 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Eval: Agentic and Automated Evaluation for Embodied Brain
Feb 02, 2026Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman's rho=0.85, and maintains high ranking fidelity (Kendall's tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
Optimizing Agentic Reasoning with Retrieval via Synthetic Semantic Information Gain Reward
Jan 31, 2026Agentic reasoning enables large reasoning models (LRMs) to dynamically acquire external knowledge, but yet optimizing the retrieval process remains challenging due to the lack of dense, principled reward signals. In this paper, we introduce InfoReasoner, a unified framework that incentivizes effective information seeking via a synthetic semantic information gain reward. Theoretically, we redefine information gain as uncertainty reduction over the model's belief states, establishing guarantees, including non-negativity, telescoping additivity, and channel monotonicity. Practically, to enable scalable optimization without manual retrieval annotations, we propose an output-aware intrinsic estimator that computes information gain directly from the model's output distributions using semantic clustering via bidirectional textual entailment. This intrinsic reward guides the policy to maximize epistemic progress, enabling efficient training via Group Relative Policy Optimxization (GRPO). Experiments across seven question-answering benchmarks demonstrate that InfoReasoner consistently outperforms strong retrieval-augmented baselines, achieving up to 5.4% average accuracy improvement. Our work provides a theoretically grounded and scalable path toward agentic reasoning with retrieval.
Wow, wo, val! A Comprehensive Embodied World Model Evaluation Turing Test
Jan 07, 2026As world models gain momentum in Embodied AI, an increasing number of works explore using video foundation models as predictive world models for downstream embodied tasks like 3D prediction or interactive generation. However, before exploring these downstream tasks, video foundation models still have two critical questions unanswered: (1) whether their generative generalization is sufficient to maintain perceptual fidelity in the eyes of human observers, and (2) whether they are robust enough to serve as a universal prior for real-world embodied agents. To provide a standardized framework for answering these questions, we introduce the Embodied Turing Test benchmark: WoW-World-Eval (Wow,wo,val). Building upon 609 robot manipulation data, Wow-wo-val examines five core abilities, including perception, planning, prediction, generalization, and execution. We propose a comprehensive evaluation protocol with 22 metrics to assess the models' generation ability, which achieves a high Pearson Correlation between the overall score and human preference (>0.93) and establishes a reliable foundation for the Human Turing Test. On Wow-wo-val, models achieve only 17.27 on long-horizon planning and at best 68.02 on physical consistency, indicating limited spatiotemporal consistency and physical reasoning. For the Inverse Dynamic Model Turing Test, we first use an IDM to evaluate the video foundation models' execution accuracy in the real world. However, most models collapse to $\approx$ 0% success, while WoW maintains a 40.74% success rate. These findings point to a noticeable gap between the generated videos and the real world, highlighting the urgency and necessity of benchmarking World Model in Embodied AI.
Auto-US: An Ultrasound Video Diagnosis Agent Using Video Classification Framework and LLMs
Nov 11, 2025AI-assisted ultrasound video diagnosis presents new opportunities to enhance the efficiency and accuracy of medical imaging analysis. However, existing research remains limited in terms of dataset diversity, diagnostic performance, and clinical applicability. In this study, we propose \textbf{Auto-US}, an intelligent diagnosis agent that integrates ultrasound video data with clinical diagnostic text. To support this, we constructed \textbf{CUV Dataset} of 495 ultrasound videos spanning five categories and three organs, aggregated from multiple open-access sources. We developed \textbf{CTU-Net}, which achieves state-of-the-art performance in ultrasound video classification, reaching an accuracy of 86.73\% Furthermore, by incorporating large language models, Auto-US is capable of generating clinically meaningful diagnostic suggestions. The final diagnostic scores for each case exceeded 3 out of 5 and were validated by professional clinicians. These results demonstrate the effectiveness and clinical potential of Auto-US in real-world ultrasound applications. Code and data are available at: https://github.com/Bean-Young/Auto-US.
