 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniEarth: A Benchmark for Evaluating Vision-Language Models in Geospatial Tasks
Mar 10, 2026Vision-Language Models (VLMs) have demonstrated effective perception and reasoning capabilities on general-domain tasks, leading to growing interest in their application to Earth observation. However, a systematic benchmark for comprehensively evaluating remote sensing vision-language models (RSVLMs) remains lacking. To address this gap, we introduce OmniEarth, a benchmark for evaluating RSVLMs under realistic Earth observation scenarios. OmniEarth organizes tasks along three capability dimensions: perception, reasoning, and robustness. It defines 28 fine-grained tasks covering multi-source sensing data and diverse geospatial contexts. The benchmark supports two task formulations: multiple-choice VQA and open-ended VQA. The latter includes pure text outputs for captioning tasks, bounding box outputs for visual grounding tasks, and mask outputs for segmentation tasks. To reduce linguistic bias and examine whether model predictions rely on visual evidence, OmniEarth adopts a blind test protocol and a quintuple semantic consistency requirement. OmniEarth includes 9,275 carefully quality-controlled images, including proprietary satellite imagery from Jilin-1 (JL-1), along with 44,210 manually verified instructions. We conduct a systematic evaluation of contrastive learning-based models, general closed-source and open-source VLMs, as well as RSVLMs. Results show that existing VLMs still struggle with geospatially complex tasks, revealing clear gaps that need to be addressed for remote sensing applications. OmniEarth is publicly available at https://huggingface.co/datasets/sjeeudd/OmniEarth.
DIA-CLIP: a universal representation learning framework for zero-shot DIA proteomics
Feb 02, 2026Data-independent acquisition mass spectrometry (DIA-MS) has established itself as a cornerstone of proteomic profiling and large-scale systems biology, offering unparalleled depth and reproducibility. Current DIA analysis frameworks, however, require semi-supervised training within each run for peptide-spectrum match (PSM) re-scoring. This approach is prone to overfitting and lacks generalizability across diverse species and experimental conditions. Here, we present DIA-CLIP, a pre-trained model shifting the DIA analysis paradigm from semi-supervised training to universal cross-modal representation learning. By integrating dual-encoder contrastive learning framework with encoder-decoder architecture, DIA-CLIP establishes a unified cross-modal representation for peptides and corresponding spectral features, achieving high-precision, zero-shot PSM inference. Extensive evaluations across diverse benchmarks demonstrate that DIA-CLIP consistently outperforms state-of-the-art tools, yielding up to a 45% increase in protein identification while achieving a 12% reduction in entrapment identifications. Moreover, DIA-CLIP holds immense potential for diverse practical applications, such as single-cell and spatial proteomics, where its enhanced identification depth facilitates the discovery of novel biomarkers and the elucidates of intricate cellular mechanisms.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
A Knowledge-Grounded Dialog System Based on Pre-Trained Language Models
Jun 28, 2021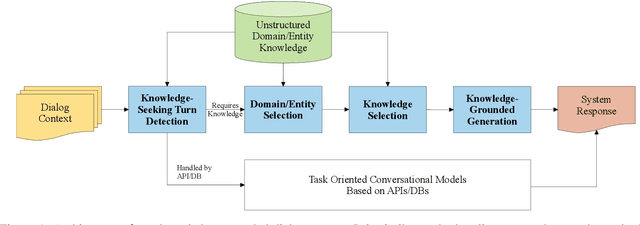


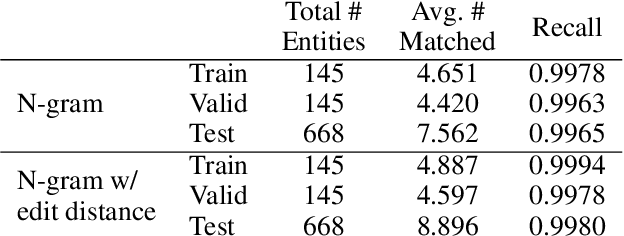
We present a knowledge-grounded dialog system developed for the ninth Dialog System Technology Challenge (DSTC9) Track 1 - Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access. We leverage transfer learning with existing language models to accomplish the tasks in this challenge track. Specifically, we divided the task into four sub-tasks and fine-tuned several Transformer models on each of the sub-tasks. We made additional changes that yielded gains in both performance and efficiency, including the combination of the model with traditional entity-matching techniques, and the addition of a pointer network to the output layer of the language model.