 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI scientists produce results without reasoning scientifically
Apr 20, 2026Large language model (LLM)-based systems are increasingly deployed to conduct scientific research autonomously, yet whether their reasoning adheres to the epistemic norms that make scientific inquiry self-correcting is poorly understood. Here, we evaluate LLM-based scientific agents across eight domains, spanning workflow execution to hypothesis-driven inquiry, through more than 25,000 agent runs and two complementary lenses: (i) a systematic performance analysis that decomposes the contributions of the base model and the agent scaffold, and (ii) a behavioral analysis of the epistemological structure of agent reasoning. We observe that the base model is the primary determinant of both performance and behavior, accounting for 41.4% of explained variance versus 1.5% for the scaffold. Across all configurations, evidence is ignored in 68% of traces, refutation-driven belief revision occurs in 26%, and convergent multi-test evidence is rare. The same reasoning pattern appears whether the agent executes a computational workflow or conducts hypothesis-driven inquiry. They persist even when agents receive near-complete successful reasoning trajectories as context, and the resulting unreliability compounds across repeated trials in epistemically demanding domains. Thus, current LLM-based agents execute scientific workflows but do not exhibit the epistemic patterns that characterize scientific reasoning. Outcome-based evaluation cannot detect these failures, and scaffold engineering alone cannot repair them. Until reasoning itself becomes a training target, the scientific knowledge produced by such agents cannot be justified by the process that generated it.
Semantic Content Determines Algorithmic Performance
Jan 29, 2026Counting should not depend on what is being counted; more generally, any algorithm's behavior should be invariant to the semantic content of its arguments. We introduce WhatCounts to test this property in isolation. Unlike prior work that conflates semantic sensitivity with reasoning complexity or prompt variation, WhatCounts is atomic: count items in an unambiguous, delimited list with no duplicates, distractors, or reasoning steps for different semantic types. Frontier LLMs show over 40% accuracy variation depending solely on what is being counted - cities versus chemicals, names versus symbols. Controlled ablations rule out confounds. The gap is semantic, and it shifts unpredictably with small amounts of unrelated fine-tuning. LLMs do not implement algorithms; they approximate them, and the approximation is argument-dependent. As we show with an agentic example, this has implications beyond counting: any LLM function may carry hidden dependencies on the meaning of its inputs.
General purpose models for the chemical sciences
Jul 10, 2025



Data-driven techniques have a large potential to transform and accelerate the chemical sciences. However, chemical sciences also pose the unique challenge of very diverse, small, fuzzy datasets that are difficult to leverage in conventional machine learning approaches completely. A new class of models, general-purpose models (GPMs) such as large language models, have shown the ability to solve tasks they have not been directly trained on, and to flexibly operate with low amounts of data in different formats. In this review, we discuss fundamental building principles of GPMs and review recent applications of those models in the chemical sciences across the entire scientific process. While many of these applications are still in the prototype phase, we expect that the increasing interest in GPMs will make many of them mature in the coming years.
ChemPile: A 250GB Diverse and Curated Dataset for Chemical Foundation Models
May 18, 2025



Foundation models have shown remarkable success across scientific domains, yet their impact in chemistry remains limited due to the absence of diverse, large-scale, high-quality datasets that reflect the field's multifaceted nature. We present the ChemPile, an open dataset containing over 75 billion tokens of curated chemical data, specifically built for training and evaluating general-purpose models in the chemical sciences. The dataset mirrors the human learning journey through chemistry -- from educational foundations to specialized expertise -- spanning multiple modalities and content types including structured data in diverse chemical representations (SMILES, SELFIES, IUPAC names, InChI, molecular renderings), scientific and educational text, executable code, and chemical images. ChemPile integrates foundational knowledge (textbooks, lecture notes), specialized expertise (scientific articles and language-interfaced data), visual understanding (molecular structures, diagrams), and advanced reasoning (problem-solving traces and code) -- mirroring how human chemists develop expertise through diverse learning materials and experiences. Constructed through hundreds of hours of expert curation, the ChemPile captures both foundational concepts and domain-specific complexity. We provide standardized training, validation, and test splits, enabling robust benchmarking. ChemPile is openly released via HuggingFace with a consistent API, permissive license, and detailed documentation. We hope the ChemPile will serve as a catalyst for chemical AI, enabling the development of the next generation of chemical foundation models.
