 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Retrieval-Augmented Reasoning with Parallel Search and Explicit Merging
May 13, 2026Deep search agents have proven effective in enhancing LLMs by retrieving external knowledge during multi-step reasoning. However, existing methods often generate a single query for retrieval at each reasoning step, limiting information coverage and introducing high noise. This may result in low signal-to-noise ratios (SNR) during search, degrading reasoning accuracy and leading to unnecessary reasoning steps. In this paper, we introduce MultiSearch, an RL-based framework that addresses these limitations through multi-query retrieval and explicit merging of retrieved information. At each reasoning step, MultiSearch generates queries from multiple perspectives and retrieves external information in parallel, expanding the scope of relevant information and mitigating the reliance on any single retrieval result. Then, the agent consolidates and refines retrieved information at the merging process, improving the SNR and ensuring more accurate reasoning. Additionally, we propose a reinforcement learning framework with a multi-process reward design to optimize agents for both multi-query retrieval and information consolidation. Extensive experiments on seven benchmarks demonstrate that MultiSearch outperforms baseline methods, enhancing the SNR of retrieval and improving reasoning performance in question-answering tasks.
Reasoning over Semantic IDs Enhances Generative Recommendation
Mar 24, 2026Recent advances in generative recommendation have leveraged pretrained LLMs by formulating sequential recommendation as autoregressive generation over a unified token space comprising language tokens and itemic identifiers, where each item is represented by a compact sequence of discrete tokens, namely Semantic IDs (SIDs). This SID-based formulation enables efficient decoding over large-scale item corpora and provides a natural interface for LLM-based recommenders to leverage rich world knowledge. Meanwhile, breakthroughs in LLM reasoning motivate reasoning-enhanced recommendation, yet effective reasoning over SIDs remains underexplored and challenging. Itemic tokens are not natively meaningful to LLMs; moreover, recommendation-oriented SID reasoning is hard to evaluate, making high-quality supervision scarce. To address these challenges, we propose SIDReasoner, a two-stage framework that elicits reasoning over SIDs by strengthening SID--language alignment to unlock transferable LLM reasoning, rather than relying on large amounts of recommendation-specific reasoning traces. Concretely, SIDReasoner first enhances SID-language alignment via multi-task training on an enriched SID-centered corpus synthesized by a stronger teacher model, grounding itemic tokens in diverse semantic and behavioral contexts. Building on this enhanced alignment, SIDReasoner further improves recommendation reasoning through outcome-driven reinforced optimization, which guides the model toward effective reasoning trajectories without requiring explicit reasoning annotations. Extensive experiments on three real-world datasets demonstrate the effectiveness of our reasoning-augmented SID-based generative recommendation. Beyond accuracy, the results highlight the broader potential of large reasoning models for generative recommendation, including improved interpretability and cross-domain generalization.
PRECISE: Pre-training Sequential Recommenders with Collaborative and Semantic Information
Dec 09, 2024Real-world recommendation systems commonly offer diverse content scenarios for users to interact with. Considering the enormous number of users in industrial platforms, it is infeasible to utilize a single unified recommendation model to meet the requirements of all scenarios. Usually, separate recommendation pipelines are established for each distinct scenario. This practice leads to challenges in comprehensively grasping users' interests. Recent research endeavors have been made to tackle this problem by pre-training models to encapsulate the overall interests of users. Traditional pre-trained recommendation models mainly capture user interests by leveraging collaborative signals. Nevertheless, a prevalent drawback of these systems is their incapacity to handle long-tail items and cold-start scenarios. With the recent advent of large language models, there has been a significant increase in research efforts focused on exploiting LLMs to extract semantic information for users and items. However, text-based recommendations highly rely on elaborate feature engineering and frequently fail to capture collaborative similarities. To overcome these limitations, we propose a novel pre-training framework for sequential recommendation, termed PRECISE. This framework combines collaborative signals with semantic information. Moreover, PRECISE employs a learning framework that initially models users' comprehensive interests across all recommendation scenarios and subsequently concentrates on the specific interests of target-scene behaviors. We demonstrate that PRECISE precisely captures the entire range of user interests and effectively transfers them to the target interests. Empirical findings reveal that the PRECISE framework attains outstanding performance on both public and industrial datasets.
Adaptive Coordinators and Prompts on Heterogeneous Graphs for Cross-Domain Recommendations
Oct 15, 2024


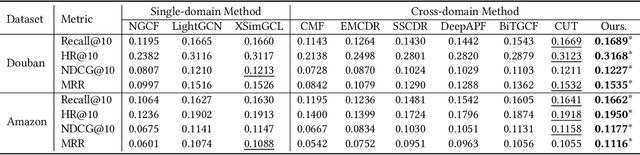
In the online digital world, users frequently engage with diverse items across multiple domains (e.g., e-commerce platforms, streaming services, and social media networks), forming complex heterogeneous interaction graphs. Leveraging this multi-domain information can undoubtedly enhance the performance of recommendation systems by providing more comprehensive user insights and alleviating data sparsity in individual domains. However, integrating multi-domain knowledge for the cross-domain recommendation is very hard due to inherent disparities in user behavior and item characteristics and the risk of negative transfer, where irrelevant or conflicting information from the source domains adversely impacts the target domain's performance. To address these challenges, we offer HAGO, a novel framework with $\textbf{H}$eterogeneous $\textbf{A}$daptive $\textbf{G}$raph co$\textbf{O}$rdinators, which dynamically integrate multi-domain graphs into a cohesive structure by adaptively adjusting the connections between coordinators and multi-domain graph nodes, thereby enhancing beneficial inter-domain interactions while mitigating negative transfer effects. Additionally, we develop a universal multi-domain graph pre-training strategy alongside HAGO to collaboratively learn high-quality node representations across domains. To effectively transfer the learned multi-domain knowledge to the target domain, we design an effective graph prompting method, which incorporates pre-trained embeddings with learnable prompts for the recommendation task. Our framework is compatible with various graph-based models and pre-training techniques, demonstrating broad applicability and effectiveness. Further experimental results show that our solutions outperform state-of-the-art methods in multi-domain recommendation scenarios and highlight their potential for real-world applications.
Improving LLMs for Recommendation with Out-Of-Vocabulary Tokens
Jun 12, 2024



Characterizing users and items through vector representations is crucial for various tasks in recommender systems. Recent approaches attempt to apply Large Language Models (LLMs) in recommendation through a question and answer format, where real users and items (e.g., Item No.2024) are represented with in-vocabulary tokens (e.g., "item", "20", "24"). However, since LLMs are typically pretrained on natural language tasks, these in-vocabulary tokens lack the expressive power for distinctive users and items, thereby weakening the recommendation ability even after fine-tuning on recommendation tasks. In this paper, we explore how to effectively tokenize users and items in LLM-based recommender systems. We emphasize the role of out-of-vocabulary (OOV) tokens in addition to the in-vocabulary ones and claim the memorization of OOV tokens that capture correlations of users/items as well as diversity of OOV tokens. By clustering the learned representations from historical user-item interactions, we make the representations of user/item combinations share the same OOV tokens if they have similar properties. Furthermore, integrating these OOV tokens into the LLM's vocabulary allows for better distinction between users and items and enhanced capture of user-item relationships during fine-tuning on downstream tasks. Our proposed framework outperforms existing state-of-the-art methods across various downstream recommendation tasks.
Pretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Aug 20, 2022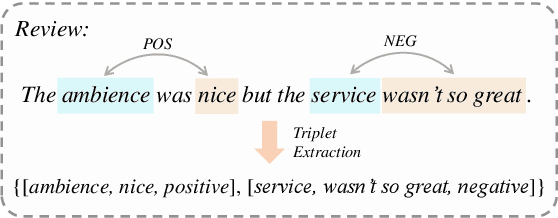
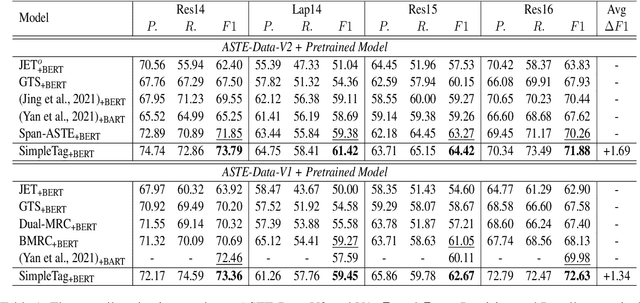
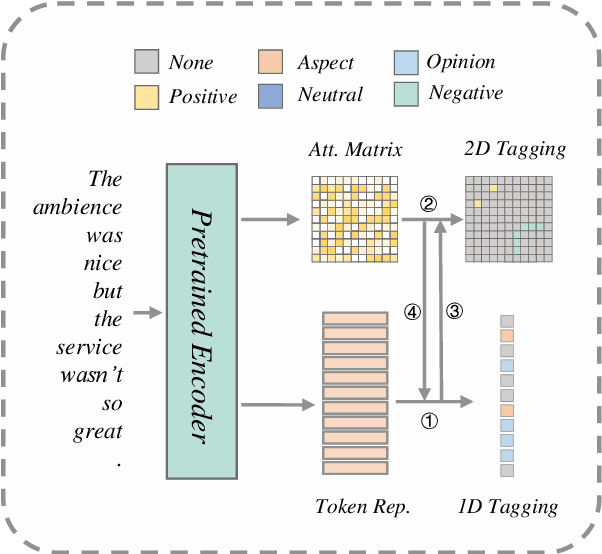
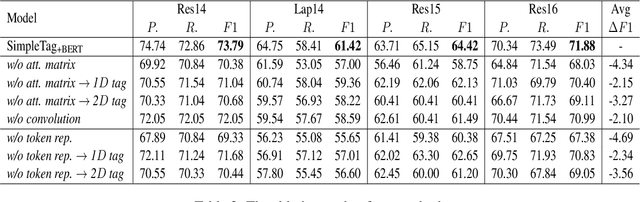
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.
AdnFM: An Attentive DenseNet based Factorization Machine for CTR Prediction
Dec 20, 2020
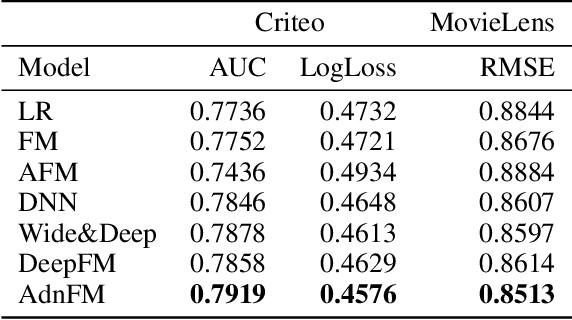
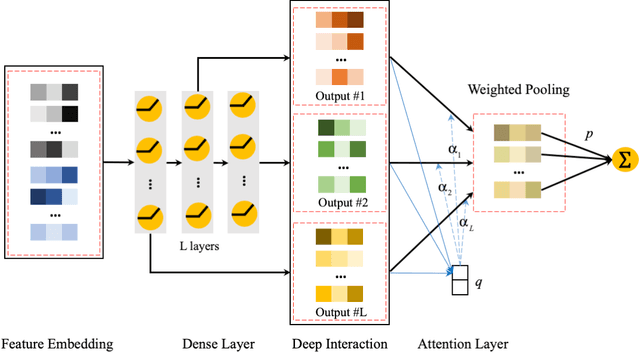
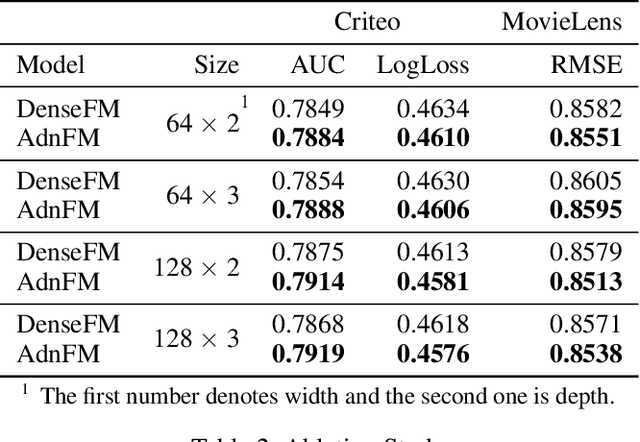
In this paper, we consider the Click-Through-Rate (CTR) prediction problem. Factorization Machines and their variants consider pair-wise feature interactions, but normally we won't do high-order feature interactions using FM due to high time complexity. Given the success of deep neural networks (DNNs) in many fields, researchers have proposed several DNN-based models to learn high-order feature interactions. Multi-layer perceptrons (MLP) have been widely employed to learn reliable mappings from feature embeddings to final logits. In this paper, we aim to explore more about these high-order features interactions. However, high-order feature interaction deserves more attention and further development. Inspired by the great achievements of Densely Connected Convolutional Networks (DenseNet) in computer vision, we propose a novel model called Attentive DenseNet based Factorization Machines (AdnFM). AdnFM can extract more comprehensive deep features by using all the hidden layers from a feed-forward neural network as implicit high-order features, then selects dominant features via an attention mechanism. Also, high-order interactions in the implicit way using DNNs are more cost-efficient than in the explicit way, for example in FM. Extensive experiments on two real-world datasets show that the proposed model can effectively improve the performance of CTR prediction.