 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Models in Deep Reinforcement Learning: A Survey
Jun 18, 2025In reinforcement learning (RL), agents continually interact with the environment and use the feedback to refine their behavior. To guide policy optimization, reward models are introduced as proxies of the desired objectives, such that when the agent maximizes the accumulated reward, it also fulfills the task designer's intentions. Recently, significant attention from both academic and industrial researchers has focused on developing reward models that not only align closely with the true objectives but also facilitate policy optimization. In this survey, we provide a comprehensive review of reward modeling techniques within the deep RL literature. We begin by outlining the background and preliminaries in reward modeling. Next, we present an overview of recent reward modeling approaches, categorizing them based on the source, the mechanism, and the learning paradigm. Building on this understanding, we discuss various applications of these reward modeling techniques and review methods for evaluating reward models. Finally, we conclude by highlighting promising research directions in reward modeling. Altogether, this survey includes both established and emerging methods, filling the vacancy of a systematic review of reward models in current literature.
MOS: Model Surgery for Pre-Trained Model-Based Class-Incremental Learning
Dec 12, 2024Class-Incremental Learning (CIL) requires models to continually acquire knowledge of new classes without forgetting old ones. Despite Pre-trained Models (PTMs) have shown excellent performance in CIL, catastrophic forgetting still occurs as the model learns new concepts. Existing work seeks to utilize lightweight components to adjust the PTM, while the forgetting phenomenon still comes from {\em parameter and retrieval} levels. Specifically, iterative updates of the model result in parameter drift, while mistakenly retrieving irrelevant modules leads to the mismatch during inference. To this end, we propose MOdel Surgery (MOS) to rescue the model from forgetting previous knowledge. By training task-specific adapters, we continually adjust the PTM to downstream tasks. To mitigate parameter-level forgetting, we present an adapter merging approach to learn task-specific adapters, which aims to bridge the gap between different components while reserve task-specific information. Besides, to address retrieval-level forgetting, we introduce a training-free self-refined adapter retrieval mechanism during inference, which leverages the model's inherent ability for better adapter retrieval. By jointly rectifying the model with those steps, MOS can robustly resist catastrophic forgetting in the learning process. Extensive experiments on seven benchmark datasets validate MOS's state-of-the-art performance. Code is available at: https://github.com/sun-hailong/AAAI25-MOS
Weight Scope Alignment: A Frustratingly Easy Method for Model Merging
Aug 22, 2024



Merging models becomes a fundamental procedure in some applications that consider model efficiency and robustness. The training randomness or Non-I.I.D. data poses a huge challenge for averaging-based model fusion. Previous research efforts focus on element-wise regularization or neural permutations to enhance model averaging while overlooking weight scope variations among models, which can significantly affect merging effectiveness. In this paper, we reveal variations in weight scope under different training conditions, shedding light on its influence on model merging. Fortunately, the parameters in each layer basically follow the Gaussian distribution, which inspires a novel and simple regularization approach named Weight Scope Alignment (WSA). It contains two key components: 1) leveraging a target weight scope to guide the model training process for ensuring weight scope matching in the subsequent model merging. 2) fusing the weight scope of two or more models into a unified one for multi-stage model fusion. We extend the WSA regularization to two different scenarios, including Mode Connectivity and Federated Learning. Abundant experimental studies validate the effectiveness of our approach.
