 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025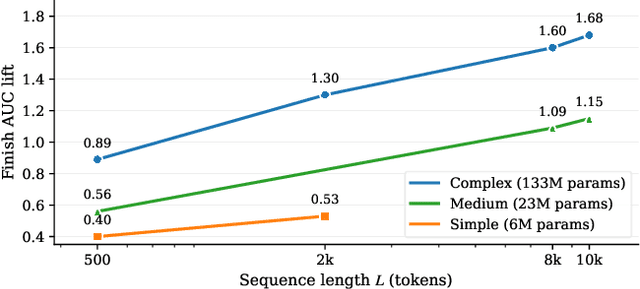
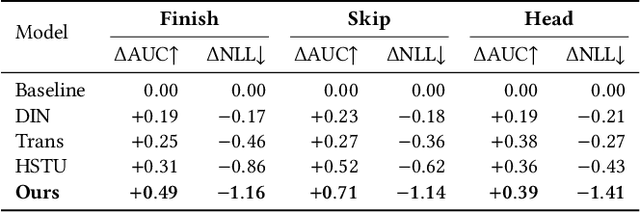
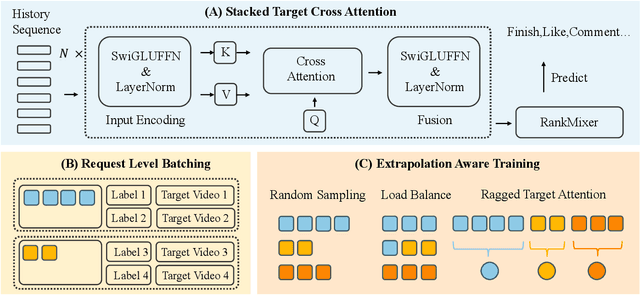

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
Learning Operators by Regularized Stochastic Gradient Descent with Operator-valued Kernels
Apr 25, 2025This paper investigates regularized stochastic gradient descent (SGD) algorithms for estimating nonlinear operators from a Polish space to a separable Hilbert space. We assume that the regression operator lies in a vector-valued reproducing kernel Hilbert space induced by an operator-valued kernel. Two significant settings are considered: an online setting with polynomially decaying step sizes and regularization parameters, and a finite-horizon setting with constant step sizes and regularization parameters. We introduce regularity conditions on the structure and smoothness of the target operator and the input random variables. Under these conditions, we provide a dimension-free convergence analysis for the prediction and estimation errors, deriving both expectation and high-probability error bounds. Our analysis demonstrates that these convergence rates are nearly optimal. Furthermore, we present a new technique for deriving bounds with high probability for general SGD schemes, which also ensures almost-sure convergence. Finally, we discuss potential extensions to more general operator-valued kernels and the encoder-decoder framework.
Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens
Jun 12, 2024



Characterizing users and items through vector representations is crucial for various tasks in recommender systems. Recent approaches attempt to apply Large Language Models (LLMs) in recommendation through a question and answer format, where real users and items (e.g., Item No.2024) are represented with in-vocabulary tokens (e.g., "item", "20", "24"). However, since LLMs are typically pretrained on natural language tasks, these in-vocabulary tokens lack the expressive power for distinctive users and items, thereby weakening the recommendation ability even after fine-tuning on recommendation tasks. In this paper, we explore how to effectively tokenize users and items in LLM-based recommender systems. We emphasize the role of out-of-vocabulary (OOV) tokens in addition to the in-vocabulary ones and claim the memorization of OOV tokens that capture correlations of users/items as well as diversity of OOV tokens. By clustering the learned representations from historical user-item interactions, we make the representations of user/item combinations share the same OOV tokens if they have similar properties. Furthermore, integrating these OOV tokens into the LLM's vocabulary allows for better distinction between users and items and enhanced capture of user-item relationships during fine-tuning on downstream tasks. Our proposed framework outperforms existing state-of-the-art methods across various downstream recommendation tasks.
JobFormer: Skill-Aware Job Recommendation with Semantic-Enhanced Transformer
Apr 05, 2024Job recommendation aims to provide potential talents with suitable job descriptions (JDs) consistent with their career trajectory, which plays an essential role in proactive talent recruitment. In real-world management scenarios, the available JD-user records always consist of JDs, user profiles, and click data, in which the user profiles are typically summarized as the user's skill distribution for privacy reasons. Although existing sophisticated recommendation methods can be directly employed, effective recommendation still has challenges considering the information deficit of JD itself and the natural heterogeneous gap between JD and user profile. To address these challenges, we proposed a novel skill-aware recommendation model based on the designed semantic-enhanced transformer to parse JDs and complete personalized job recommendation. Specifically, we first model the relative items of each JD and then adopt an encoder with the local-global attention mechanism to better mine the intra-job and inter-job dependencies from JD tuples. Moreover, we adopt a two-stage learning strategy for skill-aware recommendation, in which we utilize the skill distribution to guide JD representation learning in the recall stage, and then combine the user profiles for final prediction in the ranking stage. Consequently, we can embed rich contextual semantic representations for learning JDs, while skill-aware recommendation provides effective JD-user joint representation for click-through rate (CTR) prediction. To validate the superior performance of our method for job recommendation, we present a thorough empirical analysis of large-scale real-world and public datasets to demonstrate its effectiveness and interpretability.