Lessons from the trenches on evaluating machine-learning systems in materials science
Mar 13, 2025Measurements are fundamental to knowledge creation in science, enabling consistent sharing of findings and serving as the foundation for scientific discovery. As machine learning systems increasingly transform scientific fields, the question of how to effectively evaluate these systems becomes crucial for ensuring reliable progress. In this review, we examine the current state and future directions of evaluation frameworks for machine learning in science. We organize the review around a broadly applicable framework for evaluating machine learning systems through the lens of statistical measurement theory, using materials science as our primary context for examples and case studies. We identify key challenges common across machine learning evaluation such as construct validity, data quality issues, metric design limitations, and benchmark maintenance problems that can lead to phantom progress when evaluation frameworks fail to capture real-world performance needs. By examining both traditional benchmarks and emerging evaluation approaches, we demonstrate how evaluation choices fundamentally shape not only our measurements but also research priorities and scientific progress. These findings reveal the critical need for transparency in evaluation design and reporting, leading us to propose evaluation cards as a structured approach to documenting measurement choices and limitations. Our work highlights the importance of developing a more diverse toolbox of evaluation techniques for machine learning in materials science, while offering insights that can inform evaluation practices in other scientific domains where similar challenges exist.
Probing the limitations of multimodal language models for chemistry and materials research
Nov 25, 2024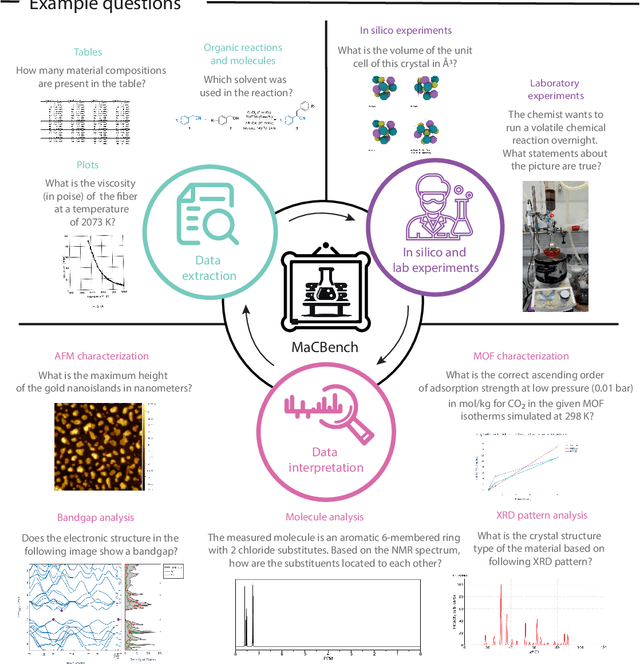
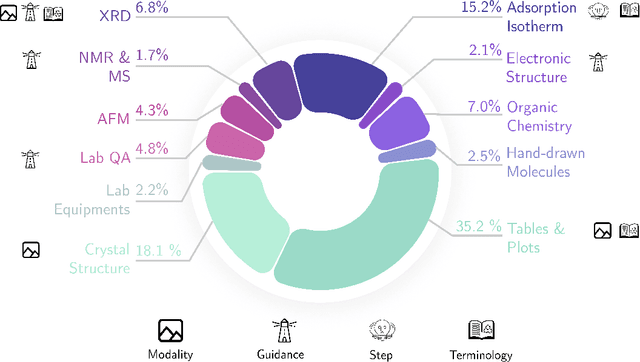
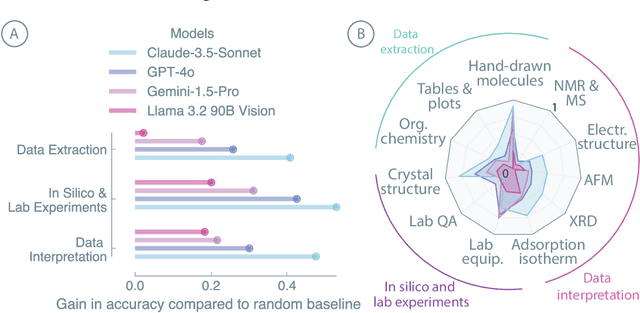
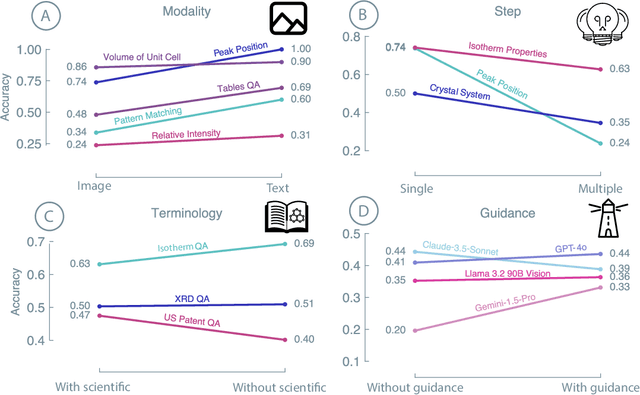
Recent advancements in artificial intelligence have sparked interest in scientific assistants that could support researchers across the full spectrum of scientific workflows, from literature review to experimental design and data analysis. A key capability for such systems is the ability to process and reason about scientific information in both visual and textual forms - from interpreting spectroscopic data to understanding laboratory setups. Here, we introduce MaCBench, a comprehensive benchmark for evaluating how vision-language models handle real-world chemistry and materials science tasks across three core aspects: data extraction, experimental understanding, and results interpretation. Through a systematic evaluation of leading models, we find that while these systems show promising capabilities in basic perception tasks - achieving near-perfect performance in equipment identification and standardized data extraction - they exhibit fundamental limitations in spatial reasoning, cross-modal information synthesis, and multi-step logical inference. Our insights have important implications beyond chemistry and materials science, suggesting that developing reliable multimodal AI scientific assistants may require advances in curating suitable training data and approaches to training those models.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
MatText: Do Language Models Need More than Text & Scale for Materials Modeling?
Jun 25, 2024



