 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBRICKS-WM: Building Reusability via Interface Composition Kinetics for Structured World Models
Jun 15, 2026Model-based Reinforcement Learning (MBRL) has achieved remarkable success in continuous control by leveraging latent world models. However, prevailing approaches typically rely on monolithic latent dynamics, entangling environment dynamics into a coupled process. This coupling severely limits reusability: altering the agent necessitates retraining the entire world from scratch, even if the environment remains constant. To address this, we introduce BRICKS-WM (Building Reusability via Interface Composition Kinetics for Structured World Models), a framework for the modular assembly of structured world models. Driven by the insight that the physical world is composed of independent entities, we posit that global dynamics can be modeled as a composition of distinct dynamical modules interacting via latent interfaces. As a minimal instantiation, we factorize the latent state space into an actuated Agent module and an external Background module, bridged by a learned latent interface. Unlike prior object-centric methods that prioritize visual segmentation, BRICKS-WM enforces a functional separation in transition dynamics, ensuring that background dynamics remains agnostic to the agent's dynamics. Empirically, BRICKS-WM achieves control performance comparable to strong monolithic baselines when trained from scratch, and enables the reuse of frozen background dynamics across agents.
Polaris: Scaling Up Instruction-Guided Image Generation Towards Millions of Personalized Style Needs
Jun 01, 2026Users increasingly expect image generation models to quickly adapt to highly diverse and personalized requirements, such as producing images with distinctive styles or characteristics. Traditional approaches rely on fine-tuning, which is costly and difficult to scale. To cope with these limitations, the community has accumulated a growing library of fine-tuned modules and adapters, where each component targets specific generation needs and collectively serves as a foundation for handling new demands. This naturally raises a question: instead of repeatedly training new models, can we systematically exploit this expanding ecosystem to better fulfill user instructions? To this end, we present Polaris, an intelligent retrieval framework that automatically selects and integrates suitable models from the model library based on a user's instructions. The key insight is that harnessing such a massive and heterogeneous pool requires not only finding the most relevant modules among thousands of candidates, but also aligning them effectively for instruction-driven generation and editing. Polaris addresses this challenge by indexing over 6,500 checkpoints and 75,000 adapters, and retrieving the most relevant components given a user's input and instruction. In doing so, it delivers scalable, controllable, and well-aligned generation -- without any additional training.
$V_{0.5}$: Generalist Value Model as a Prior for Sparse RL Rollouts
Mar 11, 2026In Reinforcement Learning with Verifiable Rewards (RLVR), constructing a robust advantage baseline is critical for policy gradients, effectively guiding the policy model to reinforce desired behaviors. Recent research has introduced Generalist Value Models (such as $V_0$), which achieve pre-trained value estimation by explicitly encoding model capabilities in-context, eliminating the need to synchronously update the value model alongside the policy model. In this paper, we propose $V_{0.5}$, which adaptively fuses the baseline predicted by such value model (acting as a prior) with the empirical mean derived from sparse rollouts. This constructs a robust baseline that balances computational efficiency with extremely low variance. Specifically, we introduce a real-time statistical testing and dynamic budget allocation. This balances the high variance caused by sparse sampling against the systematic bias (or hallucinations) inherent in the value model's prior. By constructing a hypothesis test to evaluate the prior's reliability in real-time, the system dynamically allocates additional rollout budget on demand. This mechanism minimizes the baseline estimator's Mean Squared Error (MSE), guaranteeing stable policy gradients, even under extreme sparsity with a group size of 4. Extensive evaluations across six mathematical reasoning benchmarks demonstrate that $V_{0.5}$ significantly outperforms GRPO and DAPO, achieving faster convergence and over some 10% performance improvement.