Learning Operators with Stochastic Gradient Descent in General Hilbert Spaces
Feb 13, 2024This study investigates leveraging stochastic gradient descent (SGD) to learn operators between general Hilbert spaces. We propose weak and strong regularity conditions for the target operator to depict its intrinsic structure and complexity. Under these conditions, we establish upper bounds for convergence rates of the SGD algorithm and conduct a minimax lower bound analysis, further illustrating that our convergence analysis and regularity conditions quantitatively characterize the tractability of solving operator learning problems using the SGD algorithm. It is crucial to highlight that our convergence analysis is still valid for nonlinear operator learning. We show that the SGD estimator will converge to the best linear approximation of the nonlinear target operator. Moreover, applying our analysis to operator learning problems based on vector-valued and real-valued reproducing kernel Hilbert spaces yields new convergence results, thereby refining the conclusions of existing literature.
REFORM: Removing False Correlation in Multi-level Interaction for CTR Prediction
Sep 26, 2023Click-through rate (CTR) prediction is a critical task in online advertising and recommendation systems, as accurate predictions are essential for user targeting and personalized recommendations. Most recent cutting-edge methods primarily focus on investigating complex implicit and explicit feature interactions. However, these methods neglect the issue of false correlations caused by confounding factors or selection bias. This problem is further magnified by the complexity and redundancy of these interactions. We propose a CTR prediction framework that removes false correlation in multi-level feature interaction, termed REFORM. The proposed REFORM framework exploits a wide range of multi-level high-order feature representations via a two-stream stacked recurrent structure while eliminating false correlations. The framework has two key components: I. The multi-level stacked recurrent (MSR) structure enables the model to efficiently capture diverse nonlinear interactions from feature spaces of different levels, and the richer representations lead to enhanced CTR prediction accuracy. II. The false correlation elimination (FCE) module further leverages Laplacian kernel mapping and sample reweighting methods to eliminate false correlations concealed within the multi-level features, allowing the model to focus on the true causal effects. Extensive experiments based on four challenging CTR datasets and our production dataset demonstrate that the proposed REFORM model achieves state-of-the-art performance. Codes, models and our dataset will be released at https://github.com/yansuoyuli/REFORM.
COURIER: Contrastive User Intention Reconstruction for Large-Scale Pre-Train of Image Features
Jun 08, 2023With the development of the multi-media internet, visual characteristics have become an important factor affecting user interests. Thus, incorporating visual features is a promising direction for further performance improvements in click-through rate (CTR) prediction. However, we found that simply injecting the image embeddings trained with established pre-training methods only has marginal improvements. We attribute the failure to two reasons: First, The pre-training methods are designed for well-defined computer vision tasks concentrating on semantic features, and they cannot learn personalized interest in recommendations. Secondly, pre-trained image embeddings only containing semantic information have little information gain, considering we already have semantic features such as categories and item titles as inputs in the CTR prediction task. We argue that a pre-training method tailored for recommendation is necessary for further improvements. To this end, we propose a recommendation-aware image pre-training method that can learn visual features from user click histories. Specifically, we propose a user interest reconstruction module to mine visual features related to user interests from behavior histories. We further propose a contrastive training method to avoid collapsing of embedding vectors. We conduct extensive experiments to verify that our method can learn users' visual interests, and our method achieves $0.46\%$ improvement in offline AUC and $0.88\%$ improvement in Taobao online GMV with p-value$<0.01$.
Beyond Probability Partitions: Calibrating Neural Networks with Semantic Aware Grouping
Jun 08, 2023Research has shown that deep networks tend to be overly optimistic about their predictions, leading to an underestimation of prediction errors. Due to the limited nature of data, existing studies have proposed various methods based on model prediction probabilities to bin the data and evaluate calibration error. We propose a more generalized definition of calibration error called Partitioned Calibration Error (PCE), revealing that the key difference among these calibration error metrics lies in how the data space is partitioned. We put forth an intuitive proposition that an accurate model should be calibrated across any partition, suggesting that the input space partitioning can extend beyond just the partitioning of prediction probabilities, and include partitions directly related to the input. Through semantic-related partitioning functions, we demonstrate that the relationship between model accuracy and calibration lies in the granularity of the partitioning function. This highlights the importance of partitioning criteria for training a calibrated and accurate model. To validate the aforementioned analysis, we propose a method that involves jointly learning a semantic aware grouping function based on deep model features and logits to partition the data space into subsets. Subsequently, a separate calibration function is learned for each subset. Experimental results demonstrate that our approach achieves significant performance improvements across multiple datasets and network architectures, thus highlighting the importance of the partitioning function for calibration.