Effectively representing materials as text has the potential to leverage the vast advancements of large language models (LLMs) for discovering new materials. While LLMs have shown remarkable success in various domains, their application to materials science remains underexplored. A fundamental challenge is the lack of understanding of how to best utilize text-based representations for materials modeling. This challenge is further compounded by the absence of a comprehensive benchmark to rigorously evaluate the capabilities and limitations of these text representations in capturing the complexity of material systems. To address this gap, we propose MatText, a suite of benchmarking tools and datasets designed to systematically evaluate the performance of language models in modeling materials. MatText encompasses nine distinct text-based representations for material systems, including several novel representations. Each representation incorporates unique inductive biases that capture relevant information and integrate prior physical knowledge about materials. Additionally, MatText provides essential tools for training and benchmarking the performance of language models in the context of materials science. These tools include standardized dataset splits for each representation, probes for evaluating sensitivity to geometric factors, and tools for seamlessly converting crystal structures into text. Using MatText, we conduct an extensive analysis of the capabilities of language models in modeling materials. Our findings reveal that current language models consistently struggle to capture the geometric information crucial for materials modeling across all representations. Instead, these models tend to leverage local information, which is emphasized in some of our novel representations. Our analysis underscores MatText's ability to reveal shortcomings of text-based methods for materials design.
Are large language models superhuman chemists?
Apr 01, 2024Large language models (LLMs) have gained widespread interest due to their ability to process human language and perform tasks on which they have not been explicitly trained. This is relevant for the chemical sciences, which face the problem of small and diverse datasets that are frequently in the form of text. LLMs have shown promise in addressing these issues and are increasingly being harnessed to predict chemical properties, optimize reactions, and even design and conduct experiments autonomously. However, we still have only a very limited systematic understanding of the chemical reasoning capabilities of LLMs, which would be required to improve models and mitigate potential harms. Here, we introduce "ChemBench," an automated framework designed to rigorously evaluate the chemical knowledge and reasoning abilities of state-of-the-art LLMs against the expertise of human chemists. We curated more than 7,000 question-answer pairs for a wide array of subfields of the chemical sciences, evaluated leading open and closed-source LLMs, and found that the best models outperformed the best human chemists in our study on average. The models, however, struggle with some chemical reasoning tasks that are easy for human experts and provide overconfident, misleading predictions, such as about chemicals' safety profiles. These findings underscore the dual reality that, although LLMs demonstrate remarkable proficiency in chemical tasks, further research is critical to enhancing their safety and utility in chemical sciences. Our findings also indicate a need for adaptations to chemistry curricula and highlight the importance of continuing to develop evaluation frameworks to improve safe and useful LLMs.