 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstroLLaVA: towards the unification of astronomical data and natural language
Apr 11, 2025
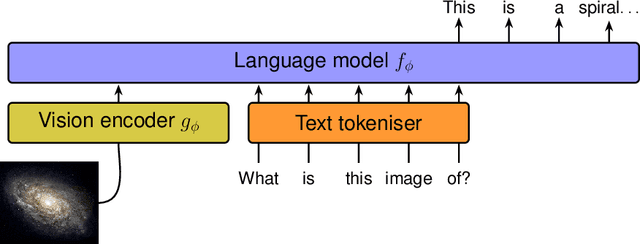


We present AstroLLaVA, a vision language model for astronomy that enables interaction with astronomical imagery through natural dialogue. By fine-tuning the LLaVA model on a diverse dataset of $\sim$30k images with captions and question-answer pairs sourced from NASA's `Astronomy Picture of the Day', the European Southern Observatory, and the NASA/ESA Hubble Space Telescope, we create a model capable of answering open-ended questions about astronomical concepts depicted visually. Our two-stage fine-tuning process adapts the model to both image captioning and visual question answering in the astronomy domain. We demonstrate AstroLLaVA's performance on an astronomical visual question answering benchmark and release the model weights, code, and training set to encourage further open source work in this space. Finally, we suggest a roadmap towards general astronomical data alignment with pre-trained language models, and provide an open space for collaboration towards this end for interested researchers.
A Survey on Hypothesis Generation for Scientific Discovery in the Era of Large Language Models
Apr 07, 2025Hypothesis generation is a fundamental step in scientific discovery, yet it is increasingly challenged by information overload and disciplinary fragmentation. Recent advances in Large Language Models (LLMs) have sparked growing interest in their potential to enhance and automate this process. This paper presents a comprehensive survey of hypothesis generation with LLMs by (i) reviewing existing methods, from simple prompting techniques to more complex frameworks, and proposing a taxonomy that categorizes these approaches; (ii) analyzing techniques for improving hypothesis quality, such as novelty boosting and structured reasoning; (iii) providing an overview of evaluation strategies; and (iv) discussing key challenges and future directions, including multimodal integration and human-AI collaboration. Our survey aims to serve as a reference for researchers exploring LLMs for hypothesis generation.
Probing the limitations of multimodal language models for chemistry and materials research
Nov 25, 2024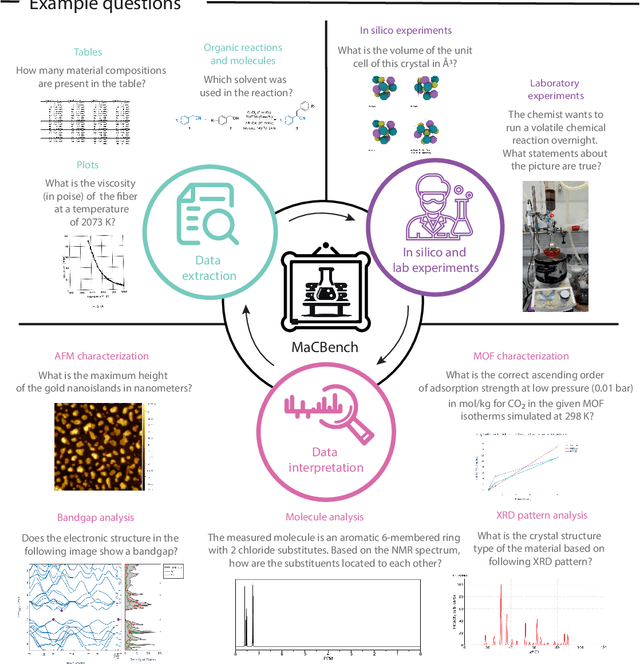
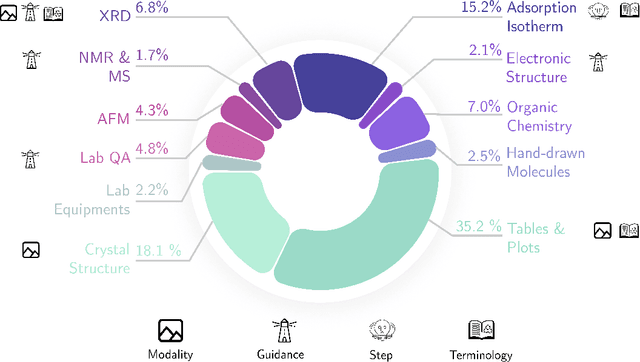