$V_0$: A Generalist Value Model for Any Policy at State Zero
Feb 03, 2026Policy gradient methods rely on a baseline to measure the relative advantage of an action, ensuring the model reinforces behaviors that outperform its current average capability. In the training of Large Language Models (LLMs) using Actor-Critic methods (e.g., PPO), this baseline is typically estimated by a Value Model (Critic) often as large as the policy model itself. However, as the policy continuously evolves, the value model requires expensive, synchronous incremental training to accurately track the shifting capabilities of the policy. To avoid this overhead, Group Relative Policy Optimization (GRPO) eliminates the coupled value model by using the average reward of a group of rollouts as the baseline; yet, this approach necessitates extensive sampling to maintain estimation stability. In this paper, we propose $V_0$, a Generalist Value Model capable of estimating the expected performance of any model on unseen prompts without requiring parameter updates. We reframe value estimation by treating the policy's dynamic capability as an explicit context input; specifically, we leverage a history of instruction-performance pairs to dynamically profile the model, departing from the traditional paradigm that relies on parameter fitting to perceive capability shifts. Focusing on value estimation at State Zero (i.e., the initial prompt, hence $V_0$), our model serves as a critical resource scheduler. During GRPO training, $V_0$ predicts success rates prior to rollout, allowing for efficient sampling budget allocation; during deployment, it functions as a router, dispatching instructions to the most cost-effective and suitable model. Empirical results demonstrate that $V_0$ significantly outperforms heuristic budget allocation and achieves a Pareto-optimal trade-off between performance and cost in LLM routing tasks.
SAME: Stabilized Mixture-of-Experts for Multimodal Continual Instruction Tuning
Feb 02, 2026Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, but real-world deployment requires them to continually expand their capabilities, making Multimodal Continual Instruction Tuning (MCIT) essential. Recent methods leverage sparse expert routing to promote task specialization, but we find that the expert routing process suffers from drift as the data distribution evolves. For example, a grounding query that previously activated localization experts may instead be routed to irrelevant experts after learning OCR tasks. Meanwhile, the grounding-related experts can be overwritten by new tasks and lose their original functionality. Such failure reflects two problems: router drift, where expert selection becomes inconsistent over time, and expert drift, where shared experts are overwritten across tasks. Therefore, we propose StAbilized Mixture-of-Experts (SAME) for MCIT. To address router drift, SAME stabilizes expert selection by decomposing routing dynamics into orthogonal subspaces and updating only task-relevant directions. To mitigate expert drift, we regulate expert updates via curvature-aware scaling using historical input covariance in a rehearsal-free manner. SAME also introduces adaptive expert activation to freeze selected experts during training, reducing redundant computation and cross-task interference. Extensive experiments demonstrate its SOTA performance.
