 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzleClone: An SMT-Powered Framework for Synthesizing Verifiable Data
Aug 21, 2025High-quality mathematical and logical datasets with verifiable answers are essential for strengthening the reasoning capabilities of large language models (LLMs). While recent data augmentation techniques have facilitated the creation of large-scale benchmarks, existing LLM-generated datasets often suffer from limited reliability, diversity, and scalability. To address these challenges, we introduce PuzzleClone, a formal framework for synthesizing verifiable data at scale using Satisfiability Modulo Theories (SMT). Our approach features three key innovations: (1) encoding seed puzzles into structured logical specifications, (2) generating scalable variants through systematic variable and constraint randomization, and (3) ensuring validity via a reproduction mechanism. Applying PuzzleClone, we construct a curated benchmark comprising over 83K diverse and programmatically validated puzzles. The generated puzzles span a wide spectrum of difficulty and formats, posing significant challenges to current state-of-the-art models. We conduct post training (SFT and RL) on PuzzleClone datasets. Experimental results show that training on PuzzleClone yields substantial improvements not only on PuzzleClone testset but also on logic and mathematical benchmarks. Post training raises PuzzleClone average from 14.4 to 56.2 and delivers consistent improvements across 7 logic and mathematical benchmarks up to 12.5 absolute percentage points (AMC2023 from 52.5 to 65.0). Our code and data are available at https://github.com/puzzleclone.
MME-Finance: A Multimodal Finance Benchmark for Expert-level Understanding and Reasoning
Nov 05, 2024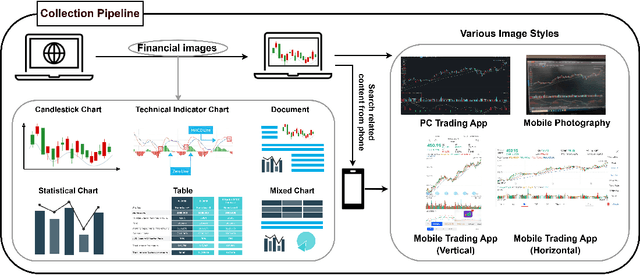
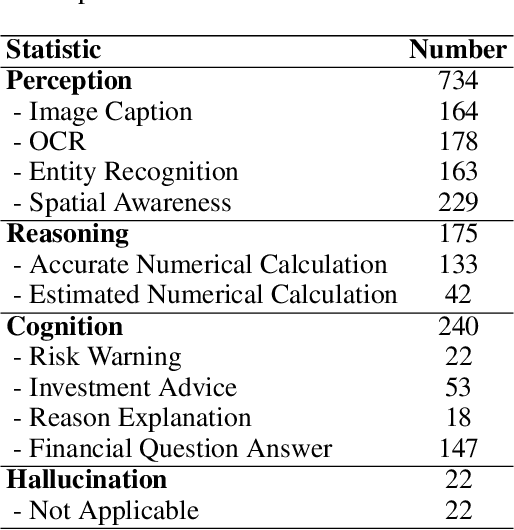
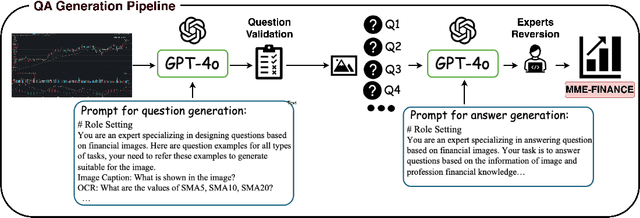
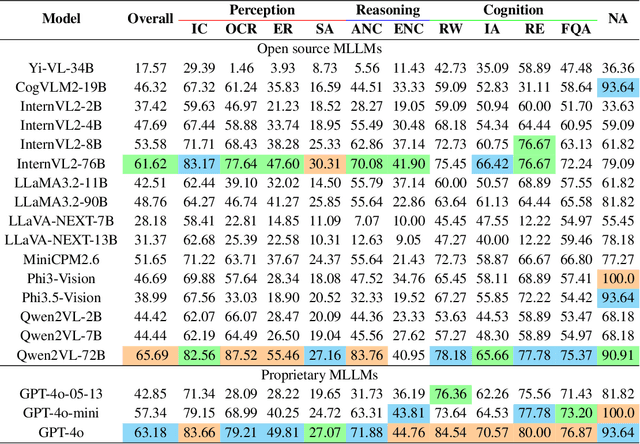
In recent years, multimodal benchmarks for general domains have guided the rapid development of multimodal models on general tasks. However, the financial field has its peculiarities. It features unique graphical images (e.g., candlestick charts, technical indicator charts) and possesses a wealth of specialized financial knowledge (e.g., futures, turnover rate). Therefore, benchmarks from general fields often fail to measure the performance of multimodal models in the financial domain, and thus cannot effectively guide the rapid development of large financial models. To promote the development of large financial multimodal models, we propose MME-Finance, an bilingual open-ended and practical usage-oriented Visual Question Answering (VQA) benchmark. The characteristics of our benchmark are finance and expertise, which include constructing charts that reflect the actual usage needs of users (e.g., computer screenshots and mobile photography), creating questions according to the preferences in financial domain inquiries, and annotating questions by experts with 10+ years of experience in the financial industry. Additionally, we have developed a custom-designed financial evaluation system in which visual information is first introduced in the multi-modal evaluation process. Extensive experimental evaluations of 19 mainstream MLLMs are conducted to test their perception, reasoning, and cognition capabilities. The results indicate that models performing well on general benchmarks cannot do well on MME-Finance; for instance, the top-performing open-source and closed-source models obtain 65.69 (Qwen2VL-72B) and 63.18 (GPT-4o), respectively. Their performance is particularly poor in categories most relevant to finance, such as candlestick charts and technical indicator charts. In addition, we propose a Chinese version, which helps compare performance of MLLMs under a Chinese context.
Dialogue State Tracking with Multi-Level Fusion of Predicted Dialogue States and Conversations
Jul 12, 2021
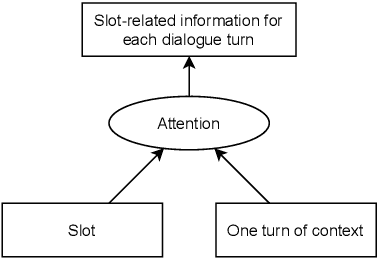
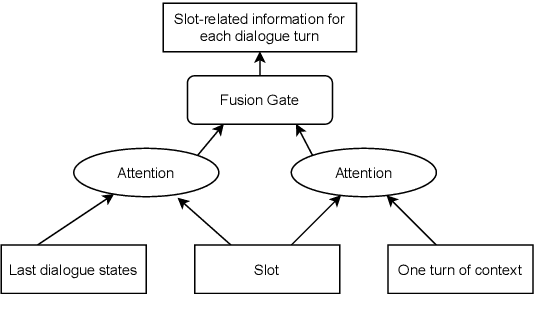
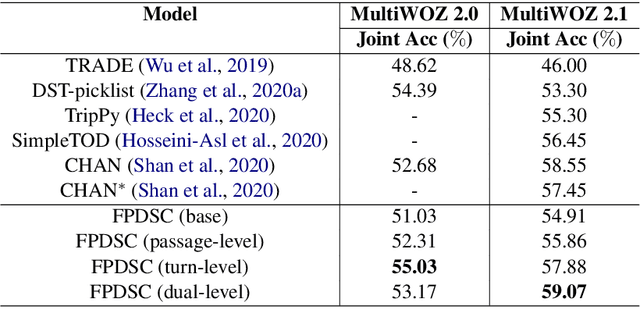
Most recently proposed approaches in dialogue state tracking (DST) leverage the context and the last dialogue states to track current dialogue states, which are often slot-value pairs. Although the context contains the complete dialogue information, the information is usually indirect and even requires reasoning to obtain. The information in the lastly predicted dialogue states is direct, but when there is a prediction error, the dialogue information from this source will be incomplete or erroneous. In this paper, we propose the Dialogue State Tracking with Multi-Level Fusion of Predicted Dialogue States and Conversations network (FPDSC). This model extracts information of each dialogue turn by modeling interactions among each turn utterance, the corresponding last dialogue states, and dialogue slots. Then the representation of each dialogue turn is aggregated by a hierarchical structure to form the passage information, which is utilized in the current turn of DST. Experimental results validate the effectiveness of the fusion network with 55.03% and 59.07% joint accuracy on MultiWOZ 2.0 and MultiWOZ 2.1 datasets, which reaches the state-of-the-art performance. Furthermore, we conduct the deleted-value and related-slot experiments on MultiWOZ 2.1 to evaluate our model.