WoW: Towards a World omniscient World model Through Embodied Interaction
Sep 26, 2025Humans develop an understanding of intuitive physics through active interaction with the world. This approach is in stark contrast to current video models, such as Sora, which rely on passive observation and therefore struggle with grasping physical causality. This observation leads to our central hypothesis: authentic physical intuition of the world model must be grounded in extensive, causally rich interactions with the real world. To test this hypothesis, we present WoW, a 14-billion-parameter generative world model trained on 2 million robot interaction trajectories. Our findings reveal that the model's understanding of physics is a probabilistic distribution of plausible outcomes, leading to stochastic instabilities and physical hallucinations. Furthermore, we demonstrate that this emergent capability can be actively constrained toward physical realism by SOPHIA, where vision-language model agents evaluate the DiT-generated output and guide its refinement by iteratively evolving the language instructions. In addition, a co-trained Inverse Dynamics Model translates these refined plans into executable robotic actions, thus closing the imagination-to-action loop. We establish WoWBench, a new benchmark focused on physical consistency and causal reasoning in video, where WoW achieves state-of-the-art performance in both human and autonomous evaluation, demonstrating strong ability in physical causality, collision dynamics, and object permanence. Our work provides systematic evidence that large-scale, real-world interaction is a cornerstone for developing physical intuition in AI. Models, data, and benchmarks will be open-sourced.
Beyond Distillation: Pushing the Limits of Medical LLM Reasoning with Minimalist Rule-Based RL
May 23, 2025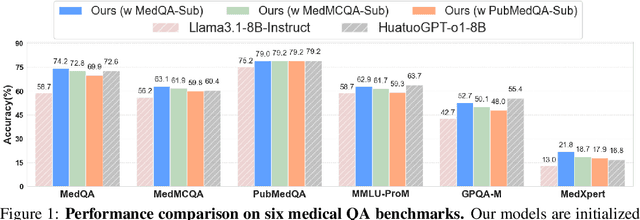
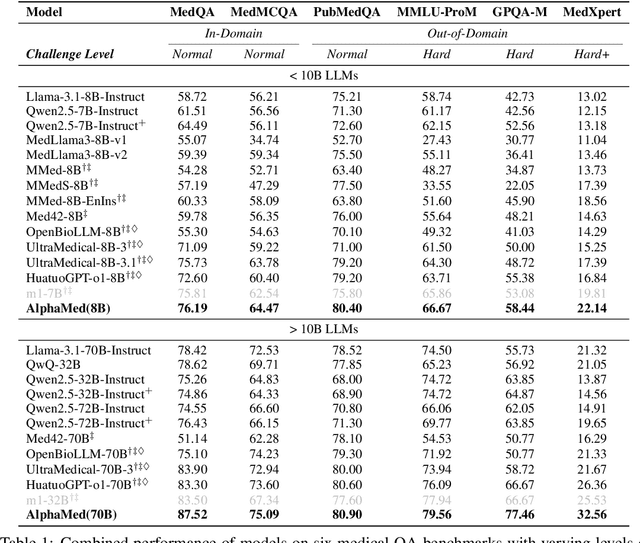
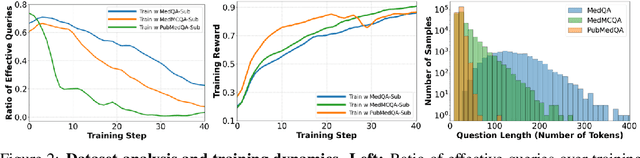

Improving performance on complex tasks and enabling interpretable decision making in large language models (LLMs), especially for clinical applications, requires effective reasoning. Yet this remains challenging without supervised fine-tuning (SFT) on costly chain-of-thought (CoT) data distilled from closed-source models (e.g., GPT-4o). In this work, we present AlphaMed, the first medical LLM to show that reasoning capability can emerge purely through reinforcement learning (RL), using minimalist rule-based rewards on public multiple-choice QA datasets, without relying on SFT or distilled CoT data. AlphaMed achieves state-of-the-art results on six medical QA benchmarks, outperforming models trained with conventional SFT+RL pipelines. On challenging benchmarks (e.g., MedXpert), AlphaMed even surpasses larger or closed-source models such as DeepSeek-V3-671B and Claude-3.5-Sonnet. To understand the factors behind this success, we conduct a comprehensive data-centric analysis guided by three questions: (i) Can minimalist rule-based RL incentivize reasoning without distilled CoT supervision? (ii) How do dataset quantity and diversity impact reasoning? (iii) How does question difficulty shape the emergence and generalization of reasoning? Our findings show that dataset informativeness is a key driver of reasoning performance, and that minimalist RL on informative, multiple-choice QA data is effective at inducing reasoning without CoT supervision. We also observe divergent trends across benchmarks, underscoring limitations in current evaluation and the need for more challenging, reasoning-oriented medical QA benchmarks.
MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning
Nov 05, 2024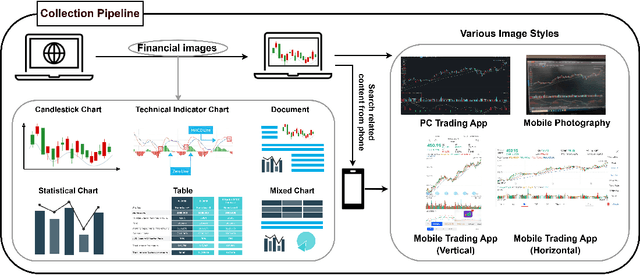
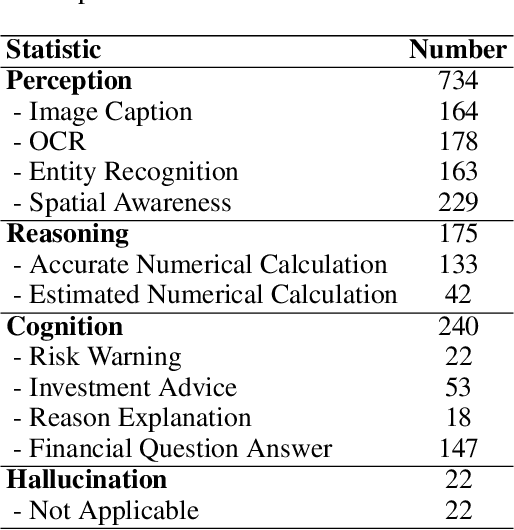
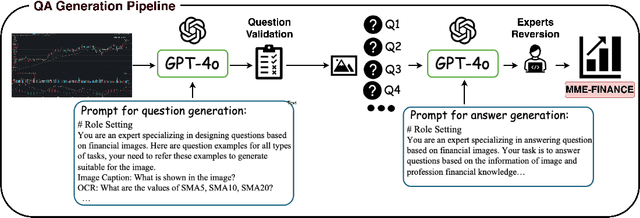
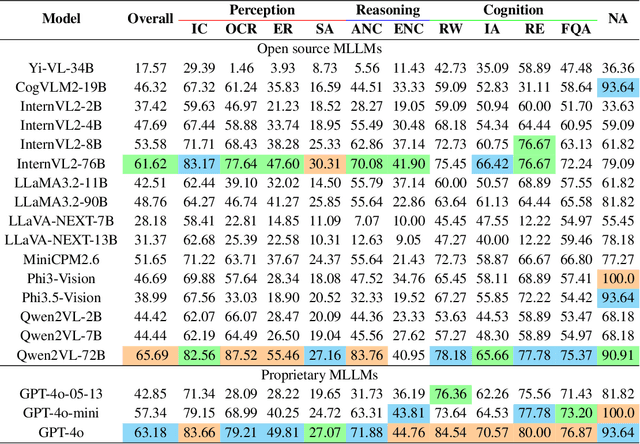
In recent years, multimodal benchmarks for general domains have guided the rapid development of multimodal models on general tasks. However, the financial field has its peculiarities. It features unique graphical images (e.g., candlestick charts, technical indicator charts) and possesses a wealth of specialized financial knowledge (e.g., futures, turnover rate). Therefore, benchmarks from general fields often fail to measure the performance of multimodal models in the financial domain, and thus cannot effectively guide the rapid development of large financial models. To promote the development of large financial multimodal models, we propose MME-Finance, an bilingual open-ended and practical usage-oriented Visual Question Answering (VQA) benchmark. The characteristics of our benchmark are finance and expertise, which include constructing charts that reflect the actual usage needs of users (e.g., computer screenshots and mobile photography), creating questions according to the preferences in financial domain inquiries, and annotating questions by experts with 10+ years of experience in the financial industry. Additionally, we have developed a custom-designed financial evaluation system in which visual information is first introduced in the multi-modal evaluation process. Extensive experimental evaluations of 19 mainstream MLLMs are conducted to test their perception, reasoning, and cognition capabilities. The results indicate that models performing well on general benchmarks cannot do well on MME-Finance; for instance, the top-performing open-source and closed-source models obtain 65.69 (Qwen2VL-72B) and 63.18 (GPT-4o), respectively. Their performance is particularly poor in categories most relevant to finance, such as candlestick charts and technical indicator charts. In addition, we propose a Chinese version, which helps compare performance of MLLMs under a Chinese context.