BOFA: Bridge-Layer Orthogonal Low-Rank Fusion for CLIP-Based Class-Incremental Learning
Nov 14, 2025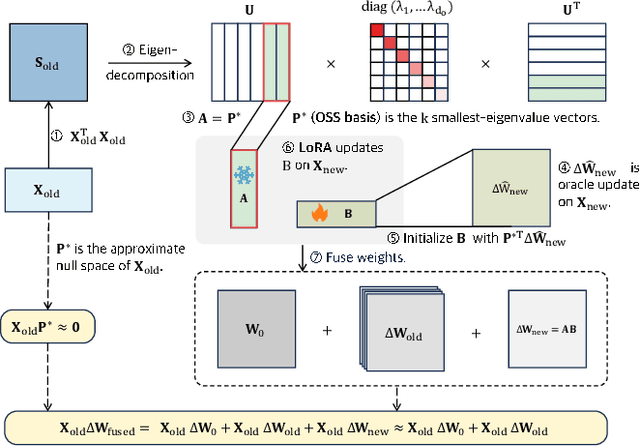
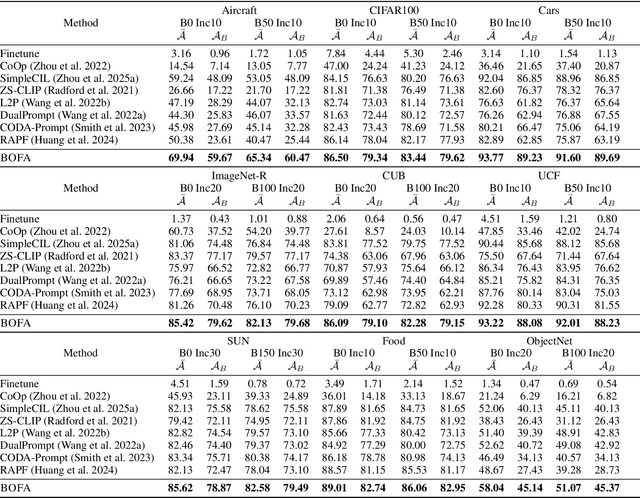
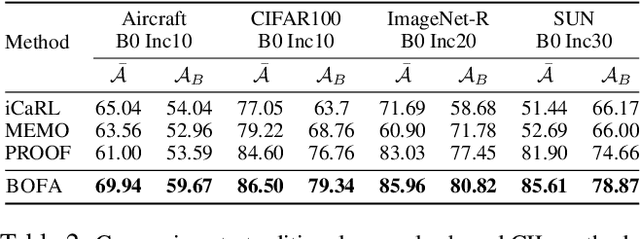
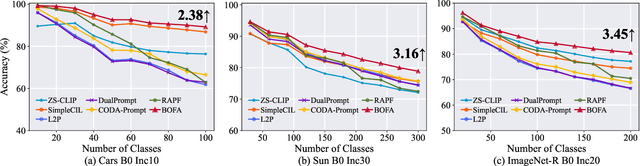
Class-Incremental Learning (CIL) aims to continually learn new categories without forgetting previously acquired knowledge. Vision-language models such as CLIP offer strong transferable representations via multi-modal supervision, making them promising for CIL. However, applying CLIP to CIL poses two major challenges: (1) adapting to downstream tasks often requires additional learnable modules, increasing model complexity and susceptibility to forgetting; and (2) while multi-modal representations offer complementary strengths, existing methods have yet to fully realize their potential in effectively integrating visual and textual modalities. To address these issues, we propose BOFA (Bridge-layer Orthogonal Fusion for Adaptation), a novel framework for CIL. BOFA confines all model adaptation exclusively to CLIP's existing cross-modal bridge-layer, thereby adding no extra parameters or inference cost. To prevent forgetting within this layer, it leverages Orthogonal Low-Rank Fusion, a mechanism that constrains parameter updates to a low-rank ``safe subspace" mathematically constructed to be orthogonal to past task features. This ensures stable knowledge accumulation without data replay. Furthermore, BOFA employs a cross-modal hybrid prototype that synergizes stable textual prototypes with visual counterparts derived from our stably adapted bridge-layer, enhancing classification performance. Extensive experiments on standard benchmarks show that BOFA achieves superior accuracy and efficiency compared to existing methods.
Co-Evolving Latent Action World Models
Oct 30, 2025Adapting pre-trained video generation models into controllable world models via latent actions is a promising step towards creating generalist world models. The dominant paradigm adopts a two-stage approach that trains latent action model (LAM) and the world model separately, resulting in redundant training and limiting their potential for co-adaptation. A conceptually simple and appealing idea is to directly replace the forward dynamic model in LAM with a powerful world model and training them jointly, but it is non-trivial and prone to representational collapse. In this work, we propose CoLA-World, which for the first time successfully realizes this synergistic paradigm, resolving the core challenge in joint learning through a critical warm-up phase that effectively aligns the representations of the from-scratch LAM with the pre-trained world model. This unlocks a co-evolution cycle: the world model acts as a knowledgeable tutor, providing gradients to shape a high-quality LAM, while the LAM offers a more precise and adaptable control interface to the world model. Empirically, CoLA-World matches or outperforms prior two-stage methods in both video simulation quality and downstream visual planning, establishing a robust and efficient new paradigm for the field.