A Knowledge-Grounded Dialog System Based on Pre-Trained Language Models
Jun 28, 2021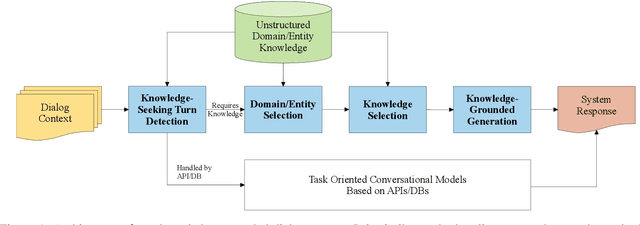


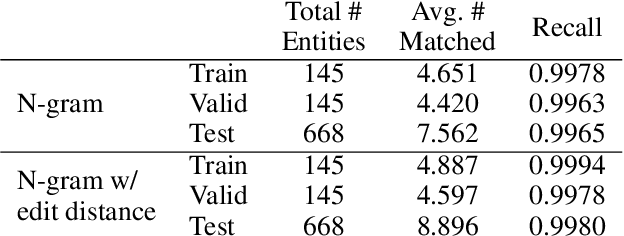
We present a knowledge-grounded dialog system developed for the ninth Dialog System Technology Challenge (DSTC9) Track 1 - Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access. We leverage transfer learning with existing language models to accomplish the tasks in this challenge track. Specifically, we divided the task into four sub-tasks and fine-tuned several Transformer models on each of the sub-tasks. We made additional changes that yielded gains in both performance and efficiency, including the combination of the model with traditional entity-matching techniques, and the addition of a pointer network to the output layer of the language model.
Efficient Dialogue State Tracking by Masked Hierarchical Transformer
Jun 28, 2021
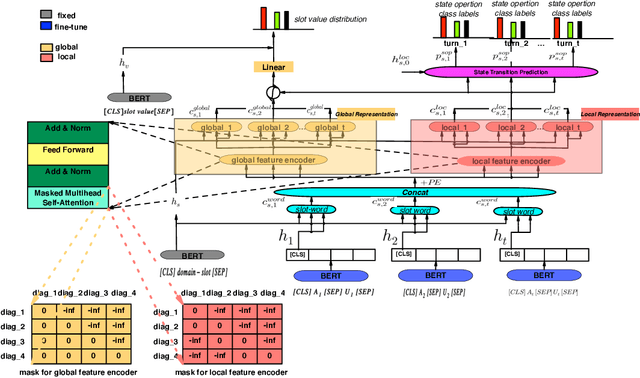
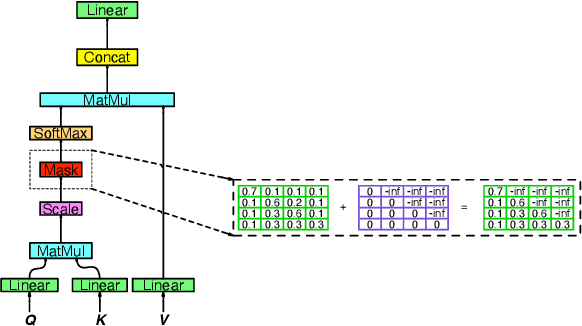
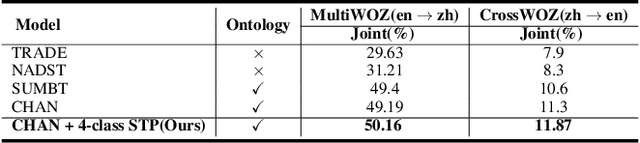
This paper describes our approach to DSTC 9 Track 2: Cross-lingual Multi-domain Dialog State Tracking, the task goal is to build a Cross-lingual dialog state tracker with a training set in rich resource language and a testing set in low resource language. We formulate a method for joint learning of slot operation classification task and state tracking task respectively. Furthermore, we design a novel mask mechanism for fusing contextual information about dialogue, the results show the proposed model achieves excellent performance on DSTC Challenge II with a joint accuracy of 62.37% and 23.96% in MultiWOZ(en - zh) dataset and CrossWOZ(zh - en) dataset, respectively.