SeMOPO: Learning High-quality Model and Policy from Low-quality Offline Visual Datasets
Jun 13, 2024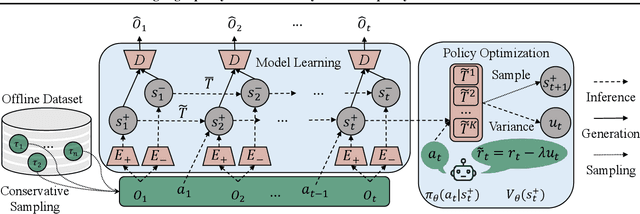
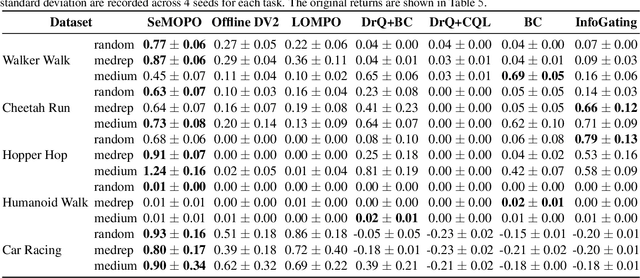
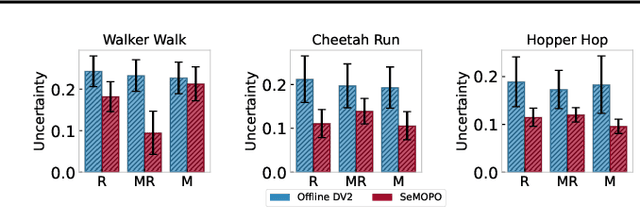
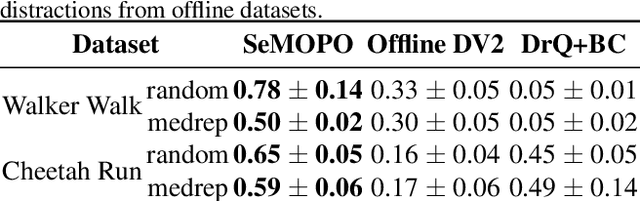
Model-based offline reinforcement Learning (RL) is a promising approach that leverages existing data effectively in many real-world applications, especially those involving high-dimensional inputs like images and videos. To alleviate the distribution shift issue in offline RL, existing model-based methods heavily rely on the uncertainty of learned dynamics. However, the model uncertainty estimation becomes significantly biased when observations contain complex distractors with non-trivial dynamics. To address this challenge, we propose a new approach - \emph{Separated Model-based Offline Policy Optimization} (SeMOPO) - decomposing latent states into endogenous and exogenous parts via conservative sampling and estimating model uncertainty on the endogenous states only. We provide a theoretical guarantee of model uncertainty and performance bound of SeMOPO. To assess the efficacy, we construct the Low-Quality Vision Deep Data-Driven Datasets for RL (LQV-D4RL), where the data are collected by non-expert policy and the observations include moving distractors. Experimental results show that our method substantially outperforms all baseline methods, and further analytical experiments validate the critical designs in our method. The project website is \href{https://sites.google.com/view/semopo}{https://sites.google.com/view/semopo}.
Exploring Dark Knowledge under Various Teacher Capacities and Addressing Capacity Mismatch
May 21, 2024Knowledge Distillation (KD) could transfer the ``dark knowledge" of a well-performed yet large neural network to a weaker but lightweight one. From the view of output logits and softened probabilities, this paper goes deeper into the dark knowledge provided by teachers with different capacities. Two fundamental observations are: (1) a larger teacher tends to produce probability vectors that are less distinct between non-ground-truth classes; (2) teachers with different capacities are basically consistent in their cognition of relative class affinity. Abundant experimental studies verify these observations and in-depth empirical explanations are provided. The difference in dark knowledge leads to the peculiar phenomenon named ``capacity mismatch" that a more accurate teacher does not necessarily perform as well as a smaller teacher when teaching the same student network. Enlarging the distinctness between non-ground-truth class probabilities for larger teachers could address the capacity mismatch problem. This paper explores multiple simple yet effective ways to achieve this goal and verify their success by comparing them with popular KD methods that solve the capacity mismatch.
