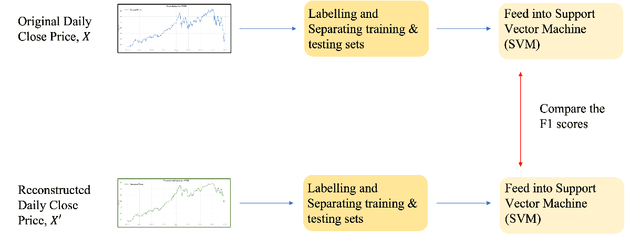

The introduction of electronic trading platforms effectively changed the organisation of traditional systemic trading from quote-driven markets into order-driven markets. Its convenience led to an exponentially increasing amount of financial data, which is however hard to use for the prediction of future prices, due to the low signal-to-noise ratio and the non-stationarity of financial time series. Simpler classification tasks -- where the goal is to predict the directions of future price movement -- via supervised learning algorithms, need sufficiently reliable labels to generalise well. Labelling financial data is however less well defined than other domains: did the price go up because of noise or because of signal? The existing labelling methods have limited countermeasures against noise and limited effects in improving learning algorithms. This work takes inspiration from image classification in trading and success in self-supervised learning. We investigate the idea of applying computer vision techniques to financial time-series to reduce the noise exposure and hence generate correct labels. We look at the label generation as the pretext task of a self-supervised learning approach and compare the naive (and noisy) labels, commonly used in the literature, with the labels generated by a denoising autoencoder for the same downstream classification task. Our results show that our denoised labels improve the performances of the downstream learning algorithm, for both small and large datasets. We further show that the signals we obtain can be used to effectively trade with binary strategies. We suggest that with proposed techniques, self-supervised learning constitutes a powerful framework for generating "better" financial labels that are useful for studying the underlying patterns of the market.