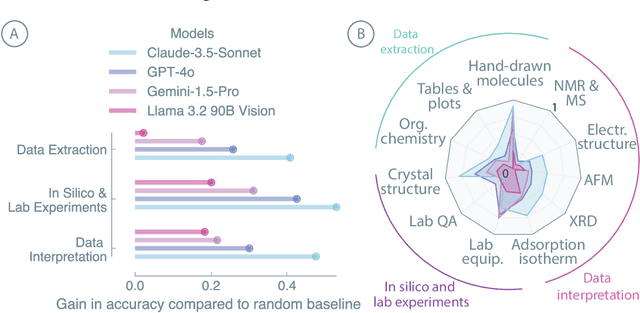
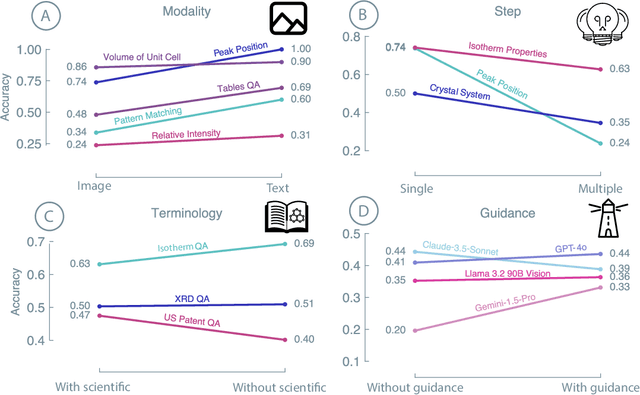
Recent advancements in artificial intelligence have sparked interest in scientific assistants that could support researchers across the full spectrum of scientific workflows, from literature review to experimental design and data analysis. A key capability for such systems is the ability to process and reason about scientific information in both visual and textual forms - from interpreting spectroscopic data to understanding laboratory setups. Here, we introduce MaCBench, a comprehensive benchmark for evaluating how vision-language models handle real-world chemistry and materials science tasks across three core aspects: data extraction, experimental understanding, and results interpretation. Through a systematic evaluation of leading models, we find that while these systems show promising capabilities in basic perception tasks - achieving near-perfect performance in equipment identification and standardized data extraction - they exhibit fundamental limitations in spatial reasoning, cross-modal information synthesis, and multi-step logical inference. Our insights have important implications beyond chemistry and materials science, suggesting that developing reliable multimodal AI scientific assistants may require advances in curating suitable training data and approaches to training those models.
AstroLLaMA: Towards Specialized Foundation Models in Astronomy
Sep 12, 2023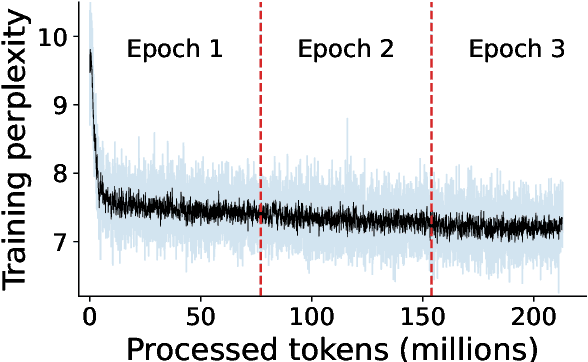

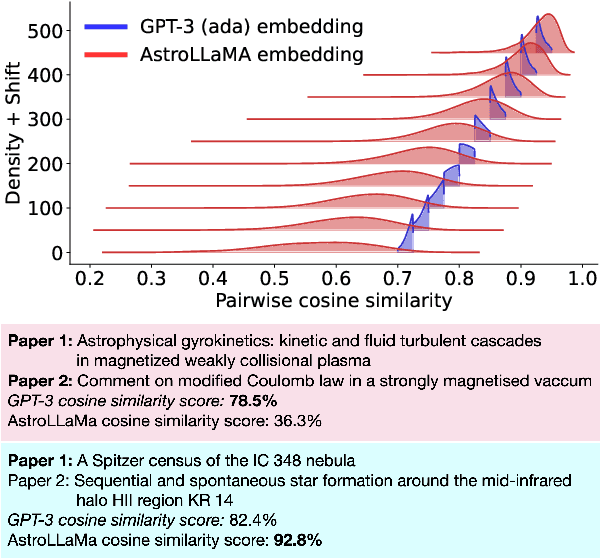
Large language models excel in many human-language tasks but often falter in highly specialized domains like scholarly astronomy. To bridge this gap, we introduce AstroLLaMA, a 7-billion-parameter model fine-tuned from LLaMA-2 using over 300,000 astronomy abstracts from arXiv. Optimized for traditional causal language modeling, AstroLLaMA achieves a 30% lower perplexity than Llama-2, showing marked domain adaptation. Our model generates more insightful and scientifically relevant text completions and embedding extraction than state-of-the-arts foundation models despite having significantly fewer parameters. AstroLLaMA serves as a robust, domain-specific model with broad fine-tuning potential. Its public release aims to spur astronomy-focused research, including automatic paper summarization and conversational agent development.