DIDA: Denoised Imitation Learning based on Domain Adaptation
Apr 04, 2024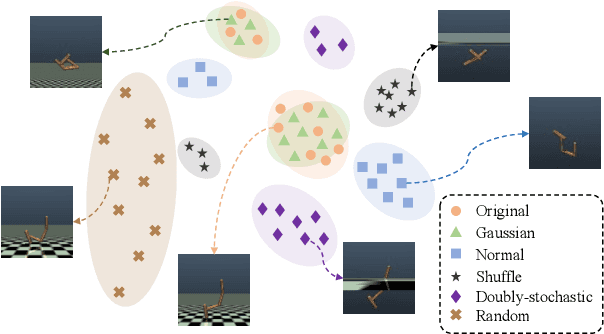
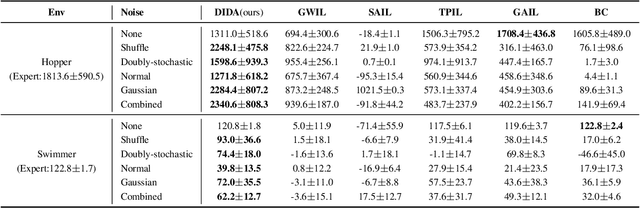
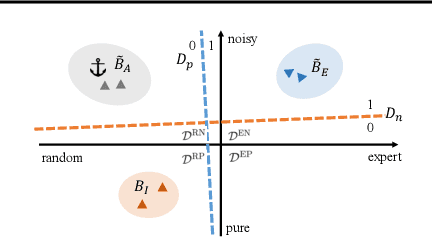

Imitating skills from low-quality datasets, such as sub-optimal demonstrations and observations with distractors, is common in real-world applications. In this work, we focus on the problem of Learning from Noisy Demonstrations (LND), where the imitator is required to learn from data with noise that often occurs during the processes of data collection or transmission. Previous IL methods improve the robustness of learned policies by injecting an adversarially learned Gaussian noise into pure expert data or utilizing additional ranking information, but they may fail in the LND setting. To alleviate the above problems, we propose Denoised Imitation learning based on Domain Adaptation (DIDA), which designs two discriminators to distinguish the noise level and expertise level of data, facilitating a feature encoder to learn task-related but domain-agnostic representations. Experiment results on MuJoCo demonstrate that DIDA can successfully handle challenging imitation tasks from demonstrations with various types of noise, outperforming most baseline methods.
SENSOR: Imitate Third-Person Expert's Behaviors via Active Sensoring
Apr 04, 2024
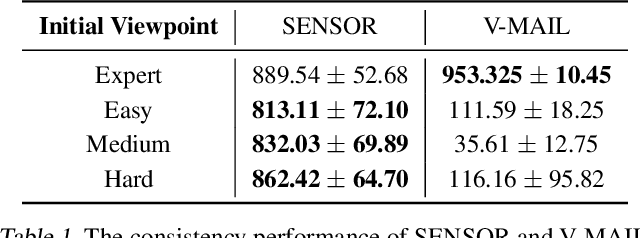


In many real-world visual Imitation Learning (IL) scenarios, there is a misalignment between the agent's and the expert's perspectives, which might lead to the failure of imitation. Previous methods have generally solved this problem by domain alignment, which incurs extra computation and storage costs, and these methods fail to handle the \textit{hard cases} where the viewpoint gap is too large. To alleviate the above problems, we introduce active sensoring in the visual IL setting and propose a model-based SENSory imitatOR (SENSOR) to automatically change the agent's perspective to match the expert's. SENSOR jointly learns a world model to capture the dynamics of latent states, a sensor policy to control the camera, and a motor policy to control the agent. Experiments on visual locomotion tasks show that SENSOR can efficiently simulate the expert's perspective and strategy, and outperforms most baseline methods.
AD3: Implicit Action is the Key for World Models to Distinguish the Diverse Visual Distractors
Mar 15, 2024Model-based methods have significantly contributed to distinguishing task-irrelevant distractors for visual control. However, prior research has primarily focused on heterogeneous distractors like noisy background videos, leaving homogeneous distractors that closely resemble controllable agents largely unexplored, which poses significant challenges to existing methods. To tackle this problem, we propose Implicit Action Generator (IAG) to learn the implicit actions of visual distractors, and present a new algorithm named implicit Action-informed Diverse visual Distractors Distinguisher (AD3), that leverages the action inferred by IAG to train separated world models. Implicit actions effectively capture the behavior of background distractors, aiding in distinguishing the task-irrelevant components, and the agent can optimize the policy within the task-relevant state space. Our method achieves superior performance on various visual control tasks featuring both heterogeneous and homogeneous distractors. The indispensable role of implicit actions learned by IAG is also empirically validated.
