 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMTM: A Multi-Turn Multimodal Benchmark for Financial Reasoning and Agent Evaluation
Feb 03, 2026The financial domain poses substantial challenges for vision-language models (VLMs) due to specialized chart formats and knowledge-intensive reasoning requirements. However, existing financial benchmarks are largely single-turn and rely on a narrow set of question formats, limiting comprehensive evaluation in realistic application scenarios. To address this gap, we propose FinMTM, a multi-turn multimodal benchmark that expands diversity along both data and task dimensions. On the data side, we curate and annotate 11{,}133 bilingual (Chinese and English) financial QA pairs grounded in financial visuals, including candlestick charts, statistical plots, and report figures. On the task side, FinMTM covers single- and multiple-choice questions, multi-turn open-ended dialogues, and agent-based tasks. We further design task-specific evaluation protocols, including a set-overlap scoring rule for multiple-choice questions, a weighted combination of turn-level and session-level scores for multi-turn dialogues, and a composite metric that integrates planning quality with final outcomes for agent tasks. Extensive experimental evaluation of 22 VLMs reveal their limitations in fine-grained visual perception, long-context reasoning, and complex agent workflows.
MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning
Nov 05, 2024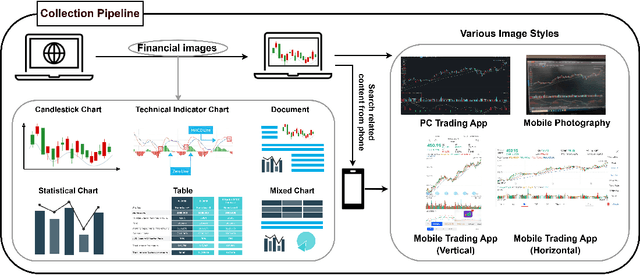
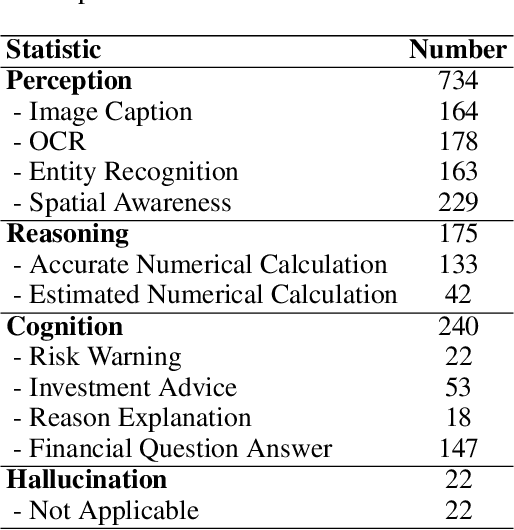
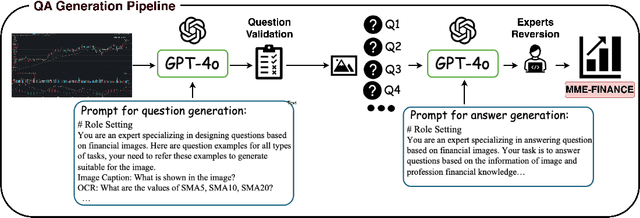
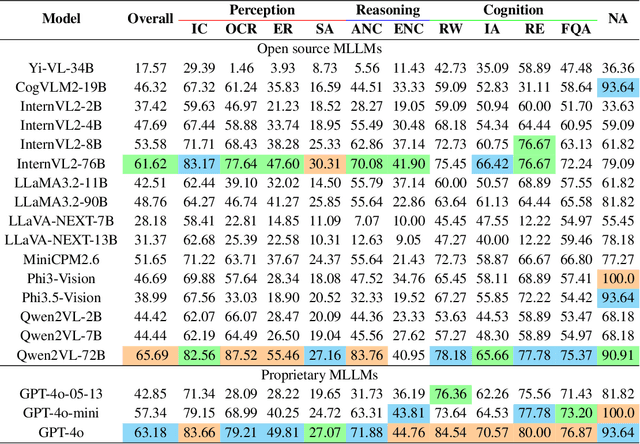
In recent years, multimodal benchmarks for general domains have guided the rapid development of multimodal models on general tasks. However, the financial field has its peculiarities. It features unique graphical images (e.g., candlestick charts, technical indicator charts) and possesses a wealth of specialized financial knowledge (e.g., futures, turnover rate). Therefore, benchmarks from general fields often fail to measure the performance of multimodal models in the financial domain, and thus cannot effectively guide the rapid development of large financial models. To promote the development of large financial multimodal models, we propose MME-Finance, an bilingual open-ended and practical usage-oriented Visual Question Answering (VQA) benchmark. The characteristics of our benchmark are finance and expertise, which include constructing charts that reflect the actual usage needs of users (e.g., computer screenshots and mobile photography), creating questions according to the preferences in financial domain inquiries, and annotating questions by experts with 10+ years of experience in the financial industry. Additionally, we have developed a custom-designed financial evaluation system in which visual information is first introduced in the multi-modal evaluation process. Extensive experimental evaluations of 19 mainstream MLLMs are conducted to test their perception, reasoning, and cognition capabilities. The results indicate that models performing well on general benchmarks cannot do well on MME-Finance; for instance, the top-performing open-source and closed-source models obtain 65.69 (Qwen2VL-72B) and 63.18 (GPT-4o), respectively. Their performance is particularly poor in categories most relevant to finance, such as candlestick charts and technical indicator charts. In addition, we propose a Chinese version, which helps compare performance of MLLMs under a Chinese context.