IDToolkit: A Toolkit for Benchmarking and Developing Inverse Design Algorithms in Nanophotonics
May 31, 2023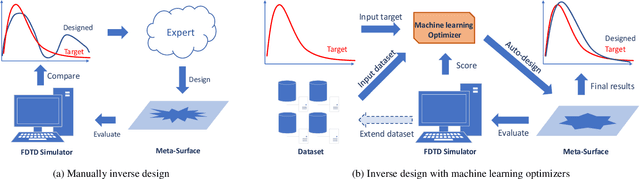

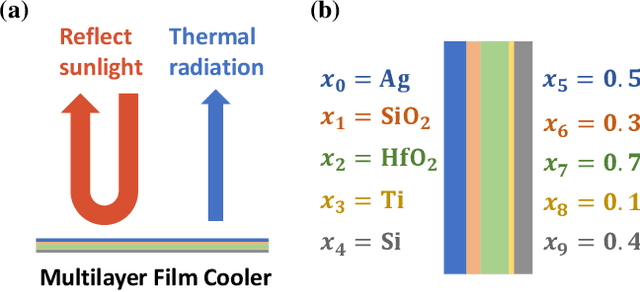
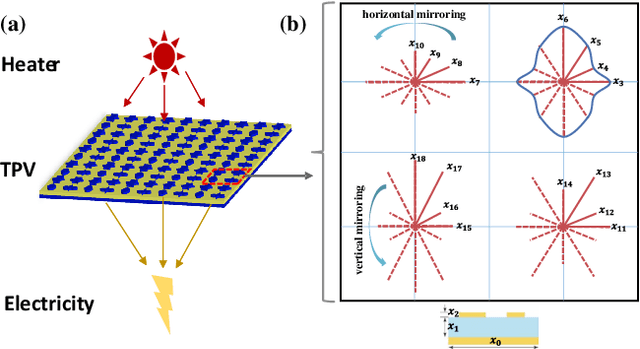
Aiding humans with scientific designs is one of the most exciting of artificial intelligence (AI) and machine learning (ML), due to their potential for the discovery of new drugs, design of new materials and chemical compounds, etc. However, scientific design typically requires complex domain knowledge that is not familiar to AI researchers. Further, scientific studies involve professional skills to perform experiments and evaluations. These obstacles prevent AI researchers from developing specialized methods for scientific designs. To take a step towards easy-to-understand and reproducible research of scientific design, we propose a benchmark for the inverse design of nanophotonic devices, which can be verified computationally and accurately. Specifically, we implemented three different nanophotonic design problems, namely a radiative cooler, a selective emitter for thermophotovoltaics, and structural color filters, all of which are different in design parameter spaces, complexity, and design targets. The benchmark environments are implemented with an open-source simulator. We further implemented 10 different inverse design algorithms and compared them in a reproducible and fair framework. The results revealed the strengths and weaknesses of existing methods, which shed light on several future directions for developing more efficient inverse design algorithms. Our benchmark can also serve as the starting point for more challenging scientific design problems. The code of IDToolkit is available at https://github.com/ThyrixYang/IDToolkit.
Generalized Delayed Feedback Model with Post-Click Information in Recommender Systems
Jun 01, 2022



Predicting conversion rate (e.g., the probability that a user will purchase an item) is a fundamental problem in machine learning based recommender systems. However, accurate conversion labels are revealed after a long delay, which harms the timeliness of recommender systems. Previous literature concentrates on utilizing early conversions to mitigate such a delayed feedback problem. In this paper, we show that post-click user behaviors are also informative to conversion rate prediction and can be used to improve timeliness. We propose a generalized delayed feedback model (GDFM) that unifies both post-click behaviors and early conversions as stochastic post-click information, which could be utilized to train GDFM in a streaming manner efficiently. Based on GDFM, we further establish a novel perspective that the performance gap introduced by delayed feedback can be attributed to a temporal gap and a sampling gap. Inspired by our analysis, we propose to measure the quality of post-click information with a combination of temporal distance and sample complexity. The training objective is re-weighted accordingly to highlight informative and timely signals. We validate our analysis on public datasets, and experimental performance confirms the effectiveness of our method.