Beyond Probability Partitions: Calibrating Neural Networks with Semantic Aware Grouping
Jun 08, 2023Research has shown that deep networks tend to be overly optimistic about their predictions, leading to an underestimation of prediction errors. Due to the limited nature of data, existing studies have proposed various methods based on model prediction probabilities to bin the data and evaluate calibration error. We propose a more generalized definition of calibration error called Partitioned Calibration Error (PCE), revealing that the key difference among these calibration error metrics lies in how the data space is partitioned. We put forth an intuitive proposition that an accurate model should be calibrated across any partition, suggesting that the input space partitioning can extend beyond just the partitioning of prediction probabilities, and include partitions directly related to the input. Through semantic-related partitioning functions, we demonstrate that the relationship between model accuracy and calibration lies in the granularity of the partitioning function. This highlights the importance of partitioning criteria for training a calibrated and accurate model. To validate the aforementioned analysis, we propose a method that involves jointly learning a semantic aware grouping function based on deep model features and logits to partition the data space into subsets. Subsequently, a separate calibration function is learned for each subset. Experimental results demonstrate that our approach achieves significant performance improvements across multiple datasets and network architectures, thus highlighting the importance of the partitioning function for calibration.
Avoid Overfitting User Specific Information in Federated Keyword Spotting
Jun 17, 2022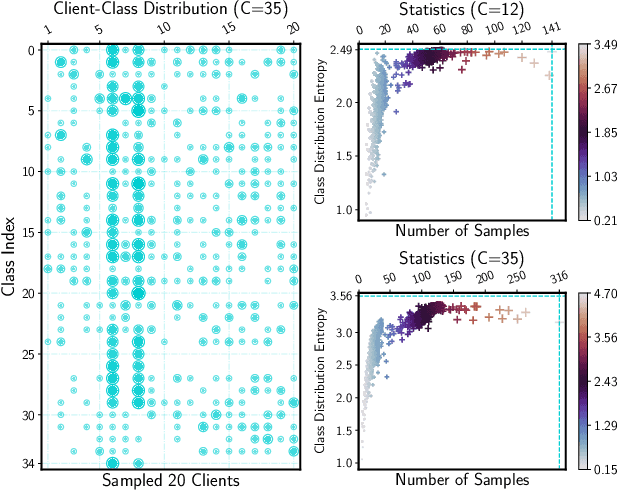
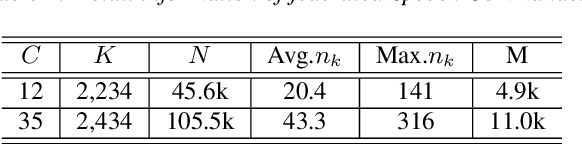
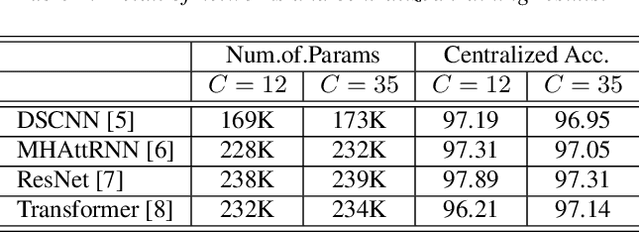
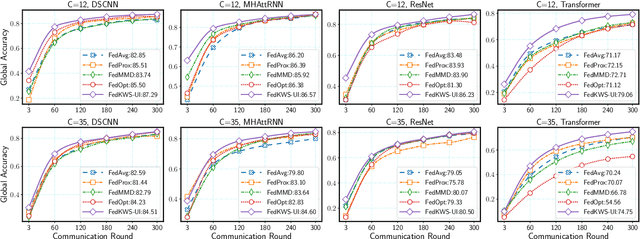
Keyword spotting (KWS) aims to discriminate a specific wake-up word from other signals precisely and efficiently for different users. Recent works utilize various deep networks to train KWS models with all users' speech data centralized without considering data privacy. Federated KWS (FedKWS) could serve as a solution without directly sharing users' data. However, the small amount of data, different user habits, and various accents could lead to fatal problems, e.g., overfitting or weight divergence. Hence, we propose several strategies to encourage the model not to overfit user-specific information in FedKWS. Specifically, we first propose an adversarial learning strategy, which updates the downloaded global model against an overfitted local model and explicitly encourages the global model to capture user-invariant information. Furthermore, we propose an adaptive local training strategy, letting clients with more training data and more uniform class distributions undertake more local update steps. Equivalently, this strategy could weaken the negative impacts of those users whose data is less qualified. Our proposed FedKWS-UI could explicitly and implicitly learn user-invariant information in FedKWS. Abundant experimental results on federated Google Speech Commands verify the effectiveness of FedKWS-UI.