 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWings: Learning Multimodal LLMs without Text-only Forgetting
Paper and Code
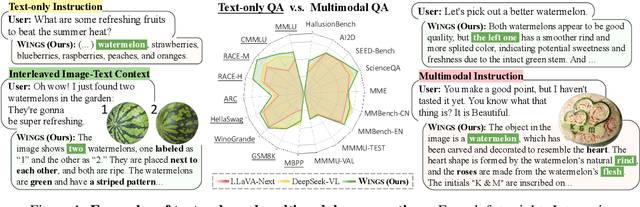
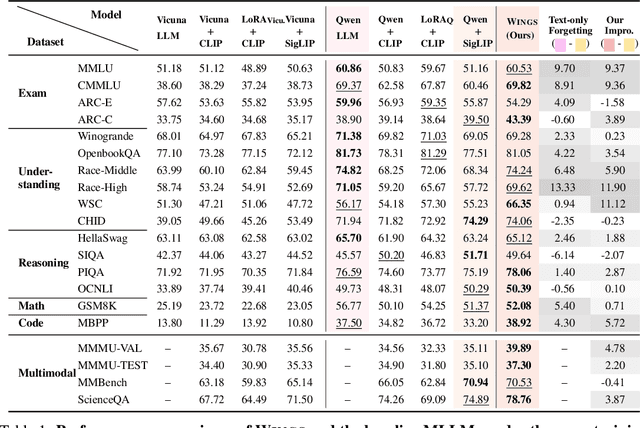
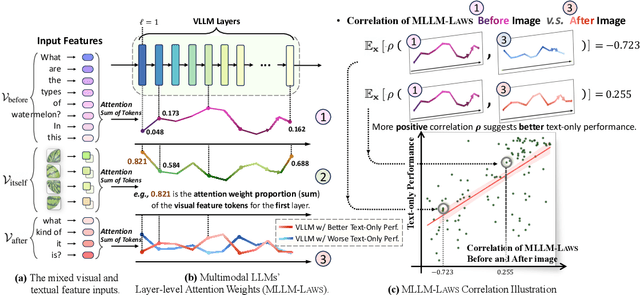
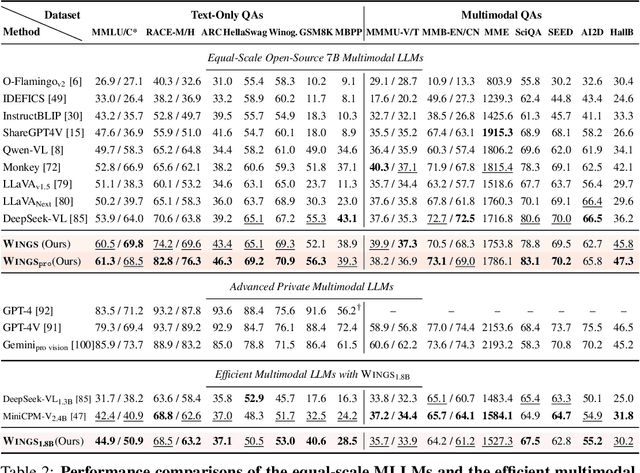
Multimodal large language models (MLLMs), initiated with a trained LLM, first align images with text and then fine-tune on multimodal mixed inputs. However, the MLLM catastrophically forgets the text-only instructions, which do not include images and can be addressed within the initial LLM. In this paper, we present Wings, a novel MLLM that excels in both text-only dialogues and multimodal comprehension. Analyzing MLLM attention in multimodal instructions reveals that text-only forgetting is related to the attention shifts from pre-image to post-image text. From that, we construct extra modules that act as the boosted learner to compensate for the attention shift. The complementary visual and textual learners, like "wings" on either side, are connected in parallel within each layer's attention block. Initially, image and text inputs are aligned with visual learners operating alongside the main attention, balancing focus on visual elements. Textual learners are later collaboratively integrated with attention-based routing to blend the outputs of the visual and textual learners. We design the Low-Rank Residual Attention (LoRRA) to guarantee high efficiency for learners. Our experimental results demonstrate that Wings outperforms equally-scaled MLLMs in both text-only and visual question-answering tasks. On a newly constructed Interleaved Image-Text (IIT) benchmark, Wings exhibits superior performance from text-only-rich to multimodal-rich question-answering tasks.