Hawk: Leveraging Spatial Context for Faster Autoregressive Text-to-Image Generation
Oct 29, 2025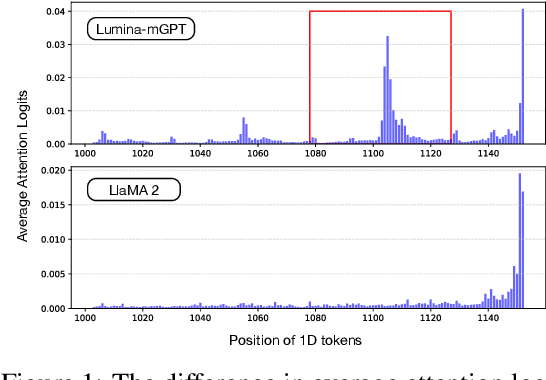



Autoregressive (AR) image generation models are capable of producing high-fidelity images but often suffer from slow inference due to their inherently sequential, token-by-token decoding process. Speculative decoding, which employs a lightweight draft model to approximate the output of a larger AR model, has shown promise in accelerating text generation without compromising quality. However, its application to image generation remains largely underexplored. The challenges stem from a significantly larger sampling space, which complicates the alignment between the draft and target model outputs, coupled with the inadequate use of the two-dimensional spatial structure inherent in images, thereby limiting the modeling of local dependencies. To overcome these challenges, we introduce Hawk, a new approach that harnesses the spatial structure of images to guide the speculative model toward more accurate and efficient predictions. Experimental results on multiple text-to-image benchmarks demonstrate a 1.71x speedup over standard AR models, while preserving both image fidelity and diversity.
Hierarchical Representation Matching for CLIP-based Class-Incremental Learning
Sep 26, 2025Class-Incremental Learning (CIL) aims to endow models with the ability to continuously adapt to evolving data streams. Recent advances in pre-trained vision-language models (e.g., CLIP) provide a powerful foundation for this task. However, existing approaches often rely on simplistic templates, such as "a photo of a [CLASS]", which overlook the hierarchical nature of visual concepts. For example, recognizing "cat" versus "car" depends on coarse-grained cues, while distinguishing "cat" from "lion" requires fine-grained details. Similarly, the current feature mapping in CLIP relies solely on the representation from the last layer, neglecting the hierarchical information contained in earlier layers. In this work, we introduce HiErarchical Representation MAtchiNg (HERMAN) for CLIP-based CIL. Our approach leverages LLMs to recursively generate discriminative textual descriptors, thereby augmenting the semantic space with explicit hierarchical cues. These descriptors are matched to different levels of the semantic hierarchy and adaptively routed based on task-specific requirements, enabling precise discrimination while alleviating catastrophic forgetting in incremental tasks. Extensive experiments on multiple benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
One-Embedding-Fits-All: Efficient Zero-Shot Time Series Forecasting by a Model Zoo
Sep 04, 2025The proliferation of Time Series Foundation Models (TSFMs) has significantly advanced zero-shot forecasting, enabling predictions for unseen time series without task-specific fine-tuning. Extensive research has confirmed that no single TSFM excels universally, as different models exhibit preferences for distinct temporal patterns. This diversity suggests an opportunity: how to take advantage of the complementary abilities of TSFMs. To this end, we propose ZooCast, which characterizes each model's distinct forecasting strengths. ZooCast can intelligently assemble current TSFMs into a model zoo that dynamically selects optimal models for different forecasting tasks. Our key innovation lies in the One-Embedding-Fits-All paradigm that constructs a unified representation space where each model in the zoo is represented by a single embedding, enabling efficient similarity matching for all tasks. Experiments demonstrate ZooCast's strong performance on the GIFT-Eval zero-shot forecasting benchmark while maintaining the efficiency of a single TSFM. In real-world scenarios with sequential model releases, the framework seamlessly adds new models for progressive accuracy gains with negligible overhead.