TimeCNN: Refining Cross-Variable Interaction on Time Point for Time Series Forecasting
Oct 07, 2024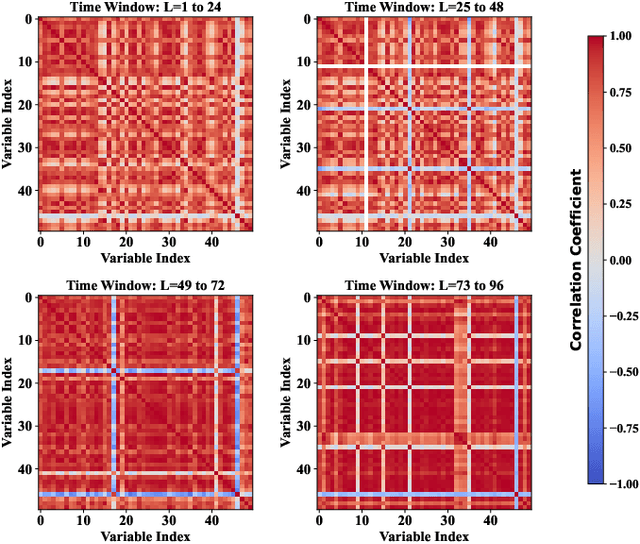
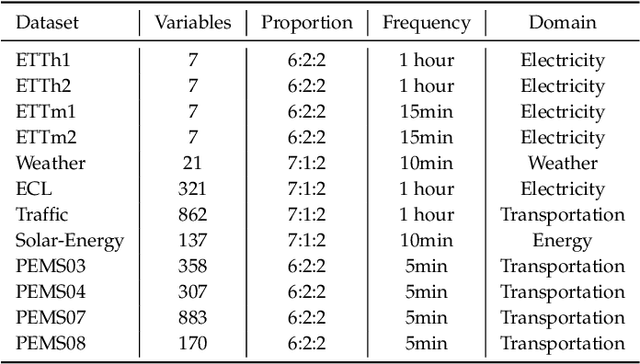
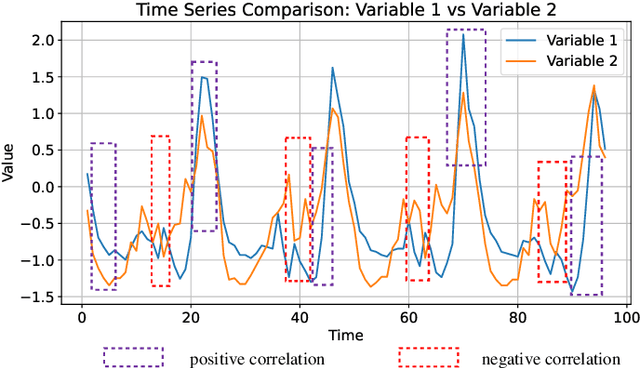
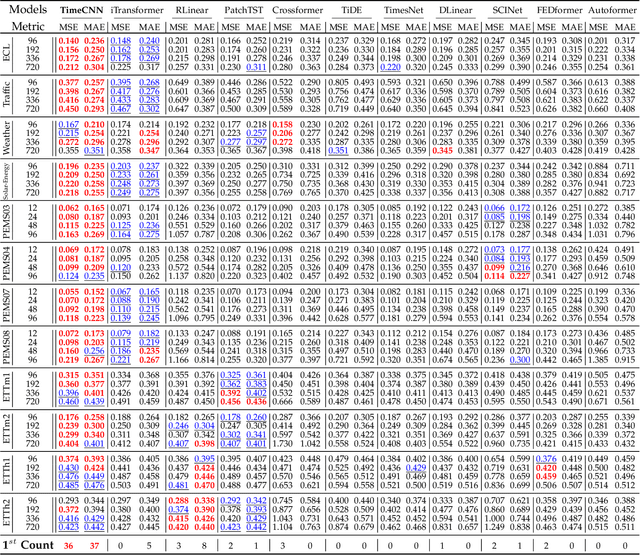
Time series forecasting is extensively applied across diverse domains. Transformer-based models demonstrate significant potential in modeling cross-time and cross-variable interaction. However, we notice that the cross-variable correlation of multivariate time series demonstrates multifaceted (positive and negative correlations) and dynamic progression over time, which is not well captured by existing Transformer-based models. To address this issue, we propose a TimeCNN model to refine cross-variable interactions to enhance time series forecasting. Its key innovation is timepoint-independent, where each time point has an independent convolution kernel, allowing each time point to have its independent model to capture relationships among variables. This approach effectively handles both positive and negative correlations and adapts to the evolving nature of variable relationships over time. Extensive experiments conducted on 12 real-world datasets demonstrate that TimeCNN consistently outperforms state-of-the-art models. Notably, our model achieves significant reductions in computational requirements (approximately 60.46%) and parameter count (about 57.50%), while delivering inference speeds 3 to 4 times faster than the benchmark iTransformer model
IDGen: Item Discrimination Induced Prompt Generation for LLM Evaluation
Sep 27, 2024



As Large Language Models (LLMs) grow increasingly adept at managing complex tasks, the evaluation set must keep pace with these advancements to ensure it remains sufficiently discriminative. Item Discrimination (ID) theory, which is widely used in educational assessment, measures the ability of individual test items to differentiate between high and low performers. Inspired by this theory, we propose an ID-induced prompt synthesis framework for evaluating LLMs to ensure the evaluation set can continually update and refine according to model abilities. Our data synthesis framework prioritizes both breadth and specificity. It can generate prompts that comprehensively evaluate the capabilities of LLMs while revealing meaningful performance differences between models, allowing for effective discrimination of their relative strengths and weaknesses across various tasks and domains. To produce high-quality data, we incorporate a self-correct mechanism into our generalization framework, and develop two models to predict prompt discrimination and difficulty score to facilitate our data synthesis framework, contributing valuable tools to evaluation data synthesis research. We apply our generated data to evaluate five SOTA models. Our data achieves an average score of 51.92, accompanied by a variance of 10.06. By contrast, previous works (i.e., SELF-INSTRUCT and WizardLM) obtain an average score exceeding 67, with a variance below 3.2. The results demonstrate that the data generated by our framework is more challenging and discriminative compared to previous works. We will release a dataset of over 3,000 carefully crafted prompts to facilitate evaluation research of LLMs.
Prompt Customization for Continual Learning
Apr 28, 2024



Contemporary continual learning approaches typically select prompts from a pool, which function as supplementary inputs to a pre-trained model. However, this strategy is hindered by the inherent noise of its selection approach when handling increasing tasks. In response to these challenges, we reformulate the prompting approach for continual learning and propose the prompt customization (PC) method. PC mainly comprises a prompt generation module (PGM) and a prompt modulation module (PMM). In contrast to conventional methods that employ hard prompt selection, PGM assigns different coefficients to prompts from a fixed-sized pool of prompts and generates tailored prompts. Moreover, PMM further modulates the prompts by adaptively assigning weights according to the correlations between input data and corresponding prompts. We evaluate our method on four benchmark datasets for three diverse settings, including the class, domain, and task-agnostic incremental learning tasks. Experimental results demonstrate consistent improvement (by up to 16.2\%), yielded by the proposed method, over the state-of-the-art (SOTA) techniques.