 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrained Language Encoders are Natural Tagging Frameworks for Aspect Sentiment Triplet Extraction
Paper and Code
Aug 20, 2022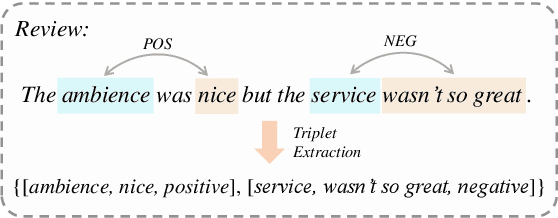
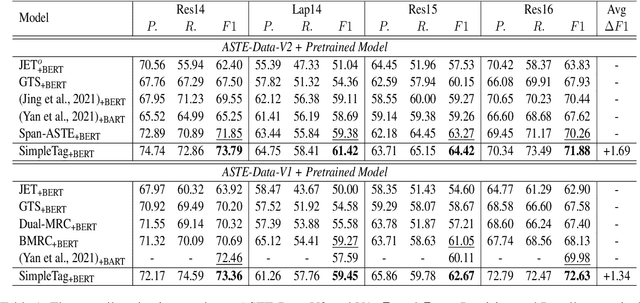
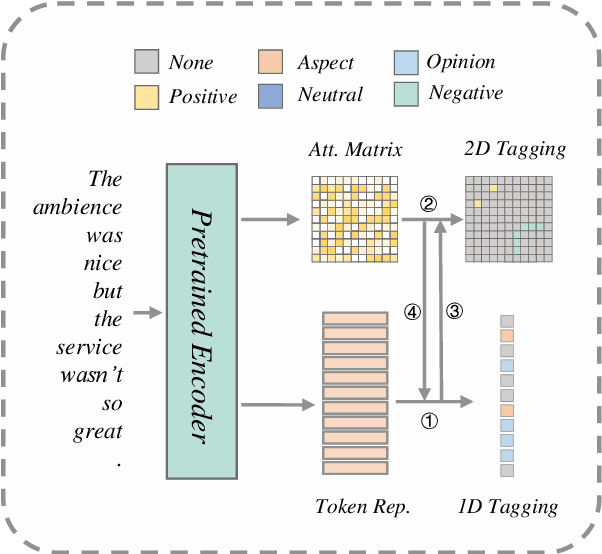
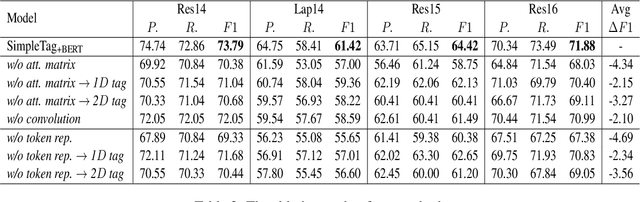
Aspect Sentiment Triplet Extraction (ASTE) aims to extract the spans of aspect, opinion, and their sentiment relations as sentiment triplets. Existing works usually formulate the span detection as a 1D token tagging problem, and model the sentiment recognition with a 2D tagging matrix of token pairs. Moreover, by leveraging the token representation of Pretrained Language Encoders (PLEs) like BERT, they can achieve better performance. However, they simply leverage PLEs as feature extractors to build their modules but never have a deep look at what specific knowledge does PLEs contain. In this paper, we argue that instead of further designing modules to capture the inductive bias of ASTE, PLEs themselves contain "enough" features for 1D and 2D tagging: (1) The token representation contains the contextualized meaning of token itself, so this level feature carries necessary information for 1D tagging. (2) The attention matrix of different PLE layers can further capture multi-level linguistic knowledge existing in token pairs, which benefits 2D tagging. (3) Furthermore, with simple transformations, these two features can also be easily converted to the 2D tagging matrix and 1D tagging sequence, respectively. That will further boost the tagging results. By doing so, PLEs can be natural tagging frameworks and achieve a new state of the art, which is verified by extensive experiments